
Verily获3亿美金融资从谷歌独立,AI健康助手赛道开始进入商业化验证期
Verily获3亿美金融资从谷歌独立,AI健康助手赛道开始进入商业化验证期Verily这家公司身上有太多漂亮标签。它从Google X走出来,是Alphabet孵化多年的生命科学资产,做过临床研究平台、慢病管理、人群疾病监测、可穿戴设备、研究数据环境、个人健康应用和人工智能助手。每一个方向单独拿出来,都足够讲一篇精准医疗的未来故事。
来自主题: AI资讯
9118 点击 2026-07-02 12:02
 搜索
搜索
Verily这家公司身上有太多漂亮标签。它从Google X走出来,是Alphabet孵化多年的生命科学资产,做过临床研究平台、慢病管理、人群疾病监测、可穿戴设备、研究数据环境、个人健康应用和人工智能助手。每一个方向单独拿出来,都足够讲一篇精准医疗的未来故事。
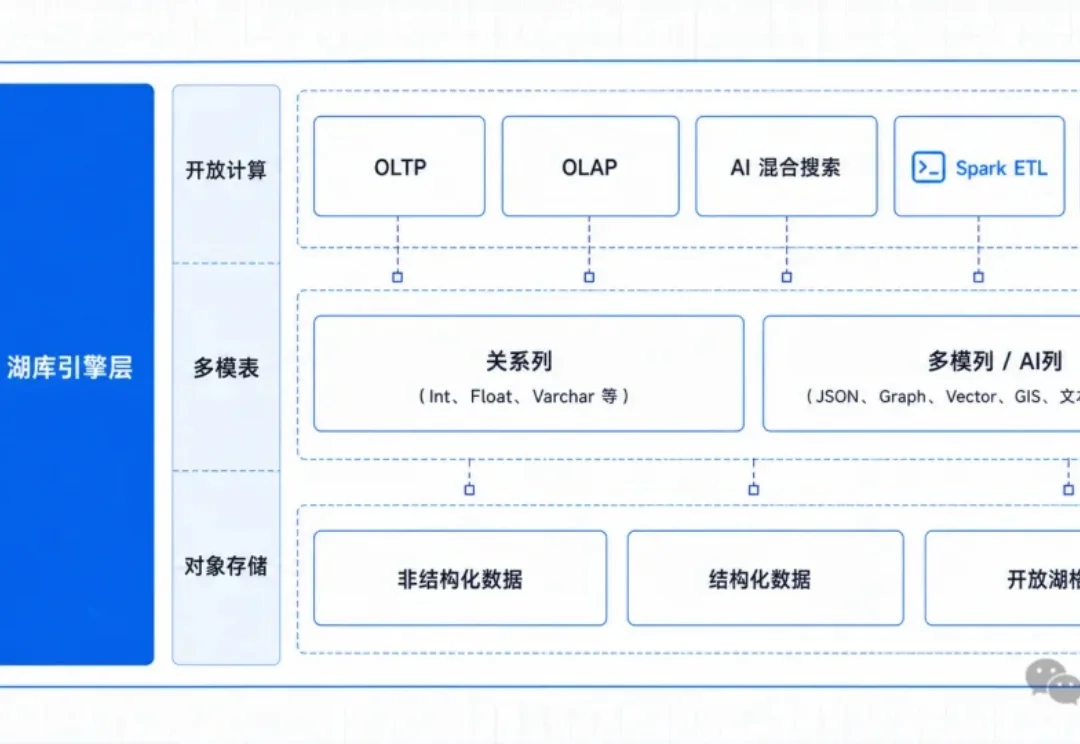
AI时代苟日新,日日新,又日新,数据库也是如此。
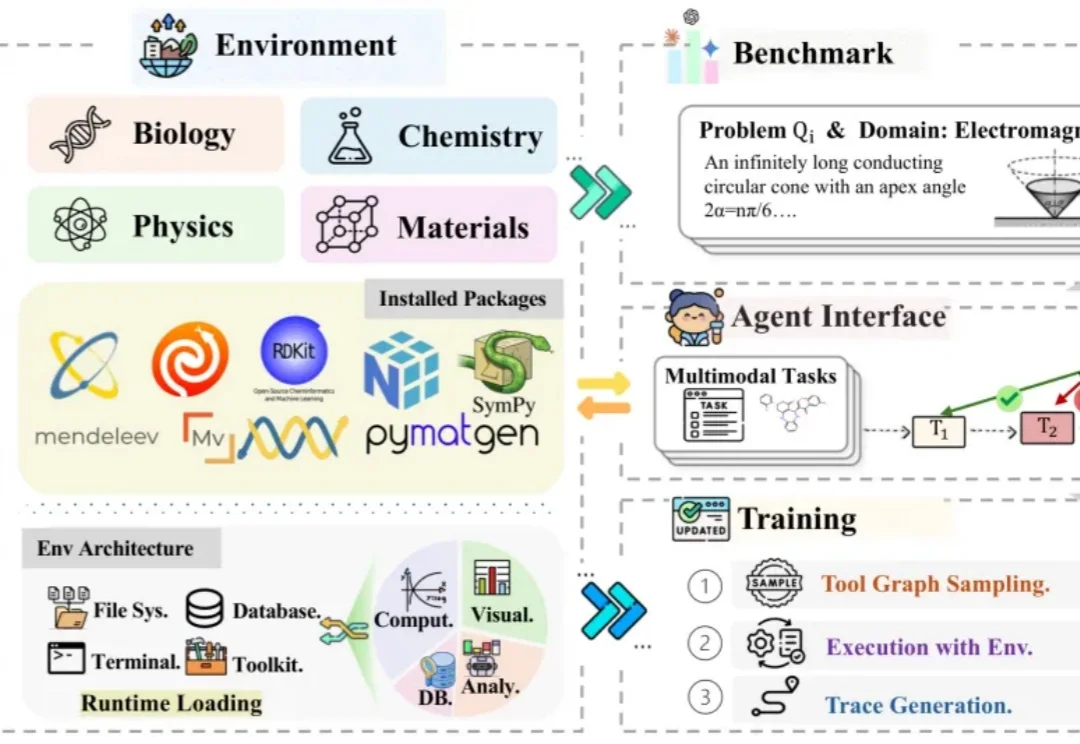
DeepMind 联合创始人、2024 年诺贝尔化学奖得主 Demis Hassabis 曾谈到,他一直将 AI 视为推动知识前沿的重要工具。AI 可以帮助科学家处理复杂数据、发现隐藏模式,也可能在未来参与更深层的科学探索。
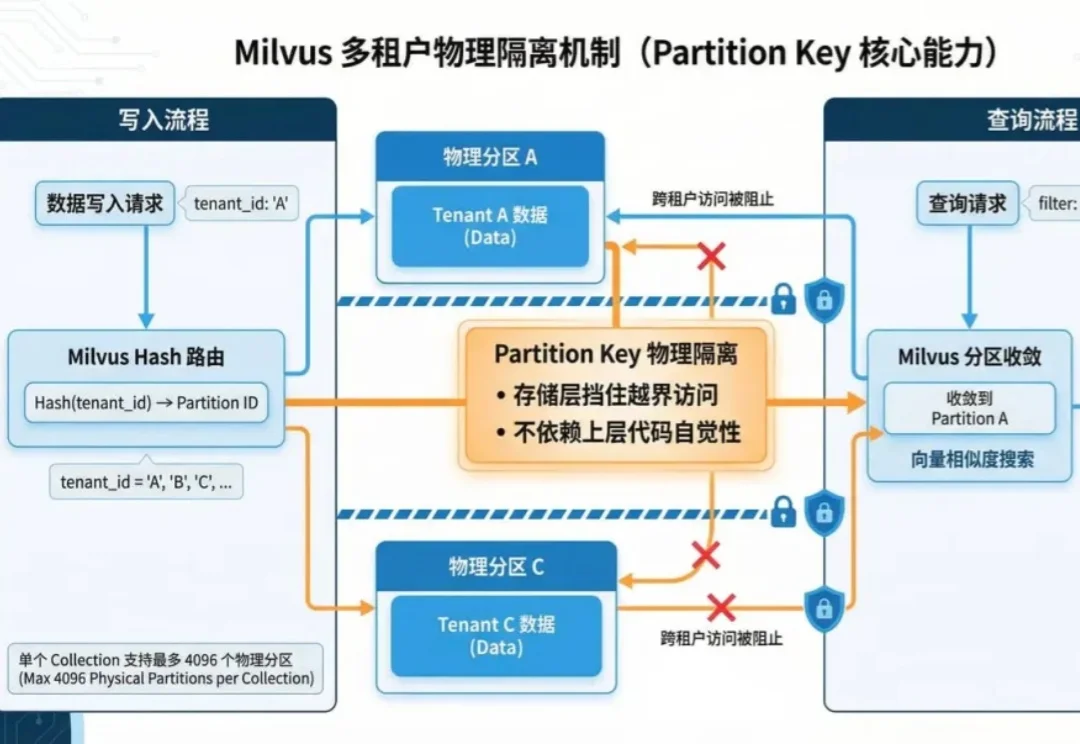
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。

OpenAI首席研究官Mark Chen释放了一个强烈信号:OpenAI 并不认为scaling laws已经失效,恰恰相反,预训练、数据工程、推理训练和更长任务链条,仍是通向AGI的主干道路。
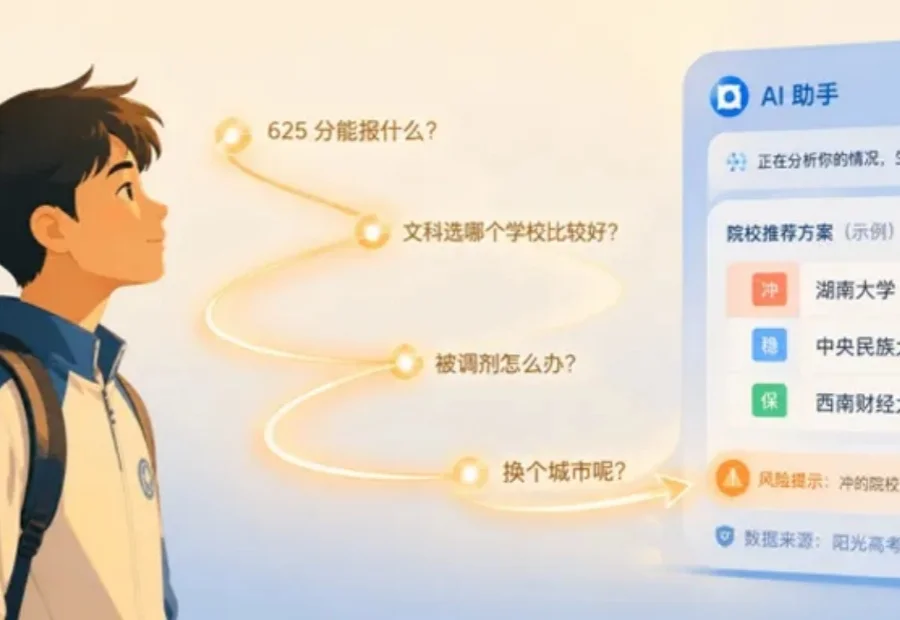
AI高考志愿填报,数据只是最基础的一环。

最近硅谷最火的岗位,非FDE莫属。FDE全称“Forward Deployment Engineer”,可以直接翻译成“前线部署工程师”。他们既要懂模型和技术,也要理解客户的数据、流程和业务痛点,核心任务是把AI从demo变成各个职业自己的AI-native工作流。

我们公司的一个小伙伴,前阵子应聘了一份给机器人打工的工作。
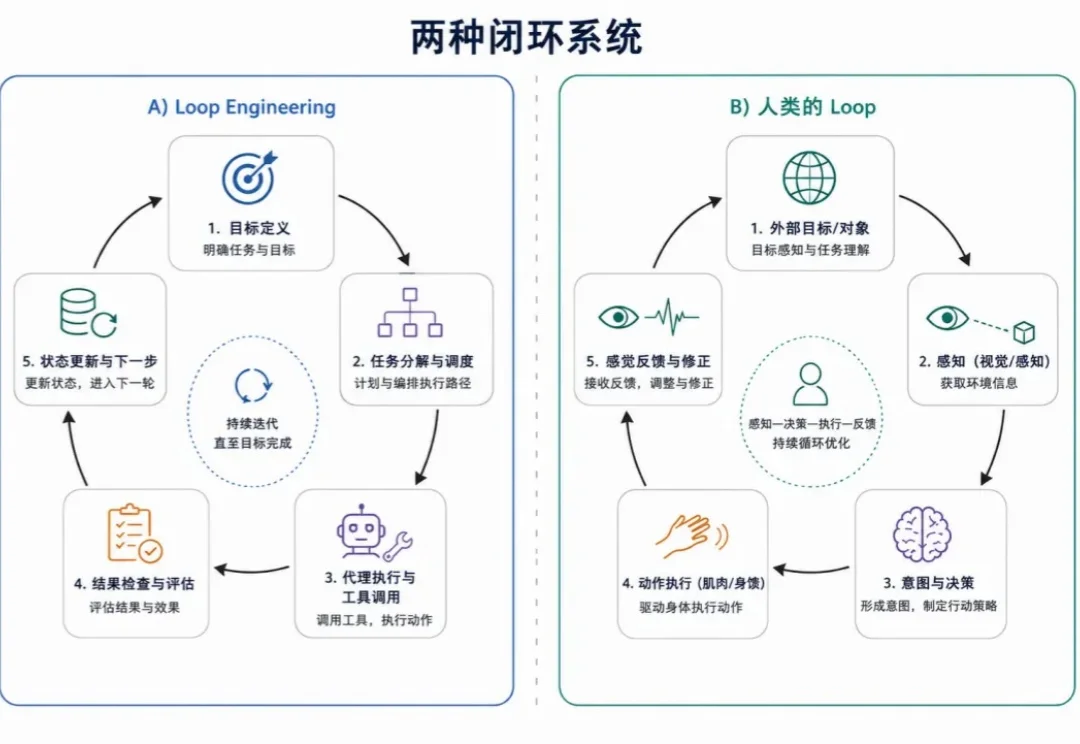
AI 圈最近又热了一个词:Loop Engineering。

据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。