
戴盟机器人完成亿元融资,阿里通义多模态大牛原玮浩加盟攻关物理世界模型
戴盟机器人完成亿元融资,阿里通义多模态大牛原玮浩加盟攻关物理世界模型具身智能公司戴盟机器人(Daimon Robotics)新近完成亿元A轮融资,本轮融资由汇川产投和中国电信联合投资。与此同时量子位还获悉了关于这家公司的另一则消息——阿里通义实验室前多模态研究专家原玮浩加入戴盟,担任首席AI科学家。
来自主题: AI资讯
8950 点击 2026-06-04 10:50
 搜索
搜索
具身智能公司戴盟机器人(Daimon Robotics)新近完成亿元A轮融资,本轮融资由汇川产投和中国电信联合投资。与此同时量子位还获悉了关于这家公司的另一则消息——阿里通义实验室前多模态研究专家原玮浩加入戴盟,担任首席AI科学家。

今日(6月3日)绳驱AI机器人公司星尘智能(Astribot)完成B轮系列融资——三个月内连续完成3轮融资,融资总额超10亿元,估值突破百亿元,跻身中国具身智能第一梯队。

赋予机器人物理理解和预测能力是通用操作的关键。蚂蚁灵波等机构提出的 LingBot-VA 试图将视频帧预测与动作推理统一起来,让机器人通过自回归扩散框架学会“一边思考一边行动”。

Agent时代卷起分布式推理风暴,高通“从毫瓦到千瓦”AI全家桶进击。
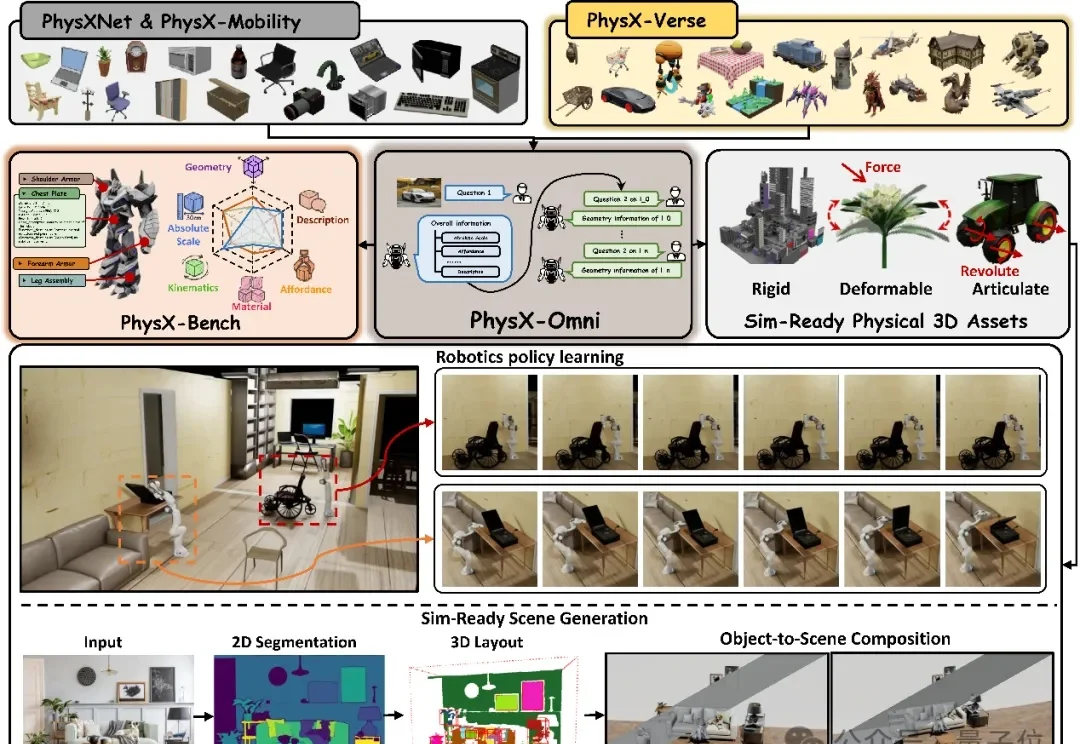
3D生成领域,一个核心矛盾正在浮出水面。

星源智,被视为“下一个智谱”。AI 科技评论独家获悉,具身智能大脑公司星源智机器人(以下简称“星源智”)已完成新一轮融资。至此,这家成立仅10个月的公司累计融资金额已达10亿元人民币。

独家获悉,字节跳动多模态负责人周畅管理范围再次扩大,原由李航负责的 Seed Robotics 团队已向周畅汇报月余,李航现以顾问身份负责学术合作方向。字节也正在招聘具身智能技术负责人,负责机器人业务整体规划,职级定位为 L8,对标阿里 P10-P11,将向周畅汇报。该岗位候选人主要来自头部具身智能创业公司技术负责人。

6 月 2 日,具身智能公司星海图正式发布双足机器人「行客 Kengo」。这是星海图首次对外推出双足形态的机器人产品。按照星海图披露的信息,Kengo 身高 1.4 米,采用双足设计,头部搭载曲面屏。它的单关节扭矩超过 130N·m,可以完成舞蹈、互动等高动态动作;倒地跌落 10 次后仍可正常运行,线束折弯寿命超过 20 万次。

“AI硬件现在还不是一个行业,而是一个方向。它落在工业、教育、医疗等具体场景里,才真正构成行业。”

2018 年从哈佛回国时,橡木果机器人的发起人姜峣有了一个判断:语言和操作,是两种完全不同的智能。