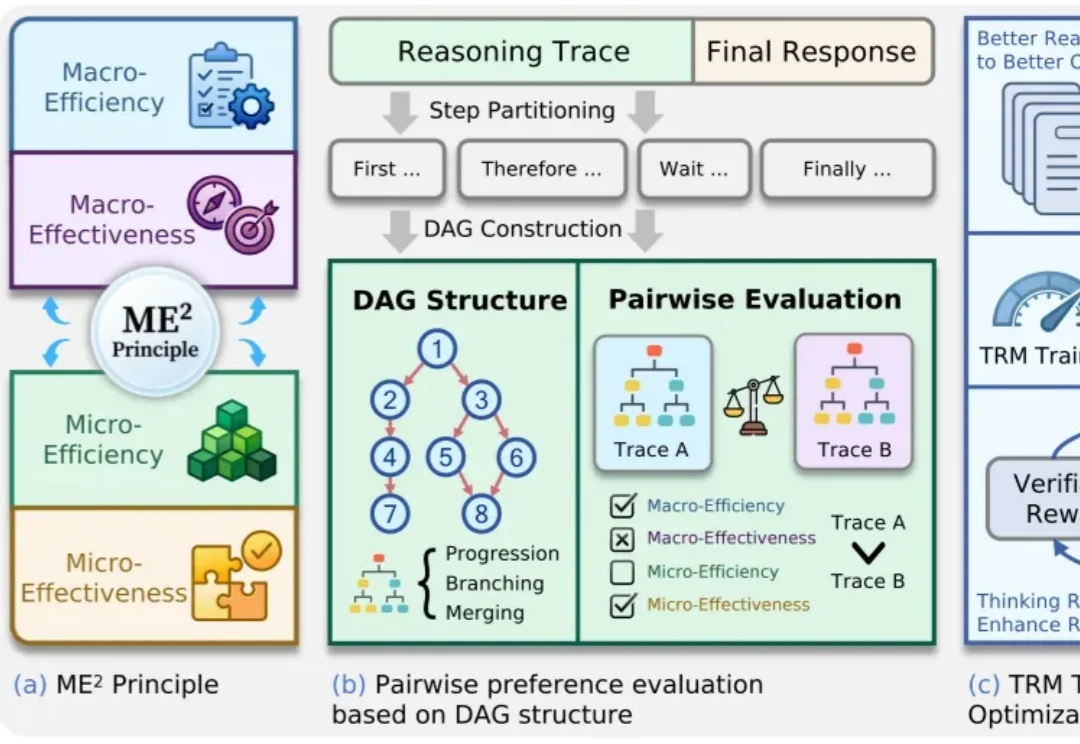
TRM思考奖励模型上线,大模型推理质量终于能量化了 | ICML‘26 Oral
TRM思考奖励模型上线,大模型推理质量终于能量化了 | ICML‘26 Oral大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
来自主题: AI技术研报
6063 点击 2026-06-24 16:03
 搜索
搜索
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,

在推理后训练里,多数方法仍依赖奖励模型、验证器或额外教师信号。如果不依赖这些外部信号,只使用模型自身生成的答案进行自训练,是否仍然能够提升推理能力?是的!SePT(Self-evolving Post-Training)给出肯定答案,简洁的自训练方法,可在数学推理任务准确率直升10个点!
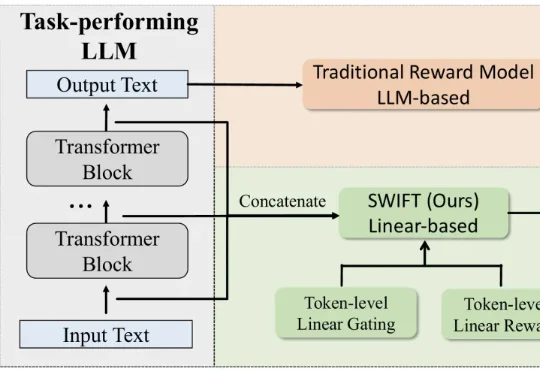
最新奖励模型SWIFT直接利用模型生成过程中的隐藏状态,参数规模极小,仅占传统模型的不到0.005%。SWIFT在多个基准测试中表现优异,推理速度提升1.7×–6.7×,且在对齐评估中稳定可靠,展现出高效、通用的奖励建模新范式。

随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。

OpenAI重磅结构调整:ChatGPT「模型行为」团队并入Post-Training,前负责人Joanne Jang负责新成立的OAI Labs。而背后原因,可能是他们最近的新发现:评测在奖励模型「幻觉」,模型被逼成「应试选手」。一次组织重组+评测范式重构,也许正在改写AI的能力边界与产品形态。
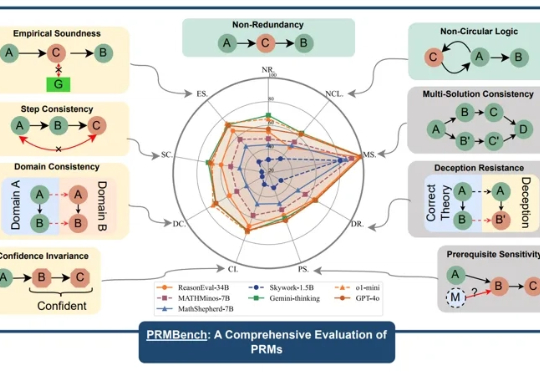
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
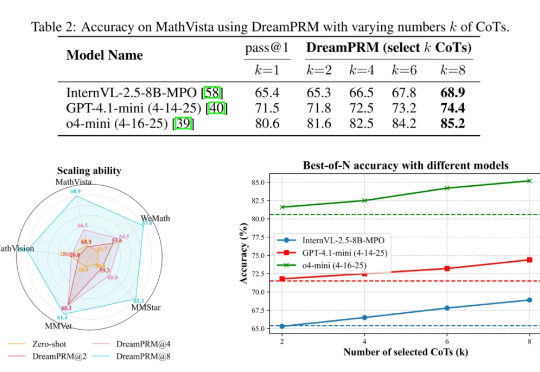
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
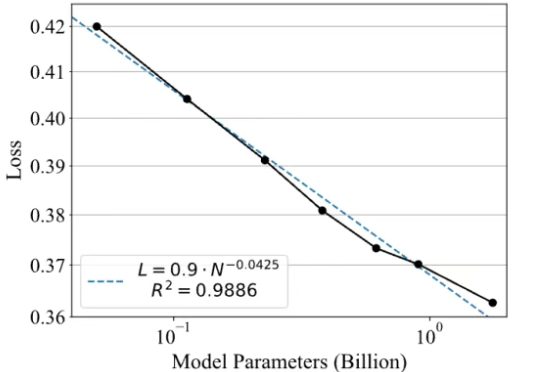
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
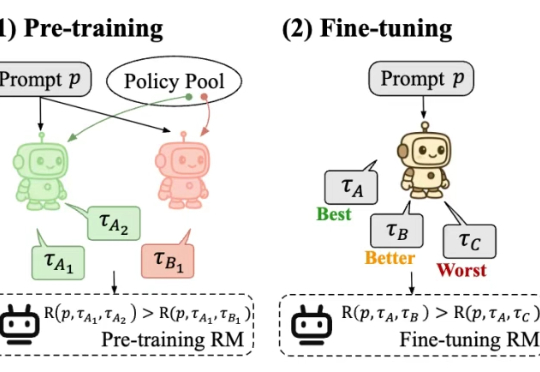
最近,一款全新的奖励模型「POLAR」横空出世。它开创性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注的依赖,更展现出强大的Scaling潜力,让小模型也能超越规模大数十倍的对手。