
不要凭感觉猜AI泡沫,数据告诉你怎么识别
不要凭感觉猜AI泡沫,数据告诉你怎么识别三个指标,判断AI产业的位置。很多人喜欢拿现在的AI跟2000年互联网泡沫对比,有人说已经到了,有人说还早,两种说法都不太对。判断产业阶段得看数据,不能凭感觉。第一个指标,大厂资本开支。
来自主题: AI资讯
8917 点击 2026-07-05 10:31
 搜索
搜索
三个指标,判断AI产业的位置。很多人喜欢拿现在的AI跟2000年互联网泡沫对比,有人说已经到了,有人说还早,两种说法都不太对。判断产业阶段得看数据,不能凭感觉。第一个指标,大厂资本开支。
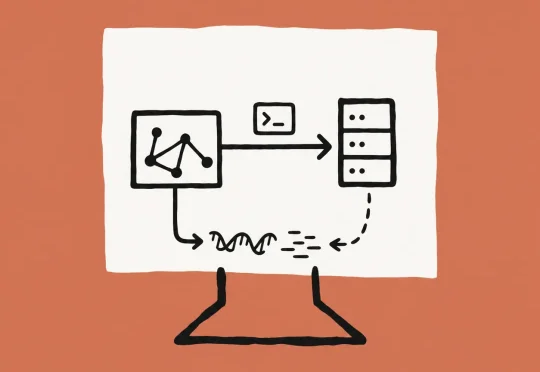
Anthropic 在 6 月 30 日发布了 Claude Science。 如果只看发布稿,这很容易被理解成“Claude 又加了一套科研插件”。但我看完之后,感觉它想做的事情比插件更重一点:它不是只帮你读论文、写代码、画图,而是想把文献、数据库、代码环境、计算资源、图表、手稿和结果审查放进一个连续的科研工作台里。这件事对生信人很有吸引力。

7月4日,豆包和通义千问宣布智能体功能将下线。豆包发布《豆包智能体功能下线通知》,称由于产品功能调整,智能体功能将于2026年7月15日下线。功能下线后,用户仍可在一段时间内查看并自行保存智能体信息及历史对话数据,10月15日后,豆包将根据《隐私政策》对智能体相关数据进行处理,后续将无法在豆包内查看或恢复。
Pinecone宣布 旗下 Nexus 知识引擎将与 Microsoft OneLake 实现新的集成,从根本上改变企业 AI 智能体访问和推理企业数据的方式。这项集成在 Microsoft Build 2026 大会上正式发布,允许 AI 智能体通过预构建的结构化知识工件(非传统的检索管道)查询存储在 OneLake 中的企业信息。

就在昨晚,Anthropic扔出了经济指数系列的第六份报告——第一次把几百万次Claude对话的采样精度从每周拉到逐小时!你几点焦虑、几点嘴馋、几点睡不着,全在数据里。AI比你的伴侣还懂你的作息。
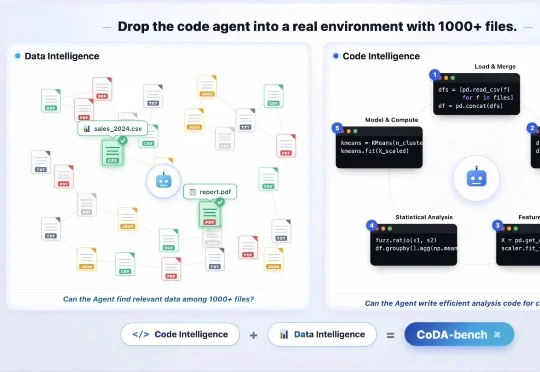
中国人民大学的研究团队提出 CoDA-Bench,联合评估 Agent 的 Code Intelligence + Data Intelligence。该基准首次把 Code Agent 放进包含 1000 + 数据文件的复杂环境下,要求模型先自主探索文件系统、找到相关数据,再编写代码完成分析。实验显示,即使当前表现最好的系统,在 CoDA-Bench 上执行准确率也只有 61.1%;

来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。

施耐德电气(Schneider Electric SE)同意以 31 亿美元全现金交易收购 Cognite,以扩大其工业数据与 AI 软件业务。这也是欧洲工厂加速现代化浪潮中的一项重要布局。这家法国能源管理设备制造商计划将 Cognite 与旗下工业软件业务 Aveva 进行整合。
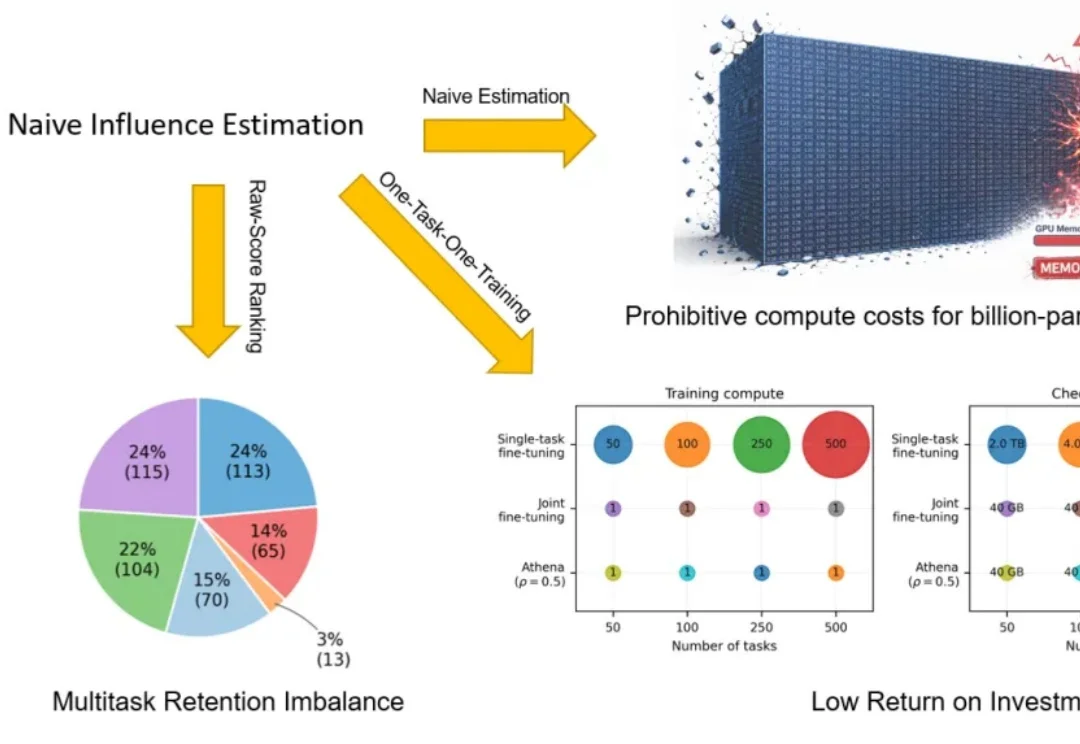
具身智能正在进入数据 scaling 时代。Vision-Language-Action(VLA)模型让机器人可以从大规模示教数据(demonstrations)中学习更通用的操作策略。但对机器人 VLA 训练来说,数据并不总是越多越好:低质量数据可能会拖累模型性能,而每一条 demonstration 都意味着昂贵的人力采集、机器人运行,以及云端存储和训练成本。

具身智能数据的竞争,正在从“量大管饱”进入下一关。