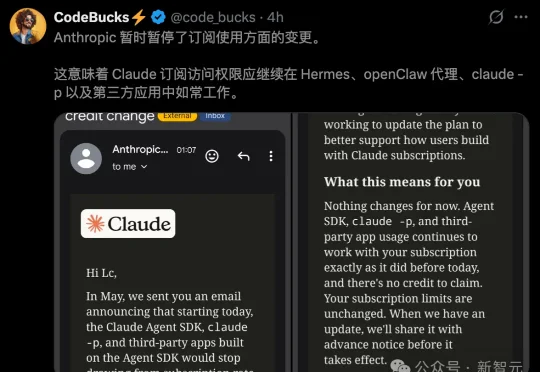
Anthropic撤回第三方订阅限制,「虾马」全面解禁!
Anthropic撤回第三方订阅限制,「虾马」全面解禁!终于,等来了好消息!就在刚刚,Anthropic正式官宣——撤回禁止以编程式调用Claude Code订阅额度的「禁令」。从此,接入Claude的claude -p、OpenClaw、Hermes等第三方应用,可照常从「订阅额度」里扣量了。
来自主题: AI资讯
9729 点击 2026-06-16 11:05
 搜索
搜索
终于,等来了好消息!就在刚刚,Anthropic正式官宣——撤回禁止以编程式调用Claude Code订阅额度的「禁令」。从此,接入Claude的claude -p、OpenClaw、Hermes等第三方应用,可照常从「订阅额度」里扣量了。
AI写代码的风险隐藏在看似正确的代码中,可能引发数据泄露或资产损失。Narwhal AI Code Risks开源项目整理了真实案例、早期信号和典型风险路径,帮助开发者提前识别隐患,避免重蹈覆辙。

新智元近日对话了清华大学教授沈阳。作为长期关注 AI 应用、智能体与产业实践的学者,同时也是 ZeeLin(智灵动力)首席科学家,他个人每天的Token消耗量近10亿,本次对话围绕「自进化AI的自我递归进化」这一主线展开,讨论 AI 自进化与科研、叙事、商业与AGI相关的十个话题。
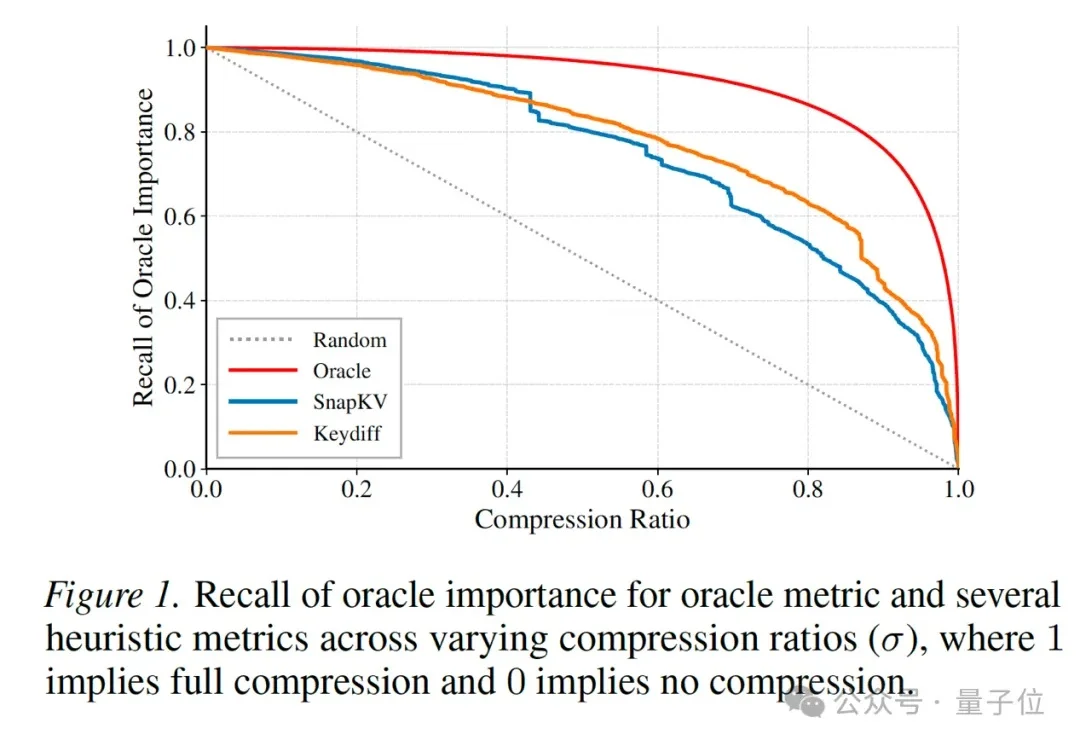
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
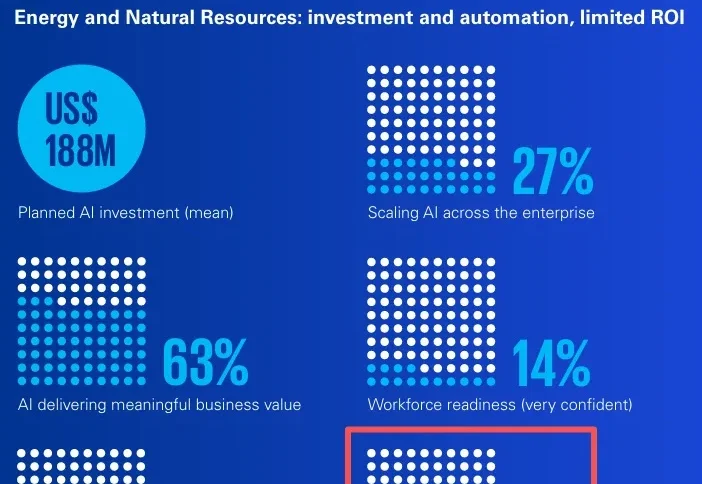
一提到AI的应用和落地,大家就会陷入非共识迷雾。为了拨开营销炒作,我把近期有代表性的几份Enterprise AI调研报告拉通,横跨Menlo Ventures(500+企业AI决策者)、德勤(24个国家,6大行业,3235名高管)、KPMG(20个国家,8大行业,2110名全球高管)、Entelligence(2444家企业)。

今年开年以来,不管是硅谷、还是国内的 AI 投资圈子,都不太敢投 AI 应用了。

今年春节后,一位消失许久的西班牙客户突然回来找老班。
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。

「版本之子」 「同志们朋友们,版本回调了! 现在的情况是,搞AI应用的家人们没活了。胜利女神的天平又一次倾向了大模型公司一边。有鉴于此,我们将复刻致敬葬AI一年前的系列——把模型公司挨个写一遍。 第一

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,