ICML 2026 Spotlight | 直面「模态缺失」挑战:北大彭宇新团队联合福大柯逍团队提出LIMSSR,面向训练阶段不完整观测的精准评价
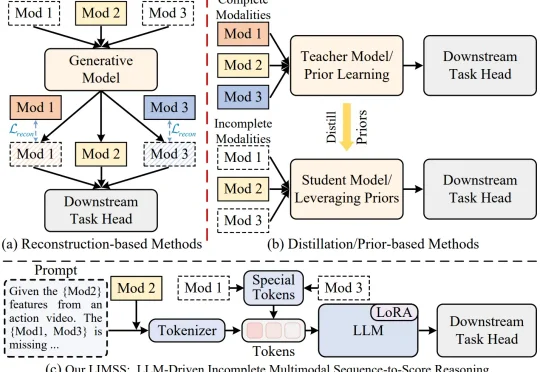
ICML 2026 Spotlight | 直面「模态缺失」挑战:北大彭宇新团队联合福大柯逍团队提出LIMSSR,面向训练阶段不完整观测的精准评价本文是北京大学彭宇新教授团队联合福州大学柯逍教授团队在细粒度多模态动作质量评价领域的最新研究成果,相关论文已被 ICML 2026 接收为 Spotlight,并已开源。真实世界中的多模态数据往往并不完整。在动作质量评价任务中,视频、光流、音频等模态能够从不同角度描述动作执行过程,但在实际采集时,传感器故障、环境噪声、隐私限制等因素都会导致模态缺失。
来自主题: AI技术研报
8334 点击 2026-07-10 10:40