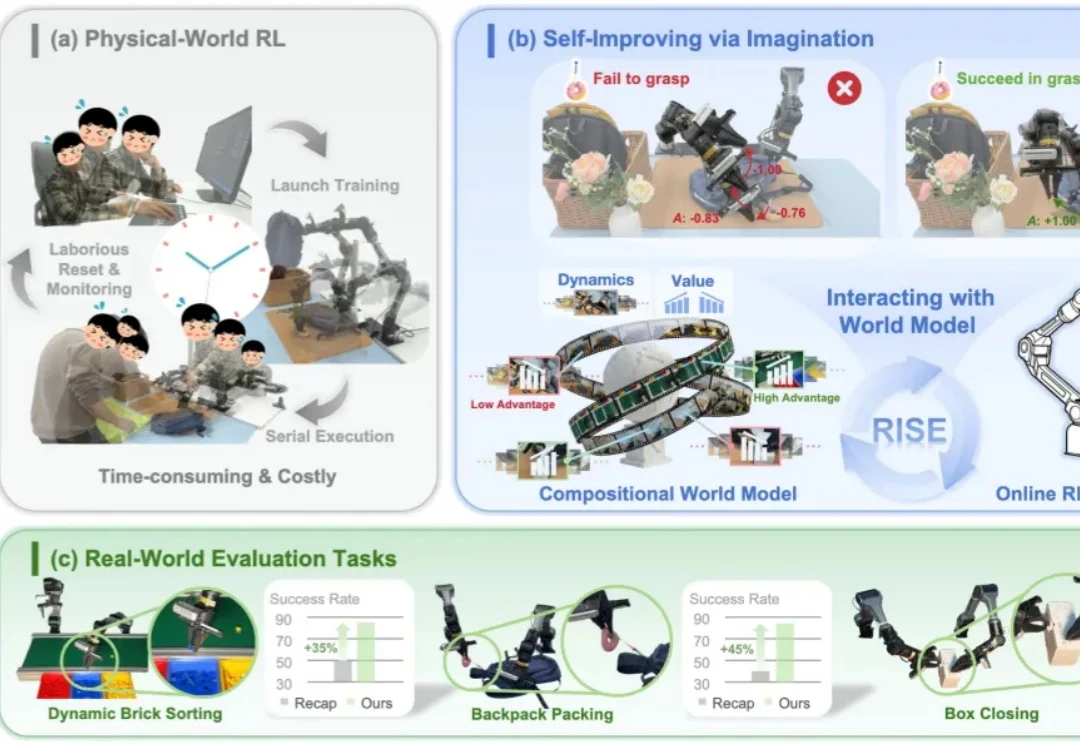
TPAMI 2026 | 仅用两个变量破解混杂因素:CIC实现动力学因果推断与混杂变量重构
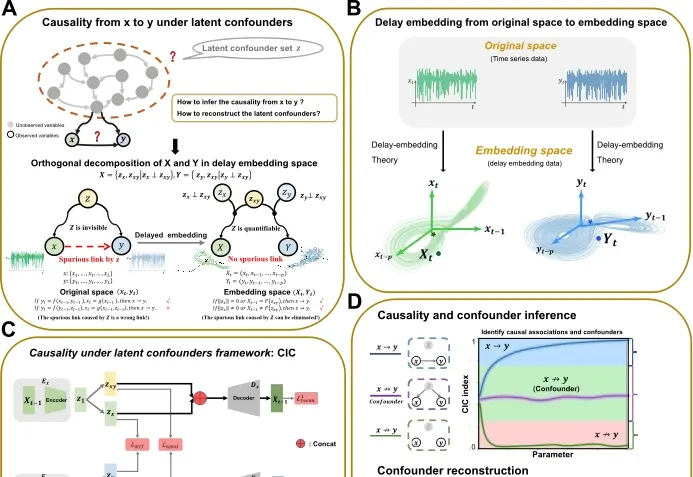
TPAMI 2026 | 仅用两个变量破解混杂因素:CIC实现动力学因果推断与混杂变量重构从观测时间序列数据中准确识别因果关系,是生命科学、地球科学、经济学以及人工智能等诸多领域的核心科学问题。尤其在复杂生物系统中,基因、蛋白质和代谢物之间高度耦合,并常常受到大量不可观测因素的干扰——这些「隐形混杂」无法被直接测量,却会严重误导因果推断结果,产生虚假的因果关联。
来自主题: AI技术研报
10238 点击 2026-03-19 09:44