“接力跑”盘活全国算力,PD分离终于破局:延迟砍半、成本直降近40%!
“接力跑”盘活全国算力,PD分离终于破局:延迟砍半、成本直降近40%!在刚刚落幕的2026 WAIC世界人工智能大会上,无问芯穹首次公布了其在大模型推理系统架构中的新突破——跨集群异构推理架构PDD。
来自主题: AI技术研报
5409 点击 2026-07-30 15:57
 搜索
搜索
在刚刚落幕的2026 WAIC世界人工智能大会上,无问芯穹首次公布了其在大模型推理系统架构中的新突破——跨集群异构推理架构PDD。

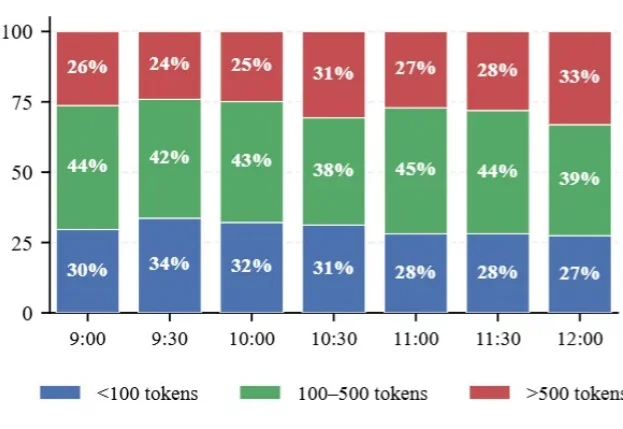
AI基础设施的核心任务,已经从支撑大模型推理,转向支撑海量智能体的规模化运行与高质量Token的持续生产。

近期,DeepSeek发布DSpark让大模型推理效率再次成为行业焦点。
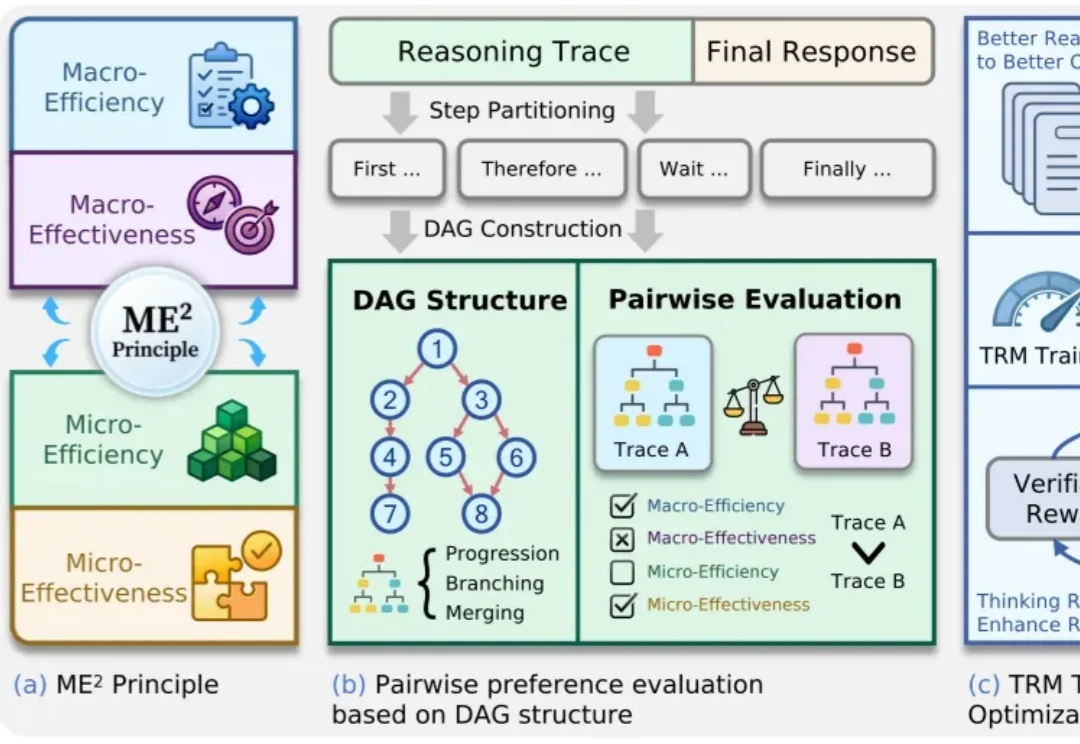
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
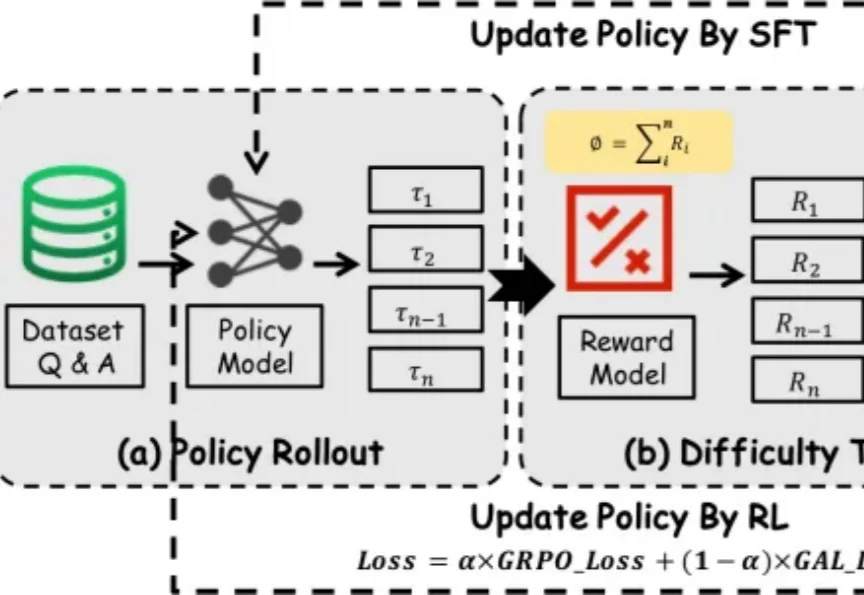
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。

如果你让大模型给林黛玉找一个外国文学里的平替,它能给出令人信服的答案吗?这个脑洞的背后其实是当下人工智能最核心的软肋——“类比推理”能力。

智能体时代的核心是算力。

在 AI 工程界,长文本推理一直是个“富贵病”。

ZP独家获悉,AI芯片及系统架构研发商“上海昉擎科技”于近日完成 Pre-A3 轮融资,新引入投资人国开科创、钧山资本、建发新兴投资、多维资本,多维资本担任本轮融资财务顾问并担任后续融资独家财务顾问。