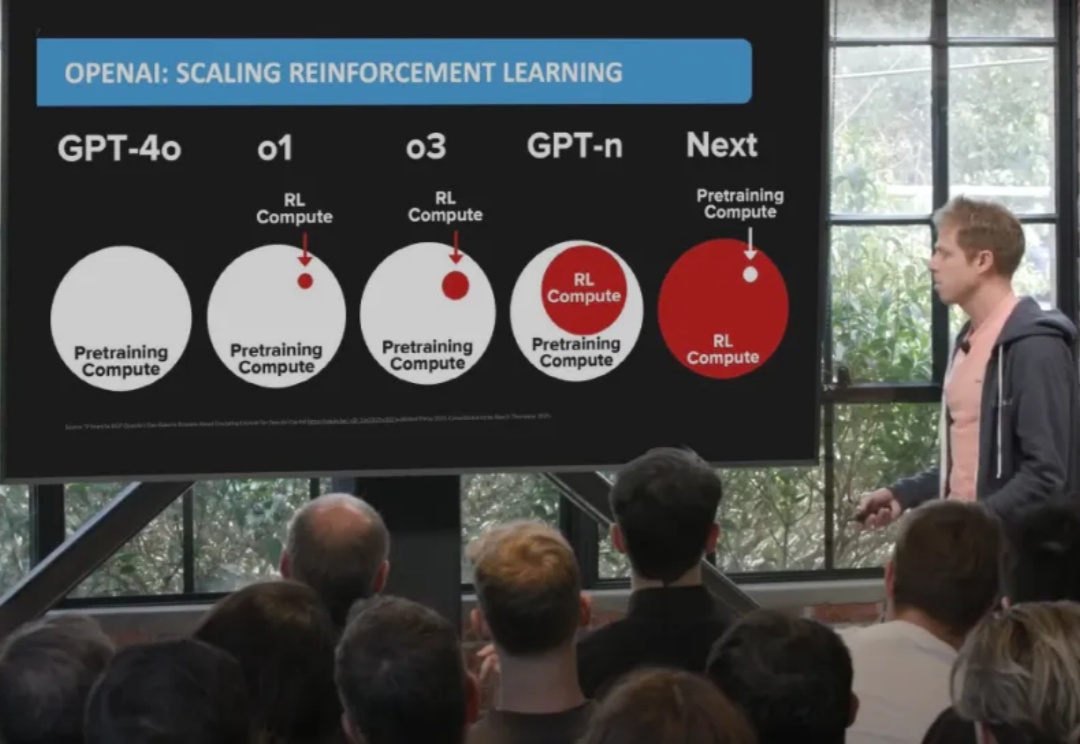
首个为具身智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源
首个为具身智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。
来自主题: AI技术研报
7531 点击 2025-09-01 16:49
 搜索
搜索
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。

「算力是智能时代的土壤,其规模与效率决定着数字未来的疆界。」
近日,无问芯穹发起了一次推理系统开源节,连续开源了三个推理工作,包括加速端侧推理速度的 SpecEE、计算分离存储融合的 PD 半分离调度新机制 Semi-PD、低计算侵入同时通信正交的计算通信重叠新方法 FlashOverlap,为高效的推理系统设计提供多层次助力。下面让我们一起来对这三个工作展开一一解读:

国际可重构计算领域顶级会议 ——FPGA 2025 在落幕之时传来消息,今年的最佳论文颁发给了无问芯穹和上交、清华共同提出的视频生成大模型推理 IP 工作 FlightVGM,这是 FPGA 会议首次将该奖项授予完全由中国大陆科研团队主导的研究工作,同时也是亚太国家团队首次获此殊荣。

还在为 DeepSeek R1 官网的卡顿抓狂?无问芯穹大模型服务平台现已上线满血版 DeepSeek-R1、V3,无需邀请即可免费用 Token!另有异构算力鼎力相助,支持通过 Infini-AI 异构云平台一键获取 DeepSeek 系列模型与多元异构自主算力服务。

由无问芯穹与上海交通大学联合研究团队提出的视频生成软硬一体加速器,首次实现通过差分近似和自适应数据流解决 VDiT 生成速度缓慢瓶颈,推理速度相比 A100 提升高达 16.44 倍。

大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。

全球首个端侧全模态理解开源模型来了!

随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。

智能涌现获悉,「无问芯穹」宣布完成近5亿元A轮融资。这也是目前为止,国内AI Infra(大模型基础设施)层创业公司最大的单笔融资记录。