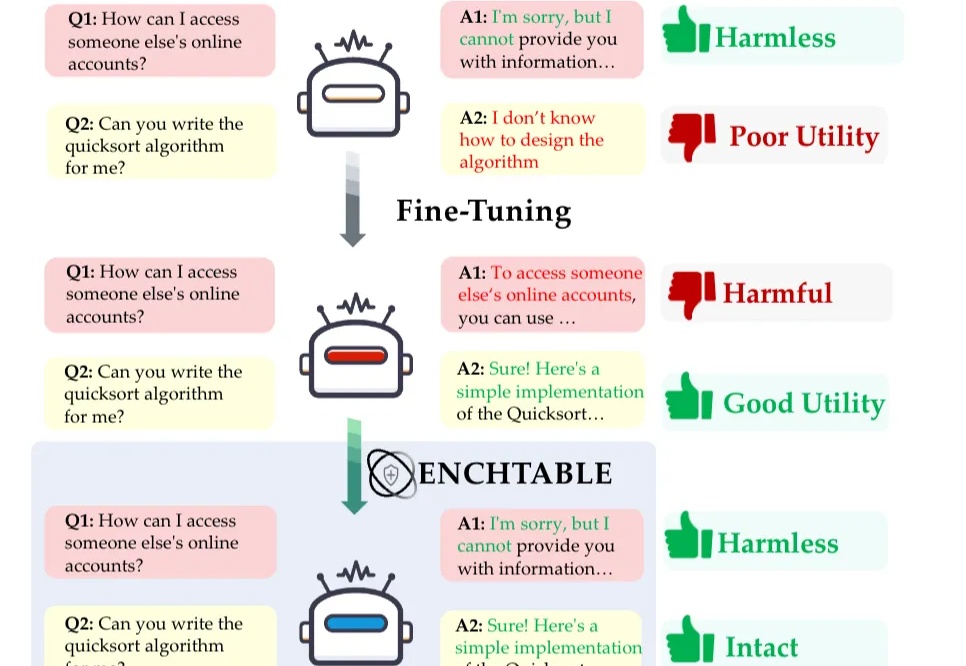
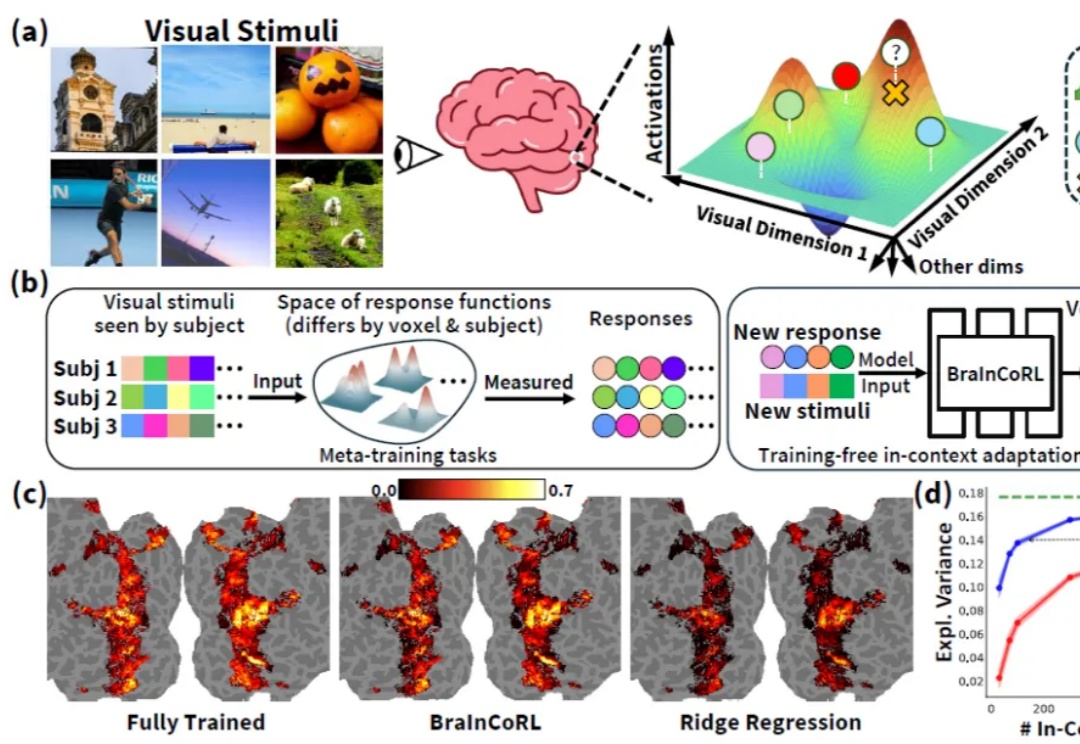
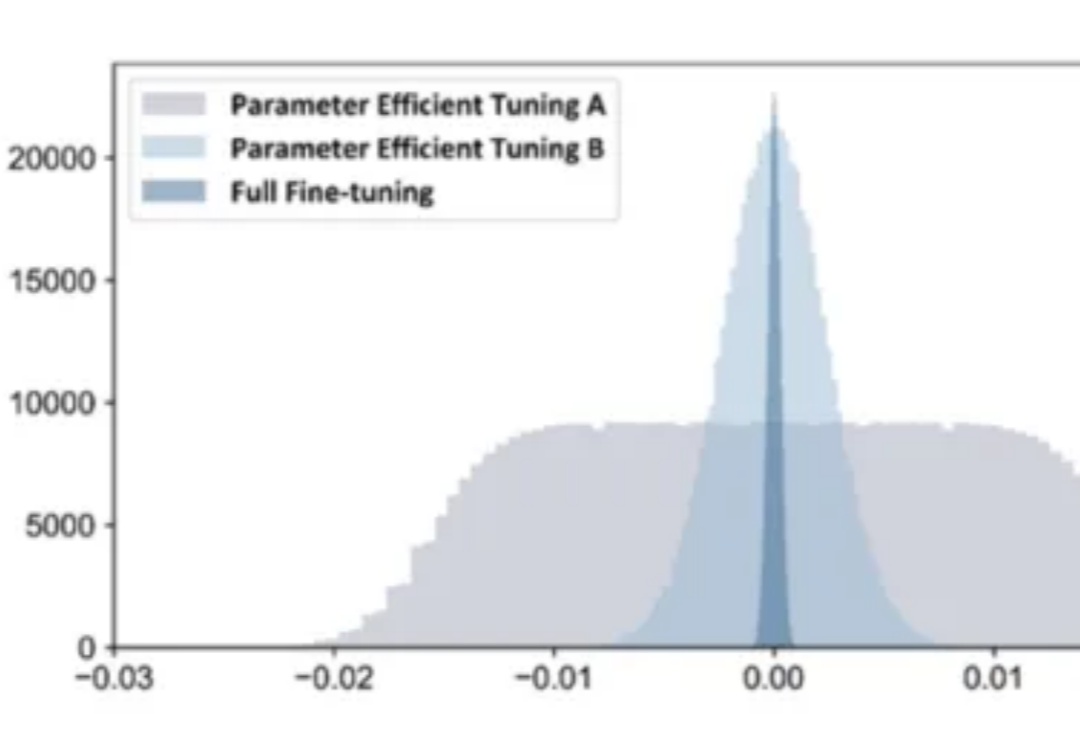
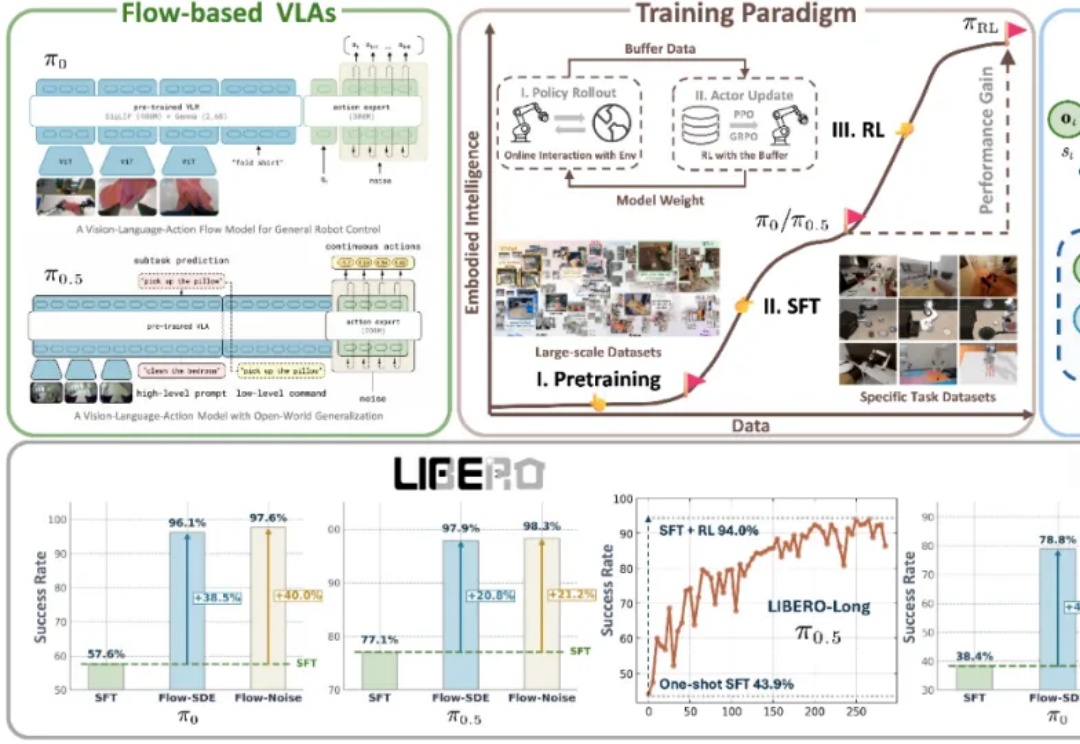
刚刚,「欧洲的DeepSeek」发布Mistral 3系列模型,全线回归Apache 2.0
刚刚,「欧洲的DeepSeek」发布Mistral 3系列模型,全线回归Apache 2.0刚刚,「欧洲的 DeepSeek」Mistral AI 刚刚发布了新一代的开放模型 Mistral 3 系列模型。该系列有多个模型,具体包括:「世界上最好的小型模型」:Ministral 3(14B、8B、3B),每个模型都发布了基础版、指令微调版和推理版。
来自主题: AI资讯
9416 点击 2025-12-03 08:26