
仅用提示词工程摘下IMO金牌!清华校友强强联手新发现,学术界不靠砸钱也能比肩大厂
仅用提示词工程摘下IMO金牌!清华校友强强联手新发现,学术界不靠砸钱也能比肩大厂无需谷歌“钞能力”,两位清华校友强强联合,直接让基础模型Gemini 2.5 Pro轻松达到IMO金牌水平。
来自主题: AI资讯
7877 点击 2025-08-02 16:40
 搜索
搜索
无需谷歌“钞能力”,两位清华校友强强联合,直接让基础模型Gemini 2.5 Pro轻松达到IMO金牌水平。
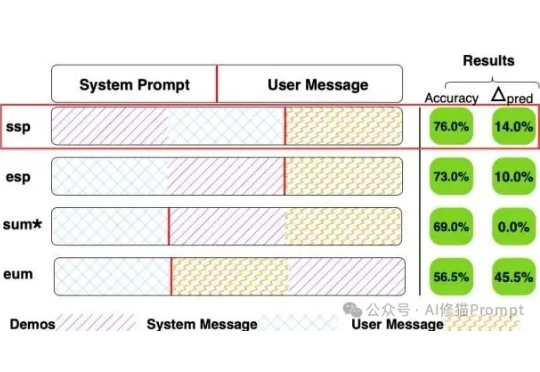
上下文学习(In-Context Learning, ICL)、few-shot,经常看我文章的朋友几乎没有人不知道这些概念,给模型几个例子(Demos),它就能更好地理解我们的意图。但问题来了,当您精心挑选了例子、优化了顺序,结果模型的表现还是像开“盲盒”一样时……有没有可能,问题出在一个我们谁都没太在意的地方,这些例子,到底应该放在Prompt的哪个位置?
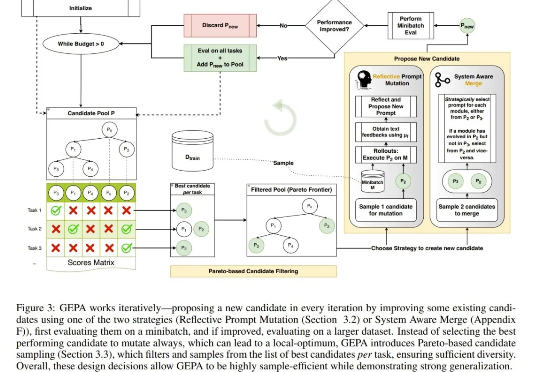
仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。

今天凌晨,ChatGPT 迎来了一个重磅更新。不是 GPT-5,而是 Study Mode(学习模式)。在该模式下,ChatGPT 不再只是针对用户查询给出答案,而是会帮助用户一步步地解决自己的问题。
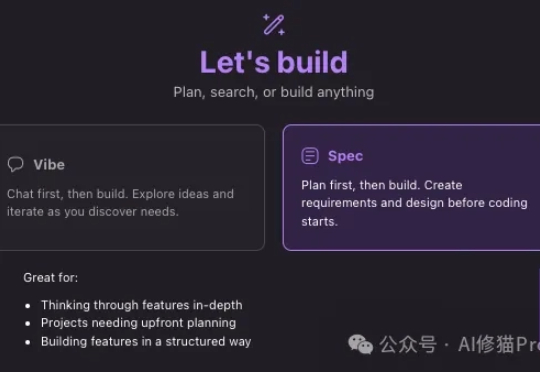
10天前Amazon发布了他们自己的开发平台,Kiro IDE,其中有一个很厉害的交互功能“Spec(Specification)”,强调的是规范的文档,说明书,以一套非常结构化的方法确保开发过程的系统性、可控性和质量,堪称现代软件工程的最佳实践。让vibe coding有一个规范的范式。
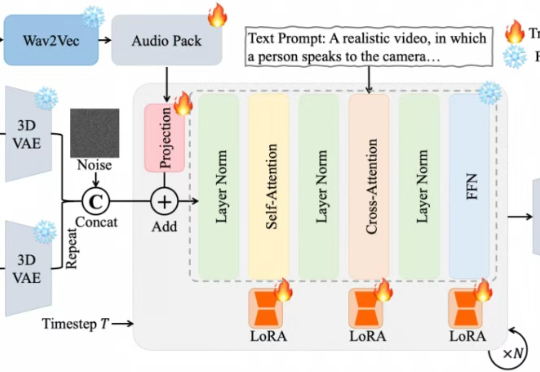
近期,夸克技术团队和浙江大学联合开源了OmniAvatar,这是一个创新的音频驱动全身视频生成模型,只需要输入一张图片和一段音频,OmniAvatar即可生成相应视频,且显著提升了画面中人物的唇形同步细节和全身动作的流畅性。此外,还可通过提示词进一步精准控制人物姿势、情绪、场景等要素。
今天带来 Myshell ShellAgent 2.0 的测试和介绍。 发现 Myshell 上了一个 ShellAgent 2.0 的能力,只需要提示词就能生成一个 Agent 应用。他们这个有意思的点是,没有复杂的前端页面都会在一个 Chatbot 里构建类似的交互,这就摆脱了构建前端的复杂流程降低了错误率,Agent 只需要管理工具之间的交互就可以。
你有没有想过,为什么那些看起来无所不能的 AI agent,在真实工作环境中却总是显得如此笨拙?我们花费数百小时调试提示词、完善指令,但这些智能系统依然无法像人类员工那样从经验中学习和成长。它们不会从错误中汲取教训,也不会在重复性任务中变得更加熟练。这个根本性问题,正是 Composio 刚刚完成 2500 万美元 A 轮融资要解决的核心挑战。

就在昨天,来自UCLA的两位研究者黄溢辰和杨林做了一件让整个AI圈都震惊的事。他们用Google的Gemini 2.5 Pro模型,在2025年国际数学奥林匹克竞赛中拿下了金牌水平的成绩,6道题解对了5道。这可不是什么花架子,IMO被公认为是测试AI推理能力的终极试金石,因为它需要的不仅仅是计算,更需要创造性思维和严密的逻辑推理。

在过去很长一段时间里,科技圈似乎人均都成了“提示词工程师”,大家都在琢磨怎么用最精妙的语言驯服AI。但包括Andrej Karpathy在内的很多行业大佬已经开始反思了,他们认为,决定AI效果的关键,可能早就不是怎么问,而是你给AI喂了什么料。这个思路,就是最近越来越火的上下文工程(Context Engineering)。