4o-mini华人领队也离职了,这次不怪小扎
4o-mini华人领队也离职了,这次不怪小扎哦豁,OpenAI奥特曼又痛失一员大将。 Kevin Lu,领导4o-mini发布,并参与o1-mini、o3发布,主要研究强化学习、小模型和合成数据。
来自主题: AI资讯
8197 点击 2025-08-19 11:20
 搜索
搜索
哦豁,OpenAI奥特曼又痛失一员大将。 Kevin Lu,领导4o-mini发布,并参与o1-mini、o3发布,主要研究强化学习、小模型和合成数据。

在万物互联的智能时代,具身智能和空间智能需要的不仅是视觉和语言,还需要突破传统感官限制的能力

基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。

Mercor 所处的赛道是 AI 中一个关键且尚未被充分满足的供需交叉点:下一代 AI 模型对高质量、垂直领域专家级 Human Data 的需求,以及相关人才稀缺所带来的供需不平衡。合成数据无法完全替代 Human Data,尤其是在特定领域知识和复杂判断方面。AI 模型的突破性进展高度依赖于垂直领域专家的“人类智能输入”。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!
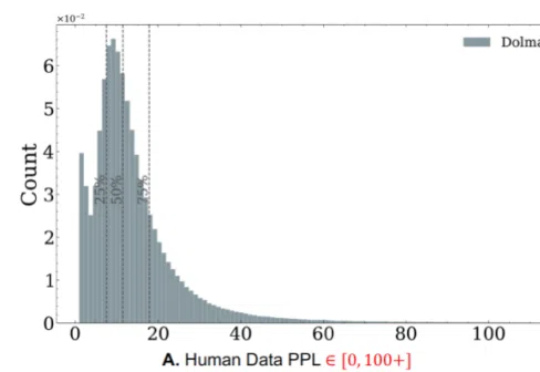
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。

近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,

具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
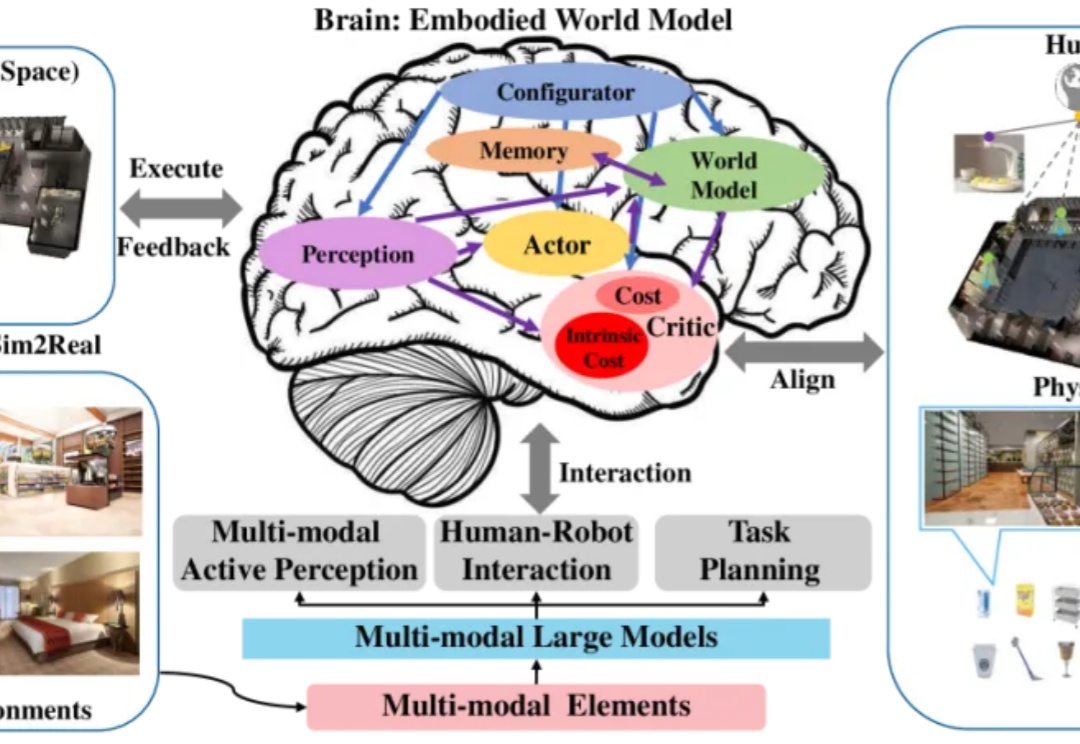
本文主要描述了具身合成数据两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。参考自动驾驶的成功经验,前者模态转换链路过长导致误差累积,'直接合成3D数据'理论上有信息效率优势,但需要克服“常识欠缺”等挑战。