
GDP增长将取决于Tokens数量?微软CEO纳德拉达沃斯对话信息量太大了……
GDP增长将取决于Tokens数量?微软CEO纳德拉达沃斯对话信息量太大了……在2026年的世界经济论坛上,微软 CEO 萨提亚·纳德拉(Satya Nadella)与贝莱德 CEO 拉里·芬克(Larry Fink)进行了一场对话。
来自主题: AI资讯
7346 点击 2026-01-21 10:42
 搜索
搜索
在2026年的世界经济论坛上,微软 CEO 萨提亚·纳德拉(Satya Nadella)与贝莱德 CEO 拉里·芬克(Larry Fink)进行了一场对话。

如果你最近关注了 GitHub,可能会注意到一个有趣的现象: YOLO 的版本号,直接从 11 跳到了 26。

昨天,Claude刚刚被曝要有永久记忆,今天就被开发者抢先一步。一个叫Smart Forking的扩展,让大模型首次拥有「长期记忆」,无需重头解释。开发者圈沸腾了:难以置信,它真的能跑!
今天,据外媒CNBC报道,两位知情人士透露,北京大模型独角兽月之暗面正在进行新一轮融资,这轮融资对其估值为48亿美元(约合人民币334.13亿元),而仅在20天前公布的C轮融资中其估值还是43亿美元(约合人民币299.32亿元)。
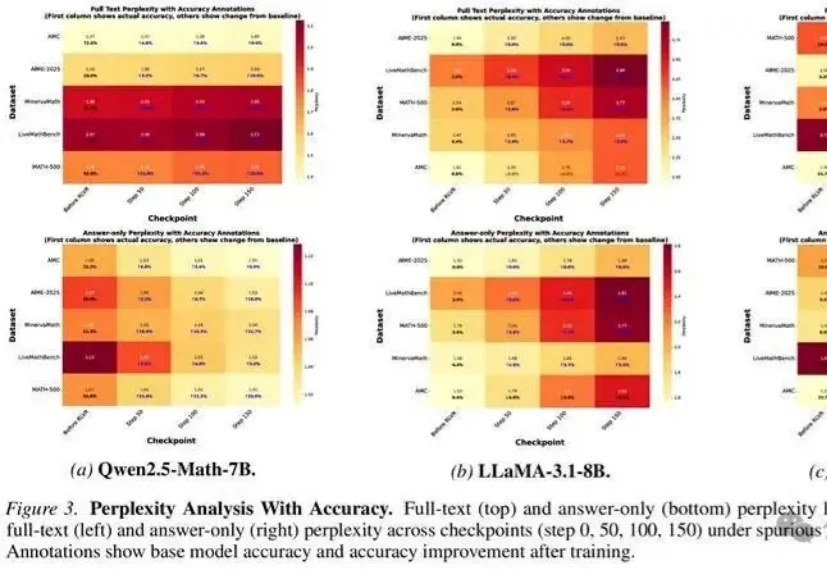
无需真实奖励,哪怕用随机、错误的信号进行训练,大模型准确率也能大幅提升?
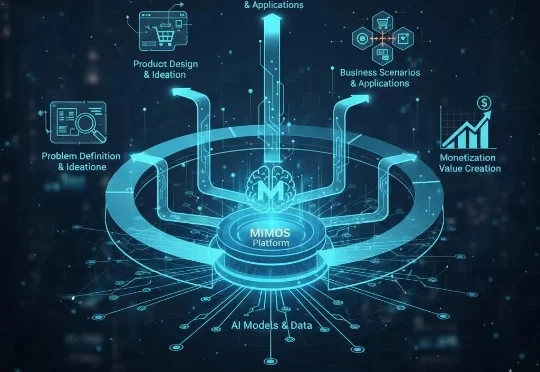
原人工智能大模型公司衔远科技(Frontier.ai)的AI产品负责人 Lyon(李昂),已正式启动新项目 “MIMOS”。与当前市场集中于底层模型研发或垂直应用开发的路径不同,Lyon此次创业将目光投向AI浪潮中更为关键的“产品化”环节,致力于探索连接前沿技术与实际商业价值的系统性方法论。
AI视频生成正从“静态输出”迈入“实时交互”阶段,一场内容创作革命即将到来。 近日,中国儒意宣布以1420万美元对爱诗科技进行战略投资,双方将围绕影视、流媒体、游戏等业务展开深度合作。 爱诗科技作为全

面对《the Big Technology Podcast》抛出的问题,Mistral AI的 CEO Arthur Mensch 表示:大模型肯定会走向商品化,当模型表现越来越接近,那么竞争就不在于模型本身,而在于如何让客户用起来。
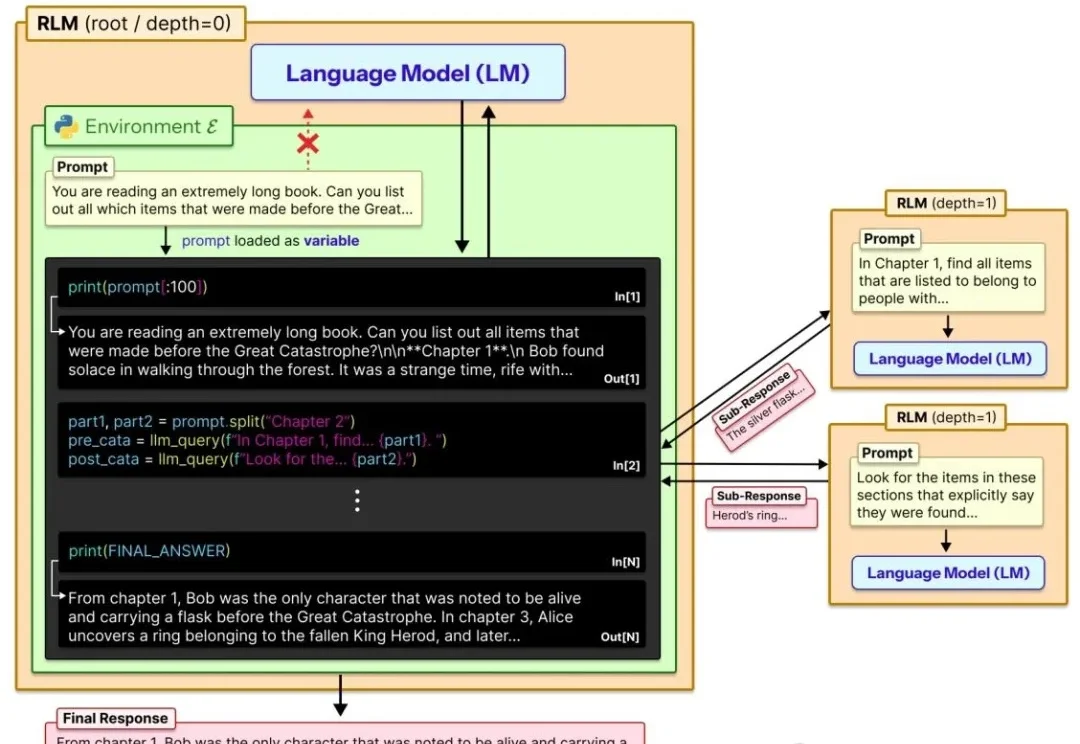
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!

当国内的AI大模型战场正陷入“百模大战”的焦灼,巨头们还在比拼参数规模、长文本处理能力和代码生成率时,一家曾经被打上“在线教育”和“题库工具”深深烙印的公司——作业帮,却在海外市场“悄悄”通过一条意想不到的赛道杀出了重围。