
让龙虾看懂屏幕!谷歌多模态新成果,文本图像视频音频进同一空间
让龙虾看懂屏幕!谷歌多模态新成果,文本图像视频音频进同一空间刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2。这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。
来自主题: AI资讯
7398 点击 2026-03-11 16:59
 搜索
搜索
刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2。这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。
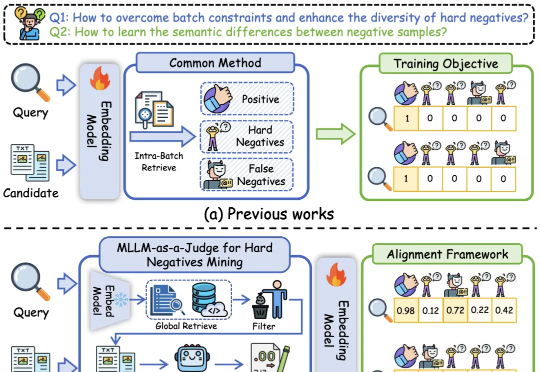
基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。

MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。