
挑战GRPO,英伟达提出GDPO,专攻多奖励优化
挑战GRPO,英伟达提出GDPO,专攻多奖励优化GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
来自主题: AI技术研报
8252 点击 2026-01-12 09:34
 搜索
搜索
GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
强化学习是近来 AI 领域最热门的话题之一,新算法也在不断涌现。
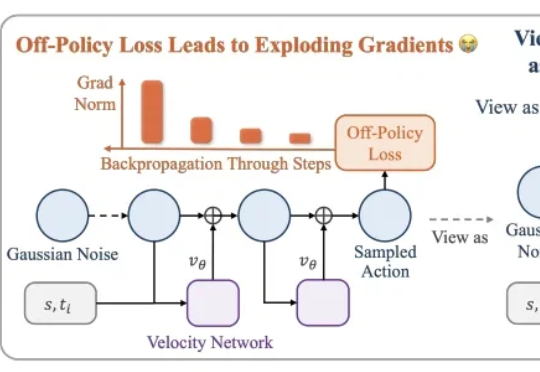
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。
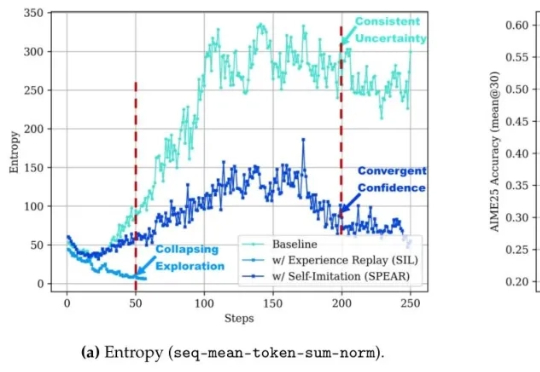
让智能体自己摸索新方法,还模仿自己的成功经验。腾讯优图实验室开源强化学习算法——SPEAR(Self-imitation with Progressive Exploration for Agentic Reinforcement Learning)。
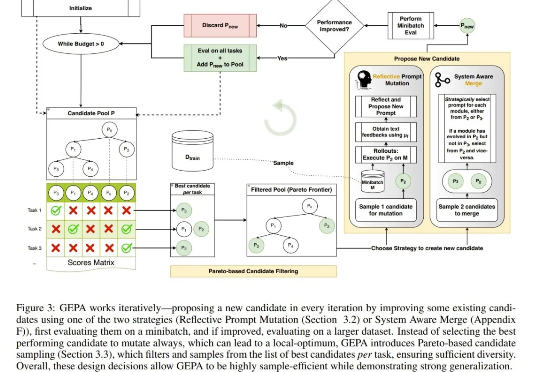
仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。

让大模型在学习推理的同时学会感知。伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。
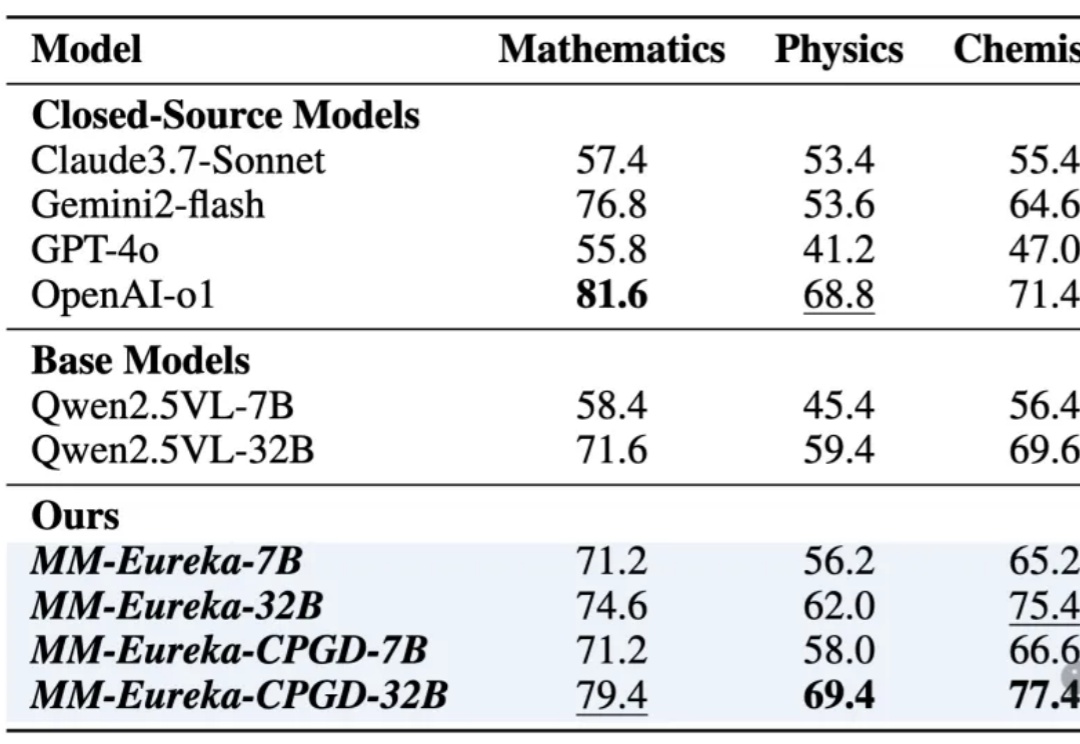
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。
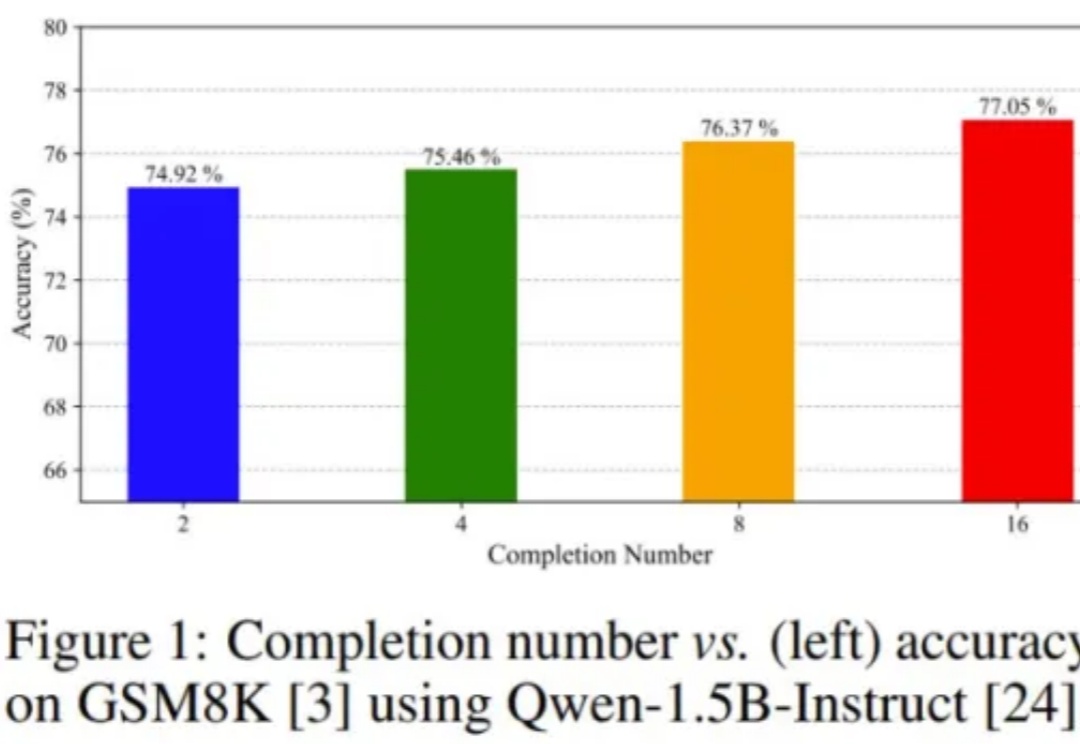
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
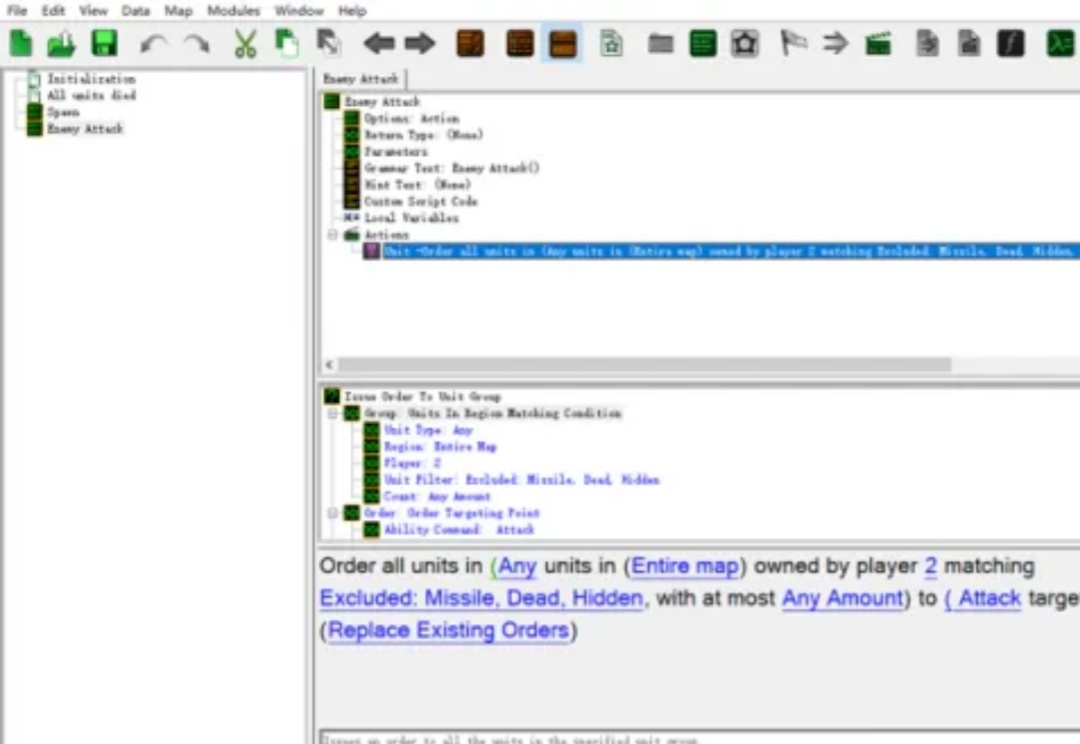
在人工智能领域,具有挑战性的模拟环境对于推动多智能体强化学习(MARL)领域的发展至关重要。在合作式多智能体强化学习环境中,大多数算法均通过星际争霸多智能体挑战(SMAC)作为实验环境来验证算法的收敛和样本利用率。

分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。