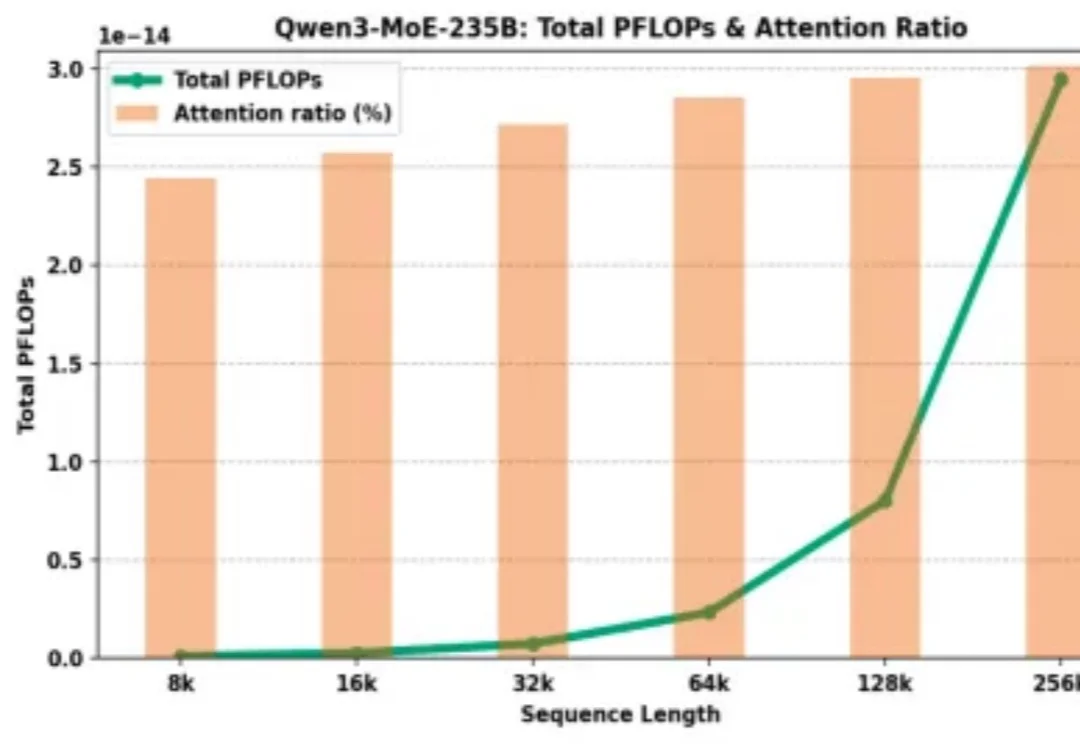
仅需15%全量Attention!「RTPurbo」阿里Qwen3长文本推理5倍压缩方案来了
仅需15%全量Attention!「RTPurbo」阿里Qwen3长文本推理5倍压缩方案来了为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?
来自主题: AI技术研报
8593 点击 2025-12-24 10:07
 搜索
搜索
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?

参数越小,智商越高?Gemini 3 Flash用百万级长上下文、白菜价成本,把自家大哥Pro按在地上摩擦。谷歌到底掏出了什么黑魔法,让整个大模型圈开始怀疑人生?
来猜一下,AI时代,医生最哭笑不得的是什么?

生成式AI狂奔三年,2025迎来架构创新的大年,三条脉络交织演进,伴随着Scaling law(规模定律)遇到天花板的争议,开始定义AI进化的新范式。

在多智能体系统的想象中,我们常常看到这样一幅图景: 多个 AI 智能体分工协作、彼此配合,像一个高效团队一样攻克复杂任务,展现出超越单体智能的 “集体智慧”。

2025倒计时,新SOTA模型涌现没有放缓迹象。一夜之间,编程SOTA模型易主,而且上线即开源,依然来自中国大模型公司——智谱AI,GLM-4.7。

从大模型智能的“语言世界”迈向具身智能的“物理世界”,仿真正在成为连接落地的底层基础设施。
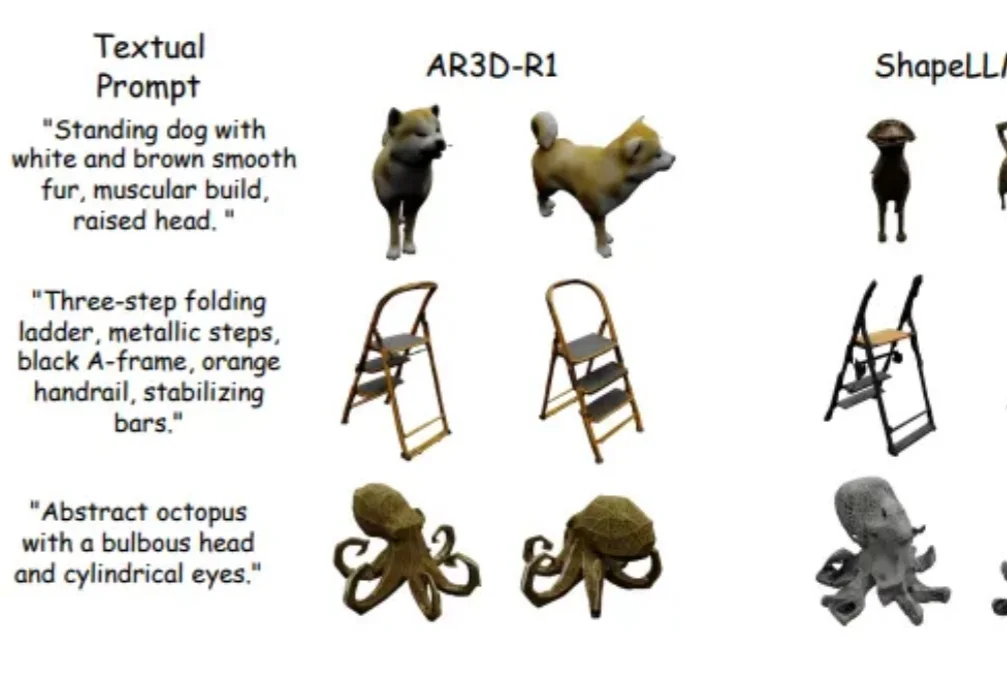
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!

“中国的OpenAI” 是谁?一众媒体和分析机构给出的答案是:智谱。家中国的大模型 AI 创业公司正在港交所冲刺 IPO。在招股说明书中,它明确宣称:“2025年6月,智谱被美国OpenAI 列为全球主要竞争对手。”

这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。