
ISSTA 2026|LAVE:面向扩散语言模型的约束解码
ISSTA 2026|LAVE:面向扩散语言模型的约束解码推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
来自主题: AI技术研报
9067 点击 2026-07-16 10:09
 搜索
搜索
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
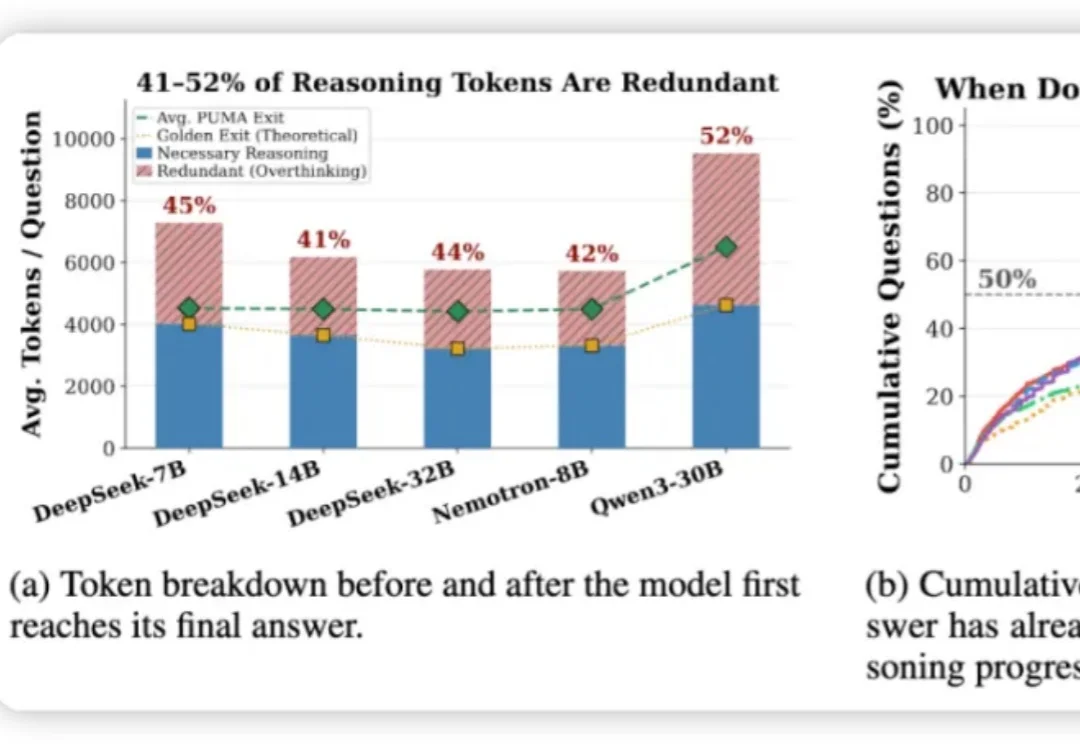
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务
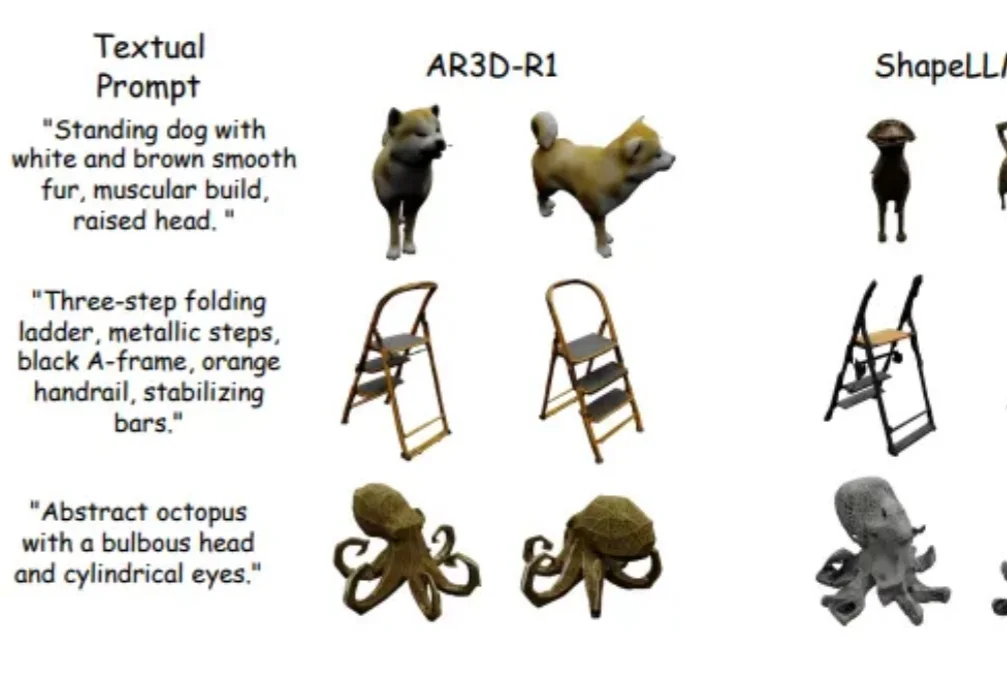
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
今天发布的是文心大模型 X1.1 深度思考模型,它是百度在 4 月份发布的旗舰模型 X1 的升级版,发布即上线,所有人都可以免费体验。同时该模型通过百度智能云千帆平台向企业客户与开发者开放使用。
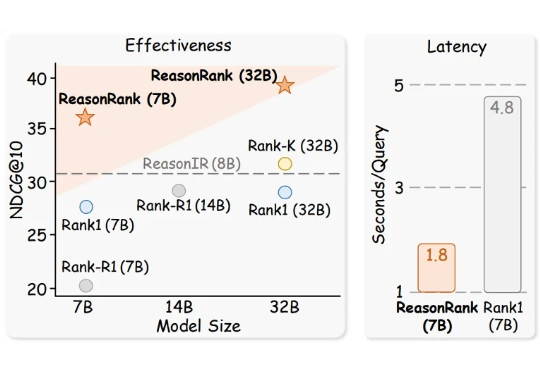
推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。
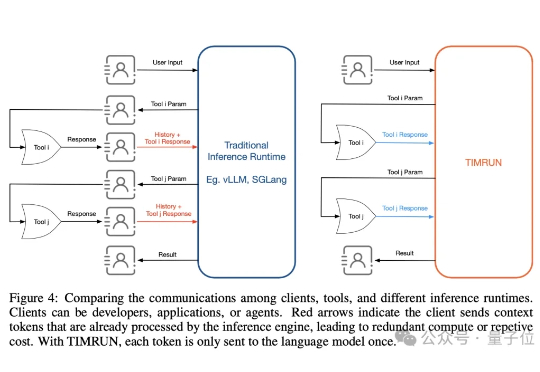
大模型的记忆墙,被MIT撬开了一道口子。 MIT等机构最新提出了一种新架构,让推理大模型的思考长度突破物理限制,理论上可以无限延伸。 这个新架构名叫Thread Inference Model,简称TIM。
随着推理大模型和思维链的出现与普及,大模型具备了「深度思考」的能力,不同任务的泛用性得到了很大的提高。
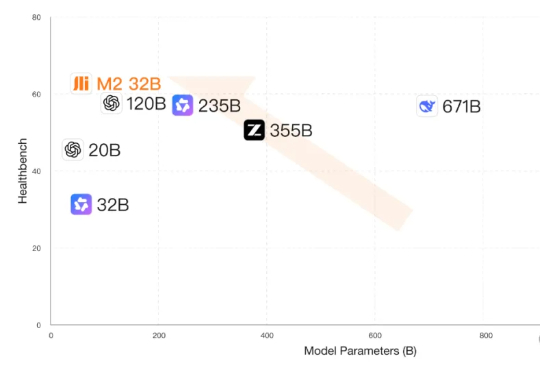
刚刚,全球最强开源医疗模型发布,来自中国。百川开源最新医疗推理大模型Baichuan-M2-32B,在OpenAI发布的Healthbench评测集上,超越其刚刚发布5天的开源模型gpt-oss-120b。