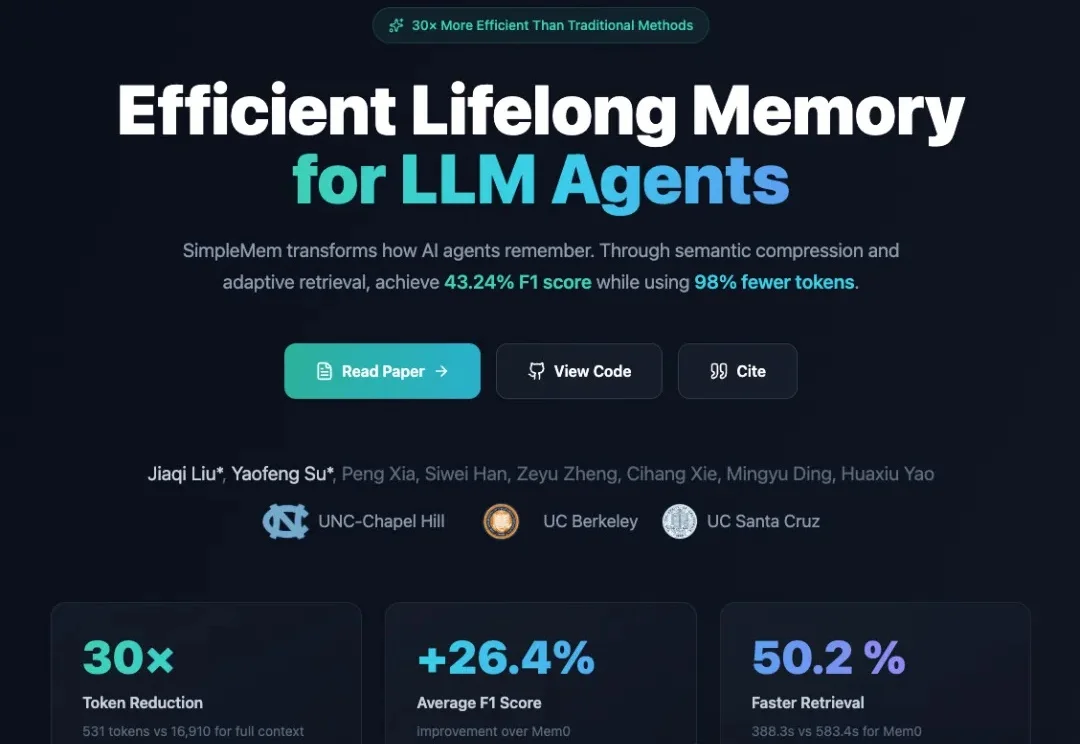
让Agent记住一切是愚蠢的:SimpleMem用「结构化语义压缩」登顶记忆SOTA
让Agent记住一切是愚蠢的:SimpleMem用「结构化语义压缩」登顶记忆SOTA如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
来自主题: AI技术研报
9628 点击 2026-01-15 09:22
 搜索
搜索
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
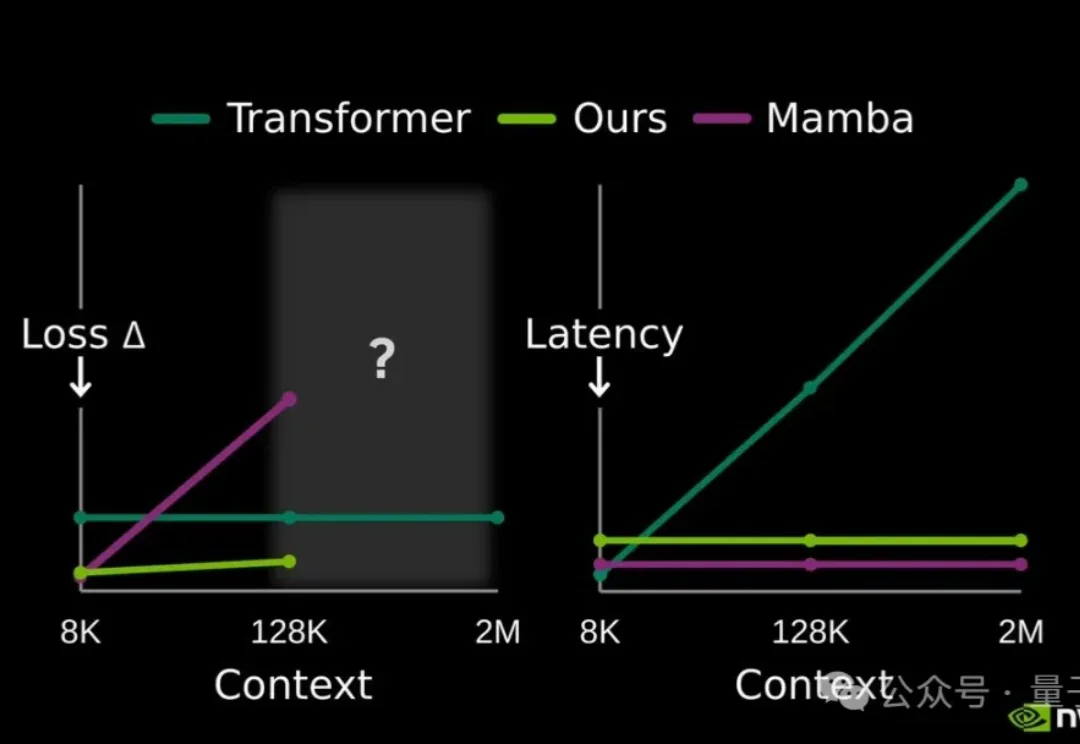
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
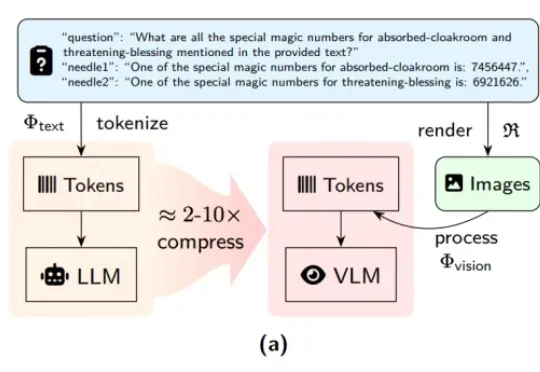
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。
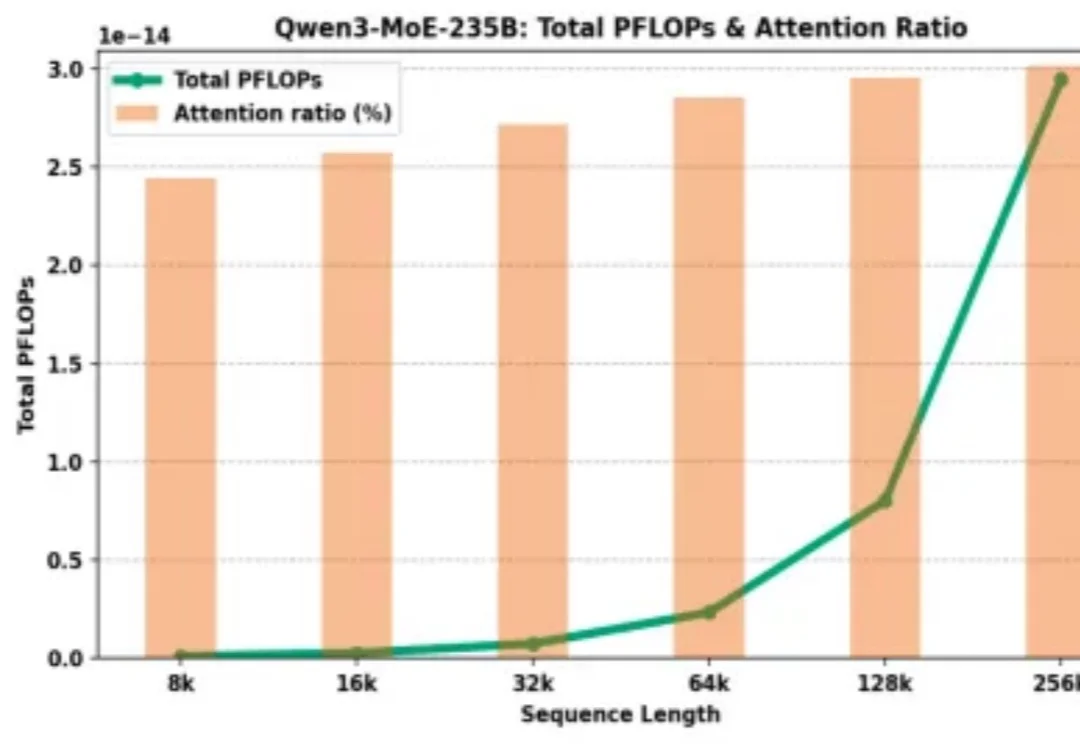
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?

周五凌晨,OpenAI 发布 GPT-5.2-Codex,这是迄今为止最先进的智能体编码模型,专为复杂的实际软件工程而设计。GPT-5.2-Codex 是 GPT-5.2 的升级版本,提高了指令遵循能力、对长远语境的理解能力,它针对 Codex 中的智能体编码进行了进一步优化,包括通过上下文压缩改进长期工作。

从 0 到上线,在OpenAI内部,安卓版 Sora经历的时间只有 28 天,而且期间只用了 2-3 名员工。
压缩即智能,又有新进展!
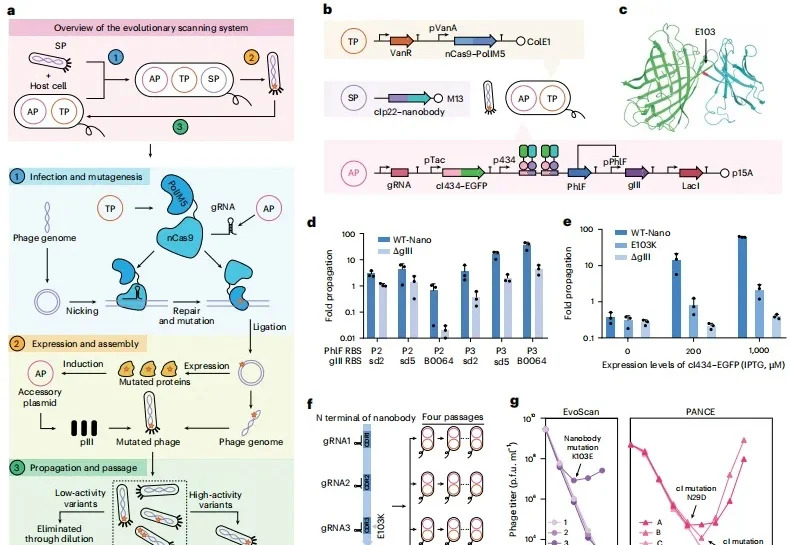
从去年到今年,清华大学教授张数一和团队连着两个冬天做出两个“AI+蛋白质”成果,它们分别是极速压缩与智能重建蛋白质序列空间的 EvoAI,以及能够 24 小时昼夜不停、全自动进化蛋白质的 iAutoEvoLab 工厂。相关论文分别发表于 Nature Methods 和 Nature Chemical Engineering。

Hi,早上好。 我是洛小山,和你聊聊 AI 应用的降本增效。