
刚刚,Anthropic证明:AI开始拥有内省能力
刚刚,Anthropic证明:AI开始拥有内省能力家人们,不知道你有没有试过,在和 AI 聊天时,冷不丁地问一句: “你刚刚在想什么?”
来自主题: AI技术研报
11827 点击 2025-10-30 17:30
 搜索
搜索
家人们,不知道你有没有试过,在和 AI 聊天时,冷不丁地问一句: “你刚刚在想什么?”
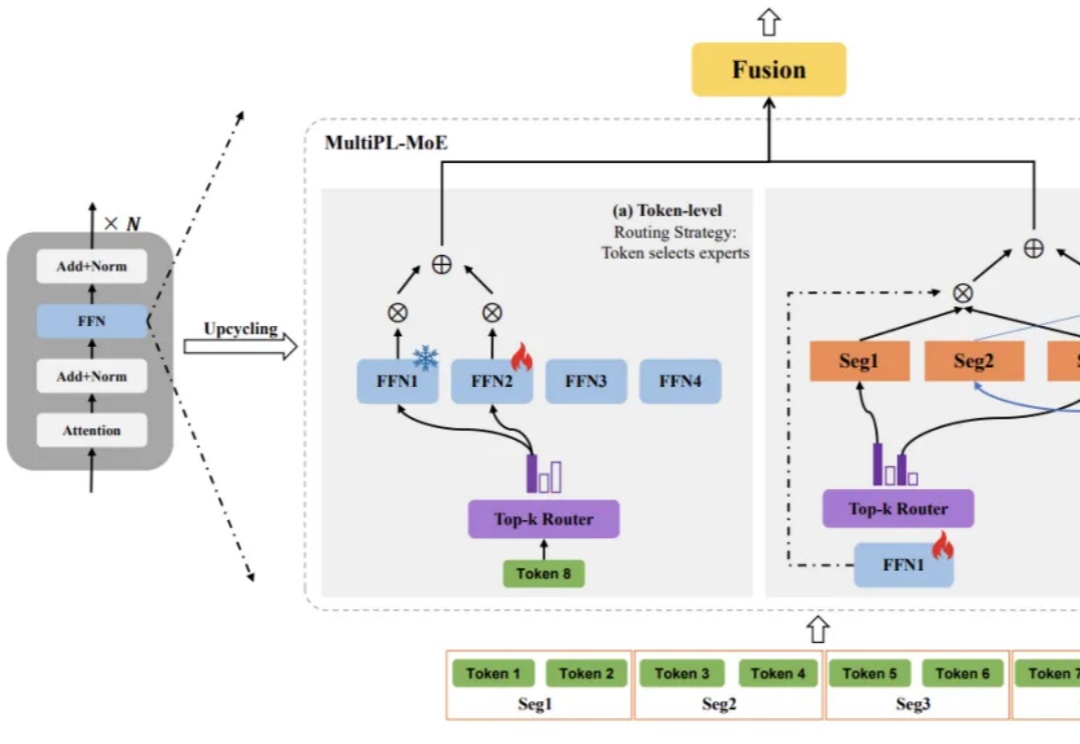
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?
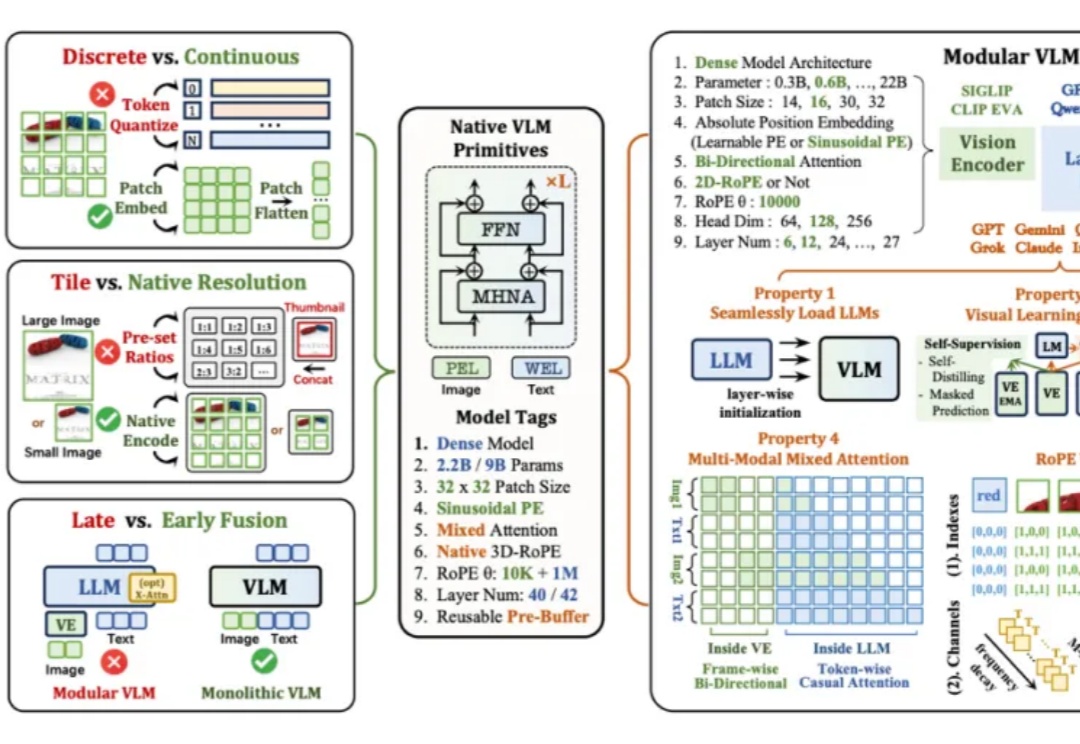
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。

大语言模型(LLMs)推理能力近年来快速提升,但传统方法依赖大量昂贵的人工标注思维链。中国科学院计算所团队提出新框架PARO,通过让模型学习固定推理模式自动生成思维链,只需大模型标注1/10数据就能达到全量人工标注的性能。这种方法特别适合像金融、审计这样规则清晰的领域,为高效推理监督提供了全新思路。
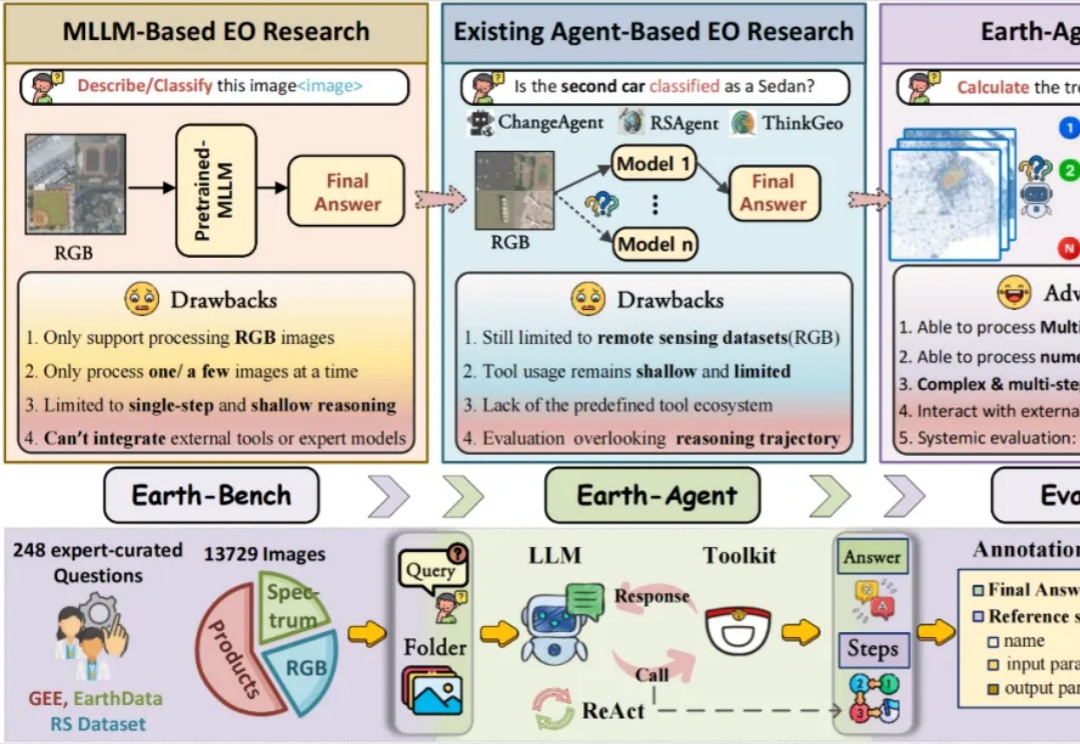
当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」

2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?
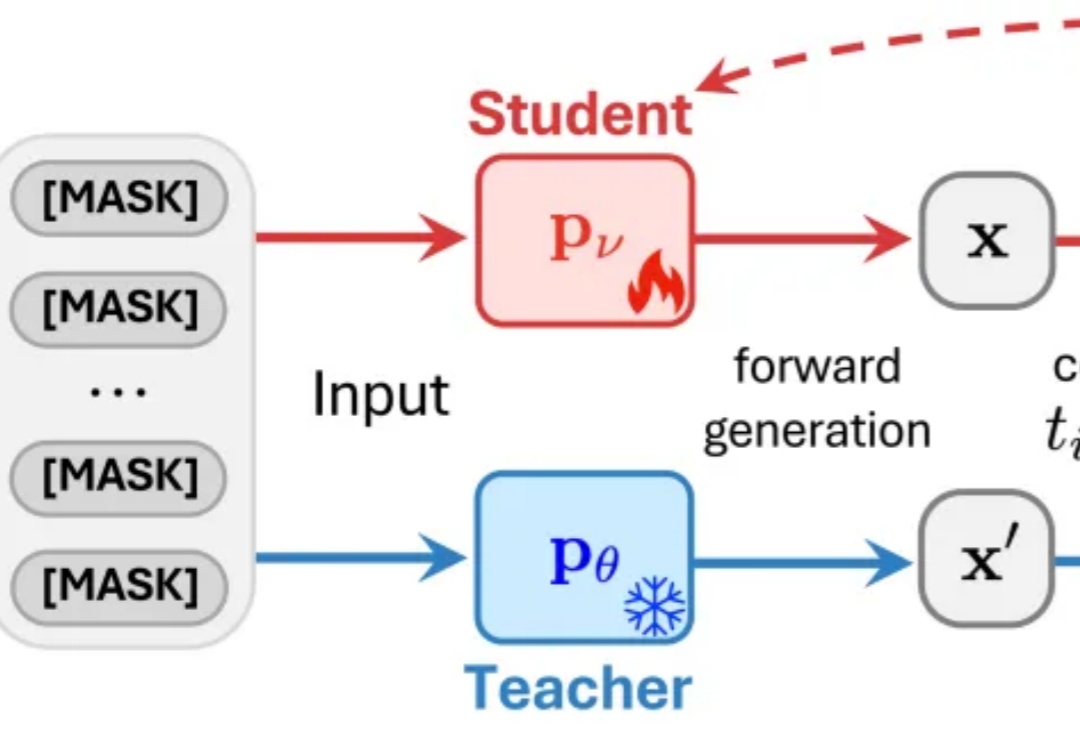
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。
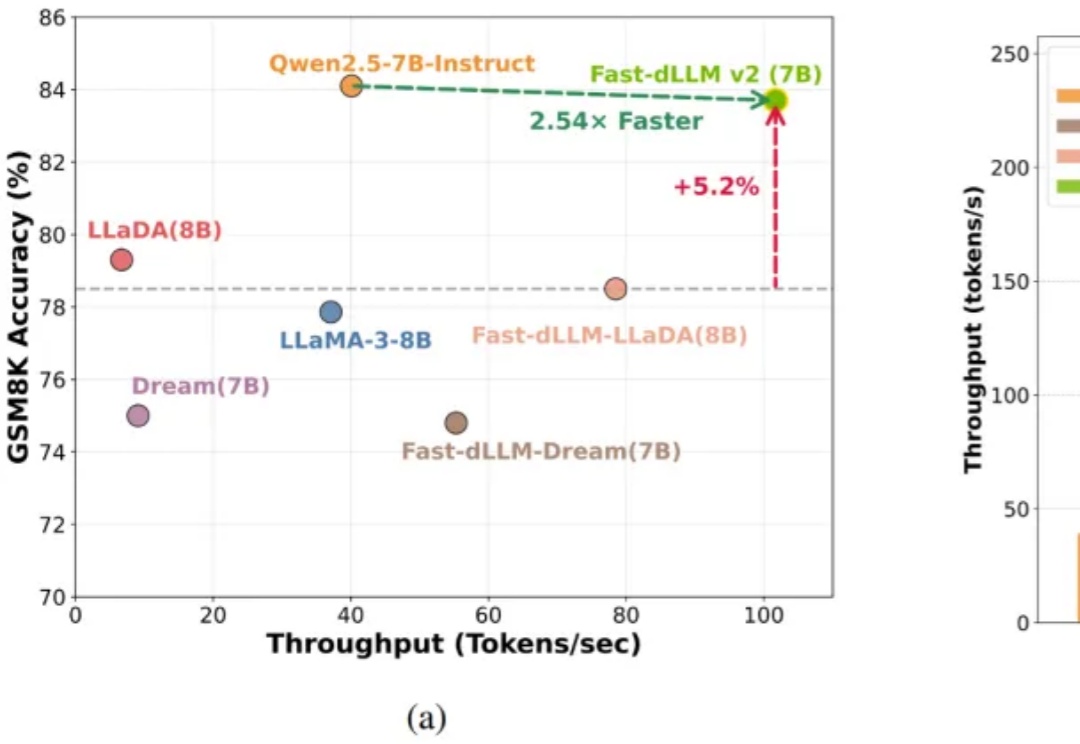
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
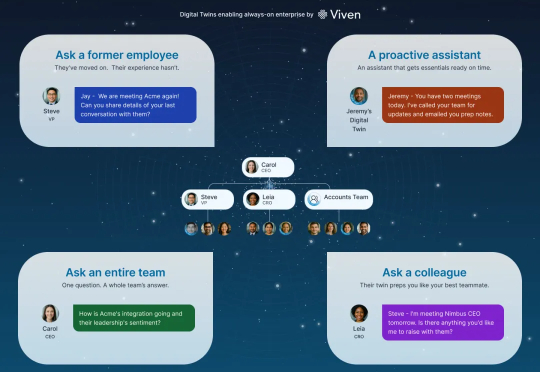
Viven 的核心创新在于,它为每个员工创建了一个个性化的大语言模型,实质上就是一个数字分身。这个分身通过访问员工的内部电子文档,包括邮件、Slack 消息、Google Docs、会议记录等,学习这个人如何思考、如何沟通、拥有什么知识。关键是,这个学习过程是自动进行的,不需要员工做任何额外工作。你只需正常工作,你的数字分身就会不断更新和进化。

香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。