ICCV 2025 | 打造通用工具智能体的基石:北大提出ToolVQA数据集,引领多模态多步推理VQA新范式
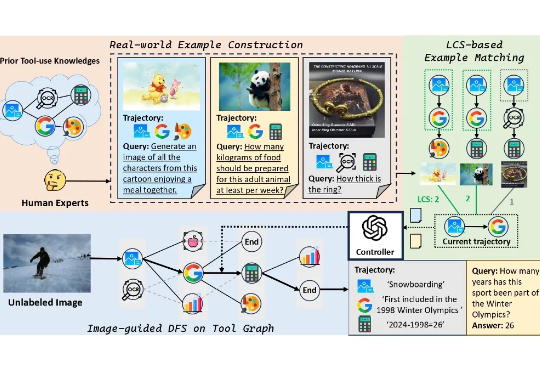
ICCV 2025 | 打造通用工具智能体的基石:北大提出ToolVQA数据集,引领多模态多步推理VQA新范式本文提出了一个旨在提升基础模型工具使用能力的大型多模态数据集 ——ToolVQA。现有研究已在工具增强的视觉问答(VQA)任务中展现出较强性能,但在真实世界中,多模态任务往往涉及多步骤推理与功能多样的工具使用,现有模型在此方面仍存在显著差距。
来自主题: AI技术研报
7933 点击 2025-08-22 16:20