
刚刚,豆包宣布收费
刚刚,豆包宣布收费今天,字节跳动旗下AI应用豆包正式推出专业版以及对应收费方案。豆包专业版基于最新的豆包2.1系列大模型,将提供更高的生产力场景使用额度,以及接入豆包2.1 Pro模型的全新“办公任务”模式。免费用户可以体验接入豆包2.1 Turbo模型的办公任务模式。
来自主题: AI资讯
9878 点击 2026-06-24 13:19
 搜索
搜索
今天,字节跳动旗下AI应用豆包正式推出专业版以及对应收费方案。豆包专业版基于最新的豆包2.1系列大模型,将提供更高的生产力场景使用额度,以及接入豆包2.1 Pro模型的全新“办公任务”模式。免费用户可以体验接入豆包2.1 Turbo模型的办公任务模式。
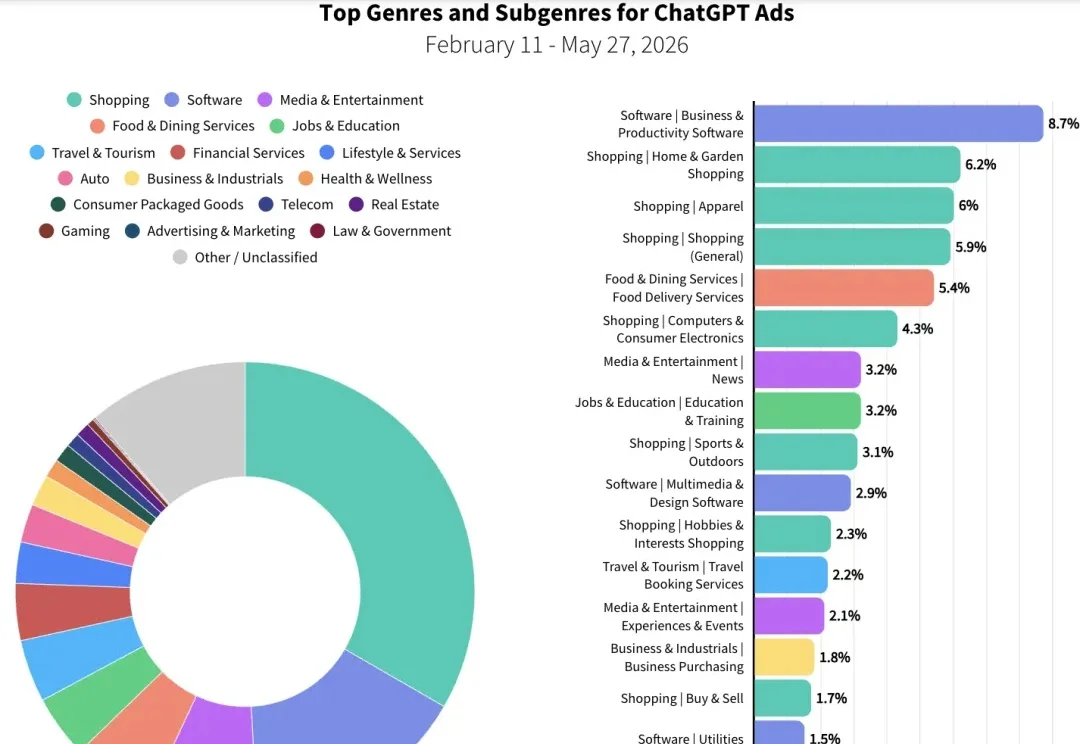
Sensor Tower 发布了他们每年一度的《State of AI Report 2026》,从用户、流量、收入等角度梳理了 2026 年 AI 应用赛道的整体情况。

近日,香港特区政府教育局公布《中小学数字教育发展蓝图》。与过去侧重设备建设和数字工具应用的信息化政策不同,这份文件把课程框架、教师培训、学校治理和资源投入放进同一套制度设计之中,为未来几年香港中小学推进人工智能教育划出了具体路线图。
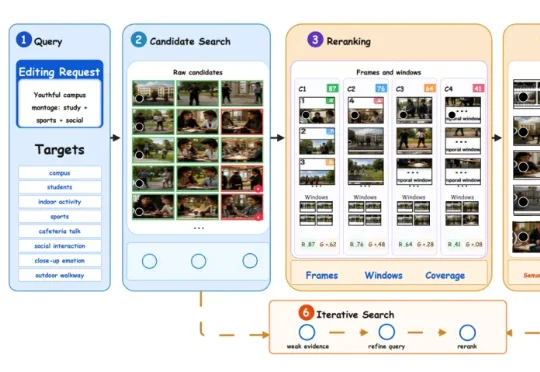
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
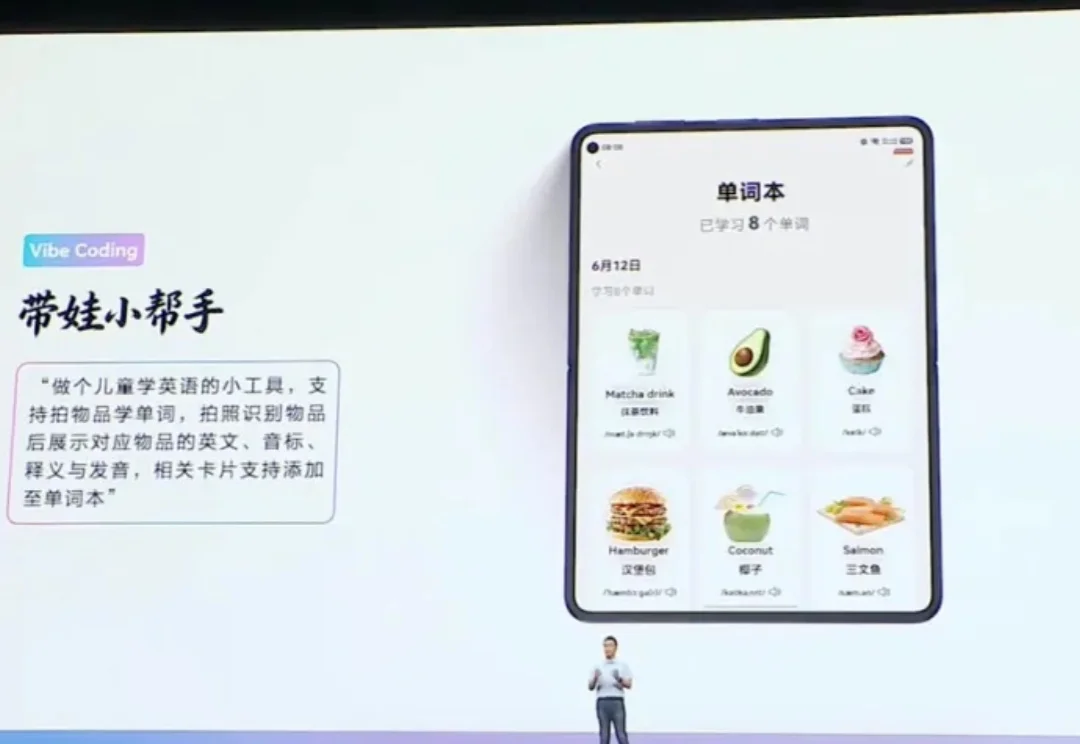
HDC 2026开幕主题演讲上,华为终端BG CEO何刚展示了鸿蒙生态一项新能力:用户唤起小艺claw,用自然语言描述需求,小艺直接生成一个可运行的应用。

AutoResearch这个词关注AI的同学应该不陌生,大神Andrej Karpathy提出的Agent 自主科研项目,现在已经是GitHub的明星项目了,应用不计其数。

刚刚,国内 AI 应用层最大的一笔融资落定了,但你很可能并没有听过这家公司的名字——演语。演语科技,英文名 Evoken。这是它第一次用集团品牌的身份对外发声。在此之前,外界更熟悉的,是它旗下的 LiblibAI。

AI 真正的终局之战,可能根本不在 C 端。过去两年,我们见证了无数个打着“个人助理”旗号的 AI 应用争夺流量入口,像极了移动互联网早期的百团大战。
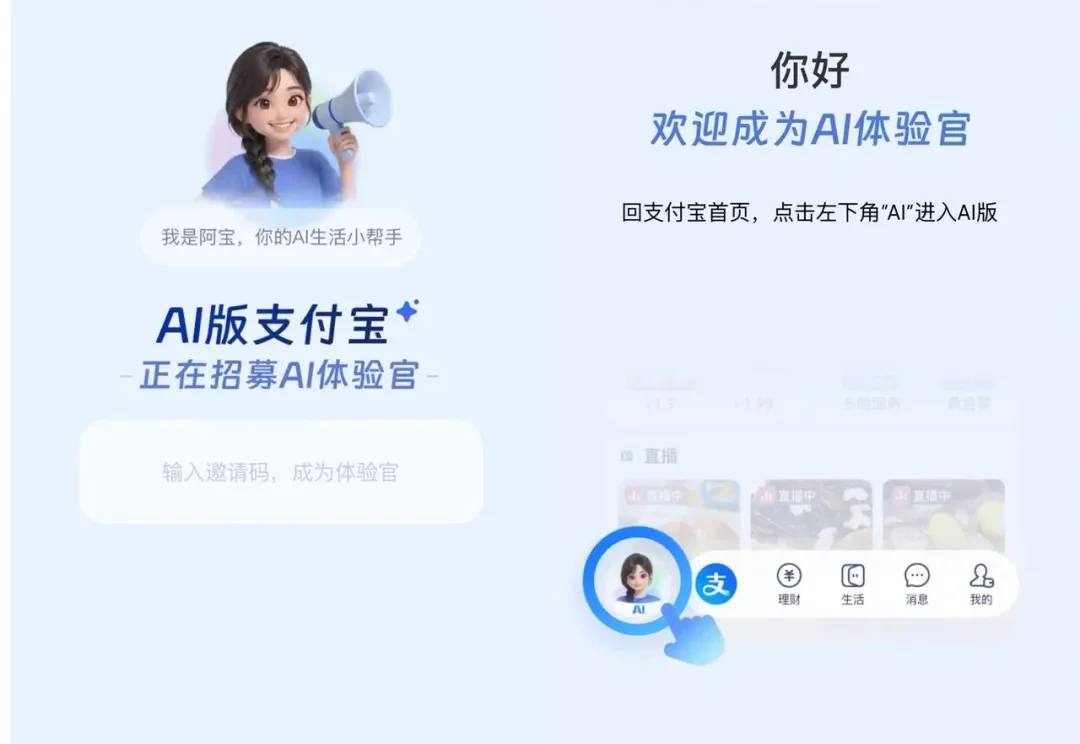
首个完成全端 AI 化的超级应用?

在印度,消费者每天会接到大量电话,从骚扰电话、诈骗电话,到送货员和金融服务公司的联系,种类繁多。虽然有 Truecaller 等应用以及政府的来电姓名显示(CNAP)系统可以识别来电者身份,但仅知道对方姓名往往不够。因此,Equal AI 正在开发一款助手,能够代你接听电话、收集信息,并告知你对方来电的原因。