港科大新发现:MoE路由很脆弱!重复token输入阻塞负载均衡 | ICML'26
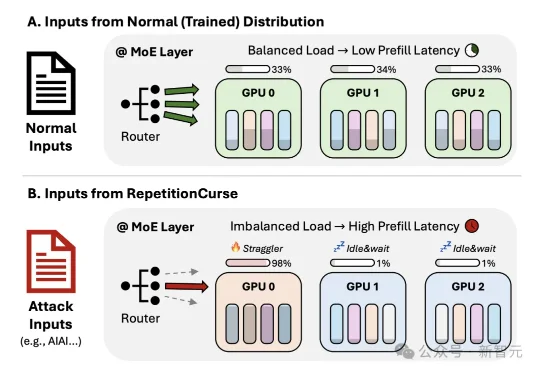
港科大新发现:MoE路由很脆弱!重复token输入阻塞负载均衡 | ICML'26来自港科大的研究团队提出了RepetitionCurse,这是一种针对MoE大模型服务的黑盒压力测试方法。它不需要模型权重,不需要梯度,也不需要知道后端专家如何部署,只利用高度重复的输入模式,就能诱导专家路由把大量token路由到同一小批专家上。
来自主题: AI技术研报
9123 点击 2026-07-19 10:11