
你敢信?GPT-5的电脑操作水平只比人类低2%了
你敢信?GPT-5的电脑操作水平只比人类低2%了Agent(智能体)是最近一段时间的人工智能热点之一,将大语言模型的能力与工具调用、环境交互和自主规划结合起来,使其能够像虚拟助理一样完成复杂任务。 其中「计算机使用智能
来自主题: AI技术研报
9834 点击 2025-10-05 21:34
 搜索
搜索
Agent(智能体)是最近一段时间的人工智能热点之一,将大语言模型的能力与工具调用、环境交互和自主规划结合起来,使其能够像虚拟助理一样完成复杂任务。 其中「计算机使用智能

当全世界都在狂热追逐大模型时,强化学习之父、图灵奖得主Richard Sutton却直言:大语言模型是「死胡同」。在他看来,真正的智能必须源于经验学习,而不是模仿人类语言的「预测游戏」。这番话无异于当头一棒,让人重新思考:我们追逐的所谓智能,究竟是幻影,还是通向未来的歧路?
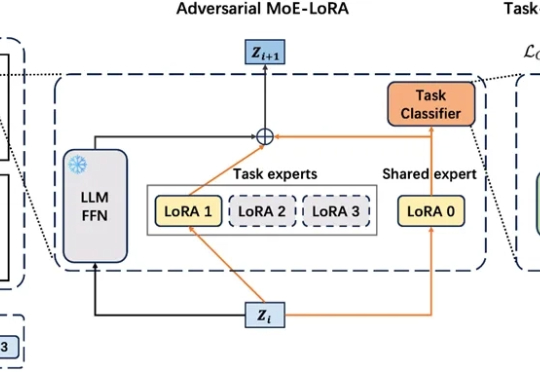
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。
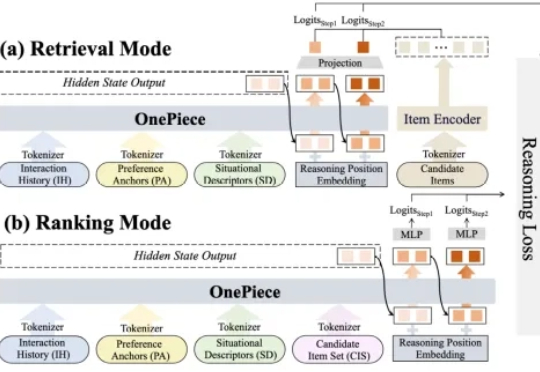
2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。
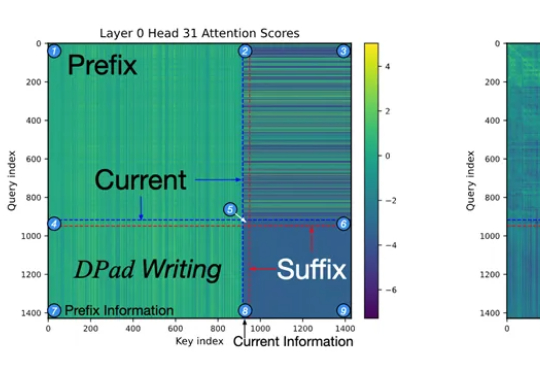
杜克大学团队发现,扩散大语言模型只需关注少量「中奖」token,就能在推理时把速度提升61-97倍,还能让模型更懂格式、更听话。新策略DPad不训练也能零成本挑出关键信息,实现「少算多准」的双赢。
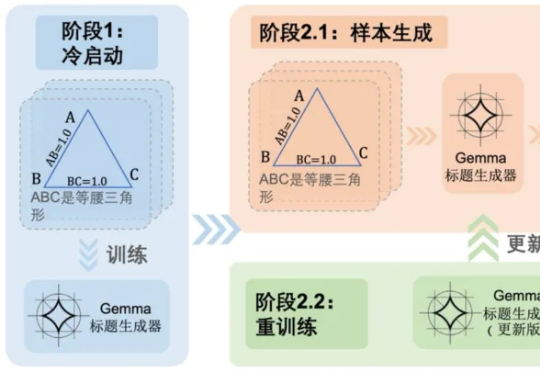
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视

其实大语言模型的“教育”问题也差不多。研究者在训练和使用这些模型时,离不开提示词。这就像一份人生剧本,告诉模型“你是谁?”“你要做什么?”“你能做到哪里?”但问题是,提示词到底应该像家长一样,
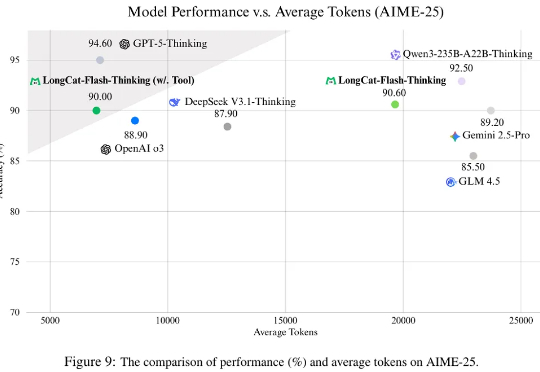
最近,美团在AI开源赛道上在猛踩加速。今天,在开源其首款大语言模型仅仅24天后,美团又开源了其首款自研推理模型LongCat-Flash-Thinking。与其基础模型LongCat-Flash类似,效率也是LongCat-Flash-Thinking的最大特点。美团在技术报告中透露,LongCat-Flash-Thinking在自研的DORA强化学习基础设施完成训练

9 月 22 日下午,联发科推出的新一代旗舰 5G 智能体 AI 芯片 —— 天玑 9500,并展示了一系列新形态端侧的 AI 应用,在公众层面首次推动端侧 AI 从尝鲜到好用。现在,让手机端大语言模型(LLM)处理一段超长的文本,最长支持 128K 字元,它只需要两秒就能总结出会议纪要,AI 还能自动修改你的错别字。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。