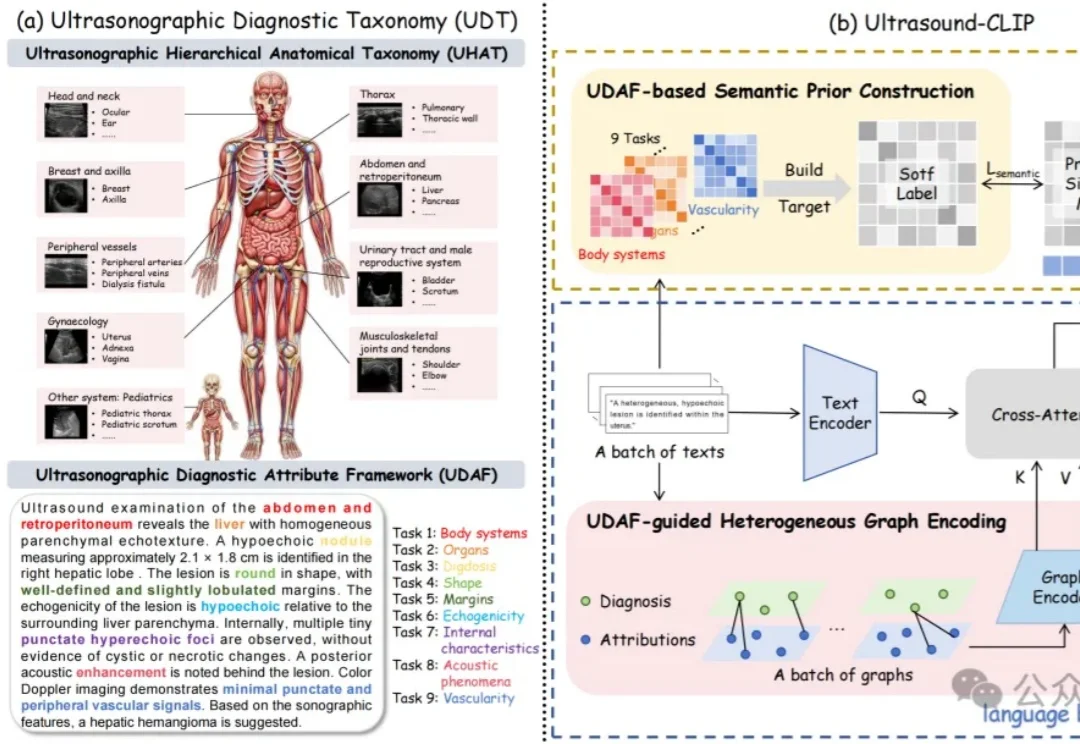
36.4万超声图文对!中国团队构建首个大规模超声专属数据集,让AI真正读懂临床诊断语义丨CVPR'26
36.4万超声图文对!中国团队构建首个大规模超声专属数据集,让AI真正读懂临床诊断语义丨CVPR'26超声领域也有大模型了!
来自主题: AI技术研报
9393 点击 2026-04-13 09:38
 搜索
搜索
超声领域也有大模型了!

华为联合南方医院及行业伙伴首次面向全球发布医院通用人工智能平台(Hospital AI Platform,以下简称“HAIP”)。该平台定位为医院专属“AI操作系统”,通过统筹全院算力、数据、模型资源,将分散的AI能力整合为统一数智化底座
Braintrust 是一家做 AI 产品可观测性和评估的公司。你可以理解为:帮你监控和调试 AI 智能体的工具。他们发现,现有的数据库——无论是 Postgres、数据仓库还是浏览器端的 DuckDB——全都扛不住 AI 工作负载。于是他们做了一个很大胆的决定:自己造一个数据库。

2026 年 1 月,Twitch 的一场 Subathon(订阅马拉松直播)中,AITuber Neuro-Sama(账号名:Vedal987)以约 16 万活跃订阅数一度登顶 Twitch 订阅榜,且拉开第二名、知名游戏主播 Jynxzi 的订阅数据一倍有余。

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?
2023 年,AI 生成的成人内容数量暴涨了 500%。同年,所有新增的成人素材里,有 25% 是 AI 造的。根据经济学人数据,AI 成人行业的规模在 2025 年大概 25 亿美元,这个数字往回倒 1 年是 1.5 亿美元,一年暴增 20 倍以上。AI 成人妥妥的「高速暴增品类」。
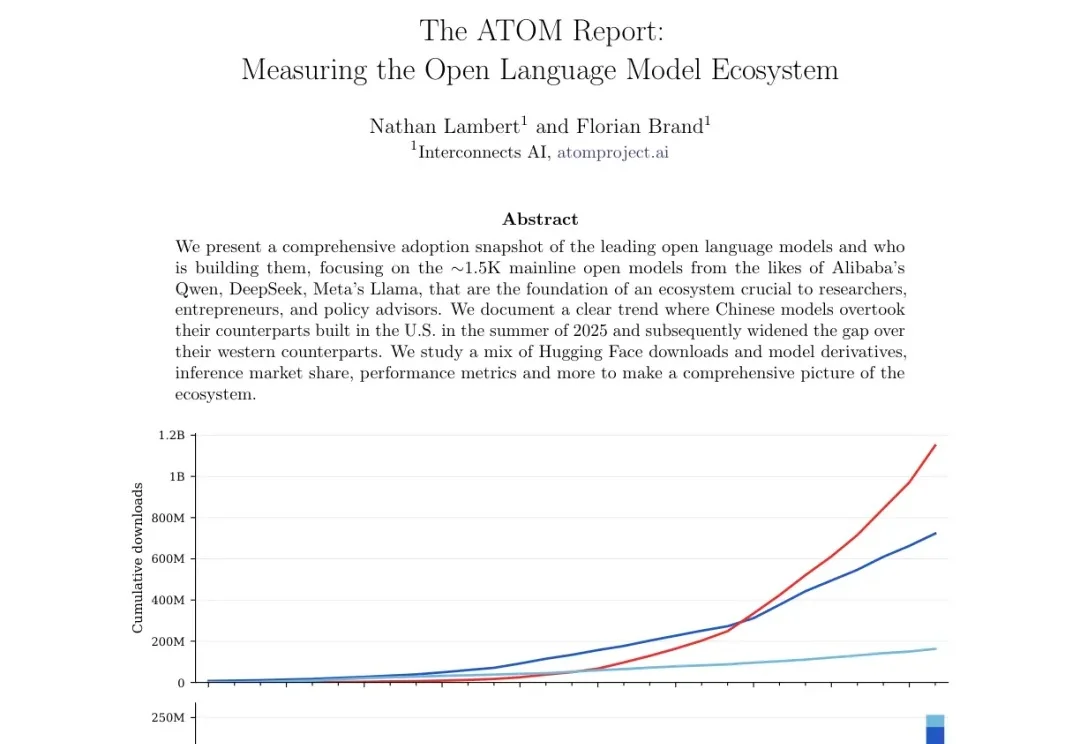
2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月

硅谷「华人地图第一人」入局具身数据赛道。

我认真看 Hermes Agent,不是因为它2.9万Star,而是因为那条 hermes claw migrate。一个新框架敢把"把旧用户整套资产搬过来"做成默认入口,这事本身就很说明问题。

穆迪最新报告揭示了两条平行宇宙:要么AI让生产率狂飙,失业率降至3.8%;要么泡沫破裂,460万人失去饭碗。Anthropic CEO预警白领消亡,经济学家却说还没到时候。2026年1月创纪录的裁员数据,似乎正在验证前者。