
智源BGE-VL拍照提问即可精准搜,1/70数据击穿多模态检索天花板!
智源BGE-VL拍照提问即可精准搜,1/70数据击穿多模态检索天花板!智源联手多所顶尖高校发布的多模态向量模型BGE-VL,重塑了AI检索领域的游戏规则。它凭借独创的MegaPairs合成数据技术,在图文检索、组合图像检索等多项任务中,横扫各大基准刷新SOTA。
来自主题: AI技术研报
6281 点击 2025-03-07 10:34
 搜索
搜索
智源联手多所顶尖高校发布的多模态向量模型BGE-VL,重塑了AI检索领域的游戏规则。它凭借独创的MegaPairs合成数据技术,在图文检索、组合图像检索等多项任务中,横扫各大基准刷新SOTA。
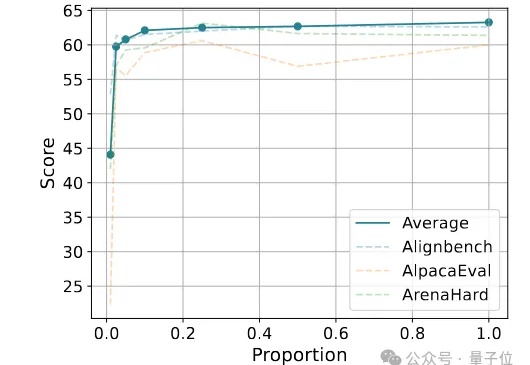
仅使用20K合成数据,就能让Qwen模型能力飙升——

本月,OpenAI科学家就当前LLM的scaling方法论能否实现AGI话题展开深入辩论,认为将来AI至少与人类平分秋色;LLM scaling目前的问题可以通过后训练、强化学习、合成数据、智能体协作等方法得到解决;按现在的趋势估计,明年LLM就能赢得IMO金牌。

我们将讨论的不仅仅是哪个超级大国会胜出,而是哪个国家的AI系统会成为全球基础设施的基石,能够被广泛采用和输出。
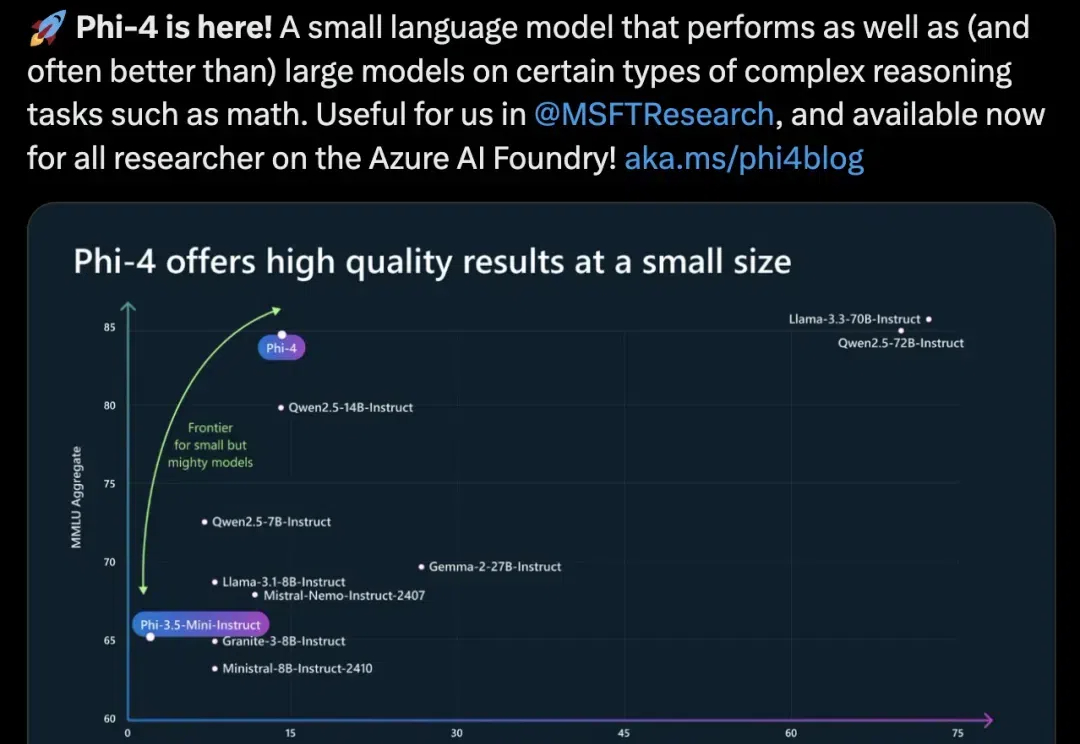
微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。

在探索迈向AGI(通用人工智能)物理世界的路径中,通用机器人被视作关键载体。
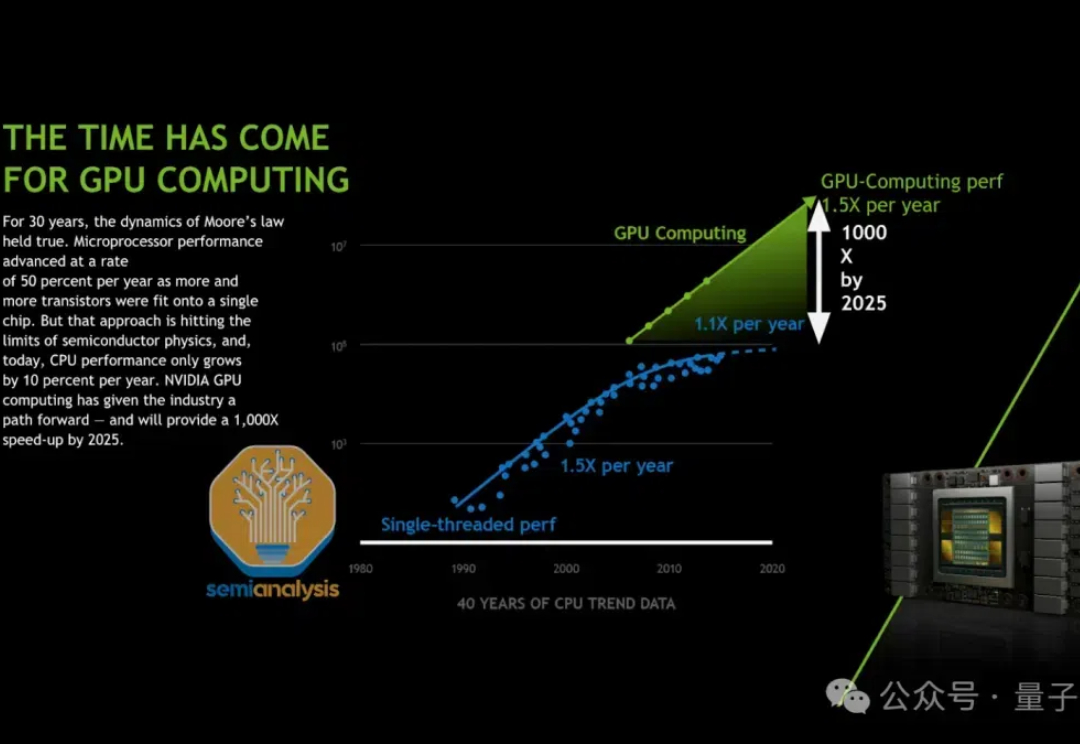
传闻反转了,Claude 3.5 Opus没有训练失败。 只是Anthropic训练好了,暗中压住不公开。 semianalysis分析师爆料,Claude 3.5超大杯被藏起来,只用于内部数据合成以及强化学习奖励建模。 Claude 3.5 Sonnet就是如此训练而来。

随着大语言模型(LLMs)在处理复杂任务中的广泛应用,高质量数据的获取变得尤为关键。为了确保模型能够准确理解并执行用户指令,模型必须依赖大量真实且多样化的数据进行后训练。然而,获取此类数据往往伴随着高昂的成本和数据稀缺性。因此,如何有效生成能够反映现实需求的高质量合成数据,成为了当前亟需解决的核心挑战。

已与多家国内外头部主机厂、Tier1供应商、具身智能公司签约

数学界对AI在数学中应用的看法存在分歧,但年轻一代更支持AI和验证工具。Vlad指出,通过递归自我改进,AI有潜力在数学和其他复杂问题上取得重大突破。随着AI在模式识别和自我改进方面的进步,它可能参与解决大型数学难题,如黎曼猜想。同时,数学家仍将在引导AI方向、规划研究领域和解释结果方面起关键作用。