# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。
研究者发现,在数学推理等具有明确答案的任务中,仅使用 “正确 / 错误” 这样极为简单的反馈信号进行强化学习,模型就能够逐步学习到复杂而有效的推理策略,并显著提升推理能力。这类方法被概括为基于可验证奖励的强化学习(RLVR)。
在随后的一年中,RLVR 被成功应用到多种任务和应用场景中,展现出稳定且优异的性能,成为大模型推理能力提升的重要技术路线之一。
然而,尽管 RLVR 取得了显著成效,它仍然存在一些不可忽视的局限性。其中影响较为突出的问题之一是 “过度思考” 现象:对于本身较为简单或直观的问题,模型有时仍会生成冗长、重复甚至不必要的推理过程。这种现象不仅降低了推理效率,也在一定程度上增加了推理成本,成为当前 RLVR 方法亟需解决的关键挑战之一。
许多研究者逐渐形成共识,认为过度思考现象的根源在于可验证奖励信号本身的粗粒度特性。在 RLVR 框架下,只要模型最终给出了正确答案,奖励机制并不会对其推理过程中的中间步骤加以区分或约束。
因而,从用户视角看似多余甚至无意义的 “反复检查” 行为,并不会给模型带来任何负面反馈。在这种奖励结构下,延长推理过程、消耗更多计算步骤,反而成为模型在训练过程中用以最大化正确率的一种 “理性选择”。
针对这一问题,现有研究中较为常见的解决思路是对模型施加显式的推理长度约束,例如统计模型在推理过程中生成的总 token 数,并在 token 数过大或相对过长时对其奖励进行惩罚。
然而,这类方法往往不可避免地削弱模型的推理充分性,从而导致整体准确率下降,使研究者不得不在推理效率与预测准确性之间进行权衡。
为解决这一问题,伊利诺伊大学香槟分校和 Amazon AWS 的研究者提出了自我一致性奖励(Self-Aligned Reward,SAR),利用大语言模型内部的信号构成反馈奖励,刻画推理过程的 “有用与否” 而不仅仅是 “长短”,达成推理准确度和效率的 “双赢 “。


在推理任务中,一个理想的奖励函数应当具备若干关键性质。
首先,作为对可验证奖励的有效补充,它应当是连续的,能够以细粒度方式刻画模型输出质量的差异,而非仅给出二值反馈。
其次,该奖励函数应尽量避免引入额外复杂的评估框架或独立的奖励模型,以降低实现与训练成本。
最后,它应能够直接作用于推理过程中的语义信息,而不是像长度惩罚那样仅依赖于 token 数等统计量,从而更准确地反映推理内容本身的有效性与相关性。
基于上述考虑,本文提出了一种新的奖励函数 ——Self-Aligned Reward(SAR),其设计天然满足上述优良性质。
SAR 的计算方式如下:
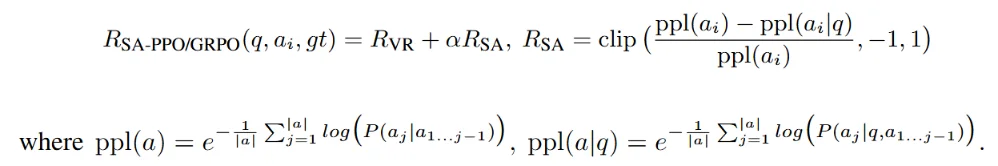
SAR 的核心思想基于大模型对自身生成内容的困惑度(perplexity,PPL)。具体而言,SAR 比较了模型在两种条件下对同一输出文本的困惑度差异:一是将输出视为一段独立文本进行建模,二是在给定输入问题作为上下文的条件下对该输出进行建模。由此,SAR 实际衡量的是:当去除输入问题这一上下文后,模型生成该回答的概率下降了多少。
这一设计具有直观而合理的语义解释。如果某个回答与输入问题高度相关、针对性强,那么只有在问题作为上下文时,该回答才会以较高概率被生成;一旦脱离问题语境,其生成概率将显著降低。
相反,对于内容较为宽泛、与问题关联较弱的回答,是否提供问题作为上下文对其生成概率的影响则相对有限。
因此,SAR 能够有效区分回答与问题之间的语义关联强度,从而在奖励层面鼓励模型生成和问题相关性高、一致性强且语义聚焦的推理结果。
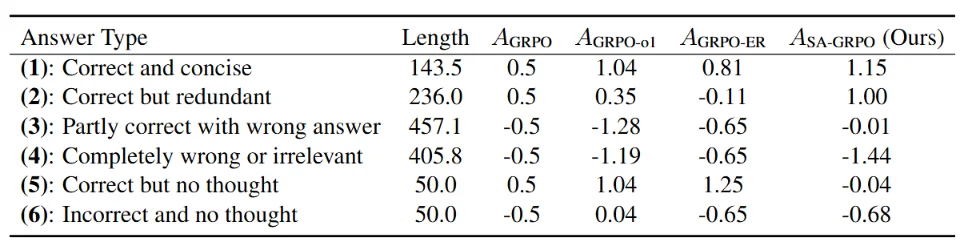
我们在预实验中比较了不同奖励函数在六类回答上的优势(advantage)值(表中 o1 和 ER 是两种长度惩罚算法)。可以看到 SAR 有如下特性,这说明了 SAR 能准确、细粒度地分辨不同类型的回答:
本文在 4 个基础模型和 7 个数据集上进行了系统而全面的实验评估。
在训练过程中,我们将 Self-Aligned Reward(SAR)与可验证奖励按照不同比例进行加权,共同作为强化学习的奖励信号。实验结果表明,SAR 具有良好的通用性,能够无缝应用于 PPO、GRPO 等主流强化学习算法,并在准确度与推理效率两个维度上同时带来显著提升。
总体而言,相较于仅使用 RLVR 的基线方法,引入 SAR 后模型准确率平均提升约 4%,同时生成输出的平均长度至少减少 30%。值得注意的是,尽管训练阶段仅使用了数学领域的数据集,SAR 在逻辑推理等非数学任务的数据集上同样表现出稳定而优异的性能,体现了其良好的跨任务泛化能力。
为了进一步分析 SAR 在准确度与效率之间的权衡特性,我们分别对 SAR 和长度惩罚方法在训练过程中施加不同的奖励权重,从而得到一系列具有不同行为特征的推理模型。
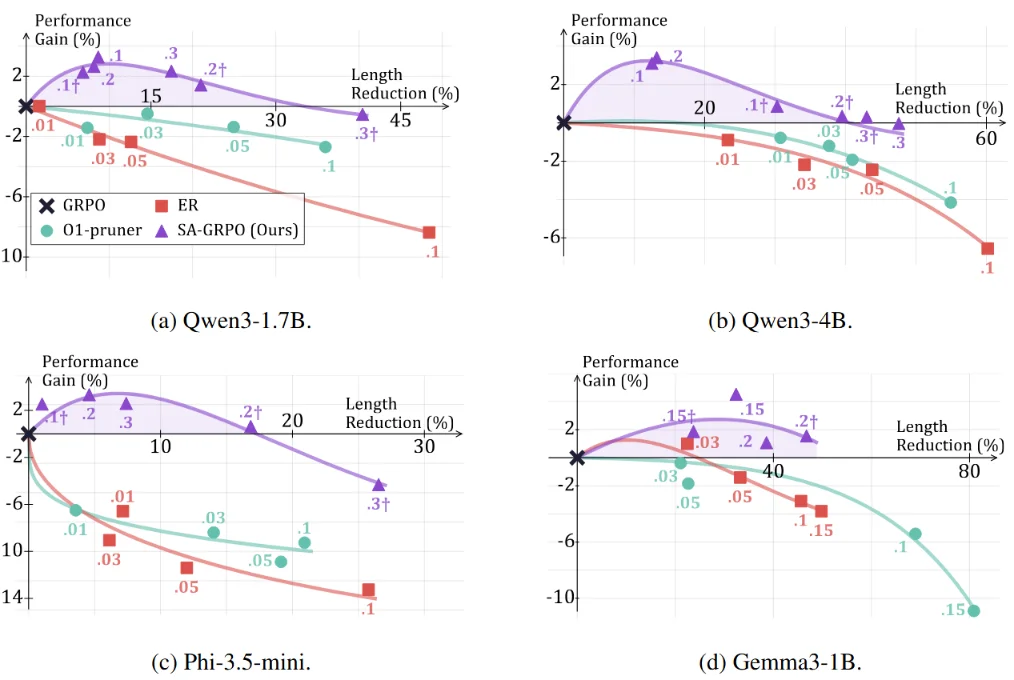
实验中固定可验证奖励的权重为 1,图中标注的数值对应 SAR 或长度惩罚项的权重大小。结果显示,SAR 所对应的性能曲线在整个权重区间内始终优于长度惩罚与基线方法,且其中一部分稳定落在准确度与效率同时提升的第一象限。
这表明,相较于单纯通过惩罚输出长度来压缩推理过程、从而不可避免地牺牲准确率的策略,SAR 能够更有效地协调推理质量与推理成本,在两者之间实现更优的平衡。
本研究提出了 Self-aligned reward,为缓解强化学习推理模型中的过度思考问题提供了一种简单而有效的解决思路。与依赖人工设计规则或显式约束推理长度的方法不同,SAR 直接利用大模型自身的语言建模能力,从语义层面刻画回答与问题之间的内在一致性,在不引入额外评估模型的前提下,实现了对推理质量与效率的协同优化。
这一全新的奖励函数不仅提升了当前推理模型在准确度与计算成本这两个维度的整体表现,也反映了大模型强化学习领域一种新的思想:将模型运行时的的内在信息转化为可用于学习的连续反馈信号,从而实现大规模,可持续,甚至 “自我进化 “式的训练。我们认为,Self-aligned reward 作为一种简洁,高效,泛用性强的强化学习方法,有望被推广至更广泛的推理任务中,进一步推动高效、可靠的大模型推理系统的发展。
本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院二年级博士生,导师为 Jiaxuan You 教授。其主要研究方向为:大语言模型社会智力及其在复杂场景中的推理。本工作为作者在 Amazon AWS 实习期间的成果。
文章来自于微信公众号 “机器之心”,作者 :“韩沛煊”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
