
视频生成太慢?英伟达、谢赛宁等发布TMD框架,实现70倍加速
视频生成太慢?英伟达、谢赛宁等发布TMD框架,实现70倍加速近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。
来自主题: AI技术研报
9545 点击 2026-03-11 15:05
 搜索
搜索
近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。

让AI像Kaggle顶尖选手一样设计算法,需要几步?

视频生成进入大规模时代,但计算成本也炸了。
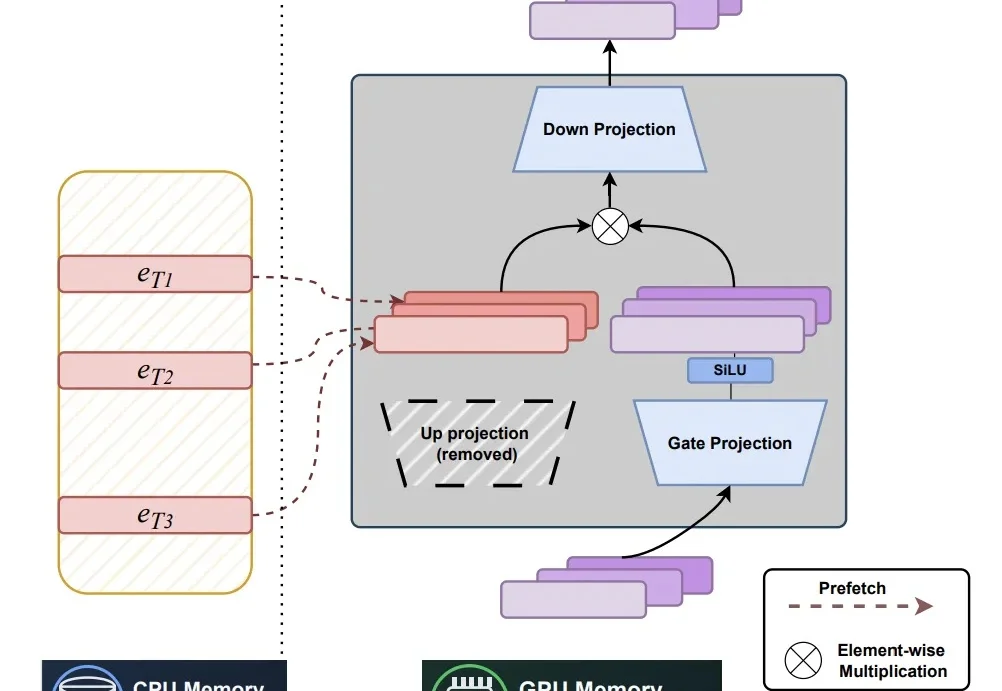
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。

大神Karpathy又开源了新项目——一个能够自主进化的AI科研循环系统。这个项目名叫autoresearch,主打让智能体完全自主地搞科研,只要在Markdown文档里写好指令,剩下的流程全都由AI自动完成。

就在刚刚,Google Research团队用Gemini Deep Think + 树搜索框架,独立攻克了一个理论物理领域的未解积分难题——宇宙弦引力辐射功率谱的精确解析解。AI探索了600条候选路径,找出6种解法,最优雅的那条,让人类物理学家都拍案叫绝。
近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
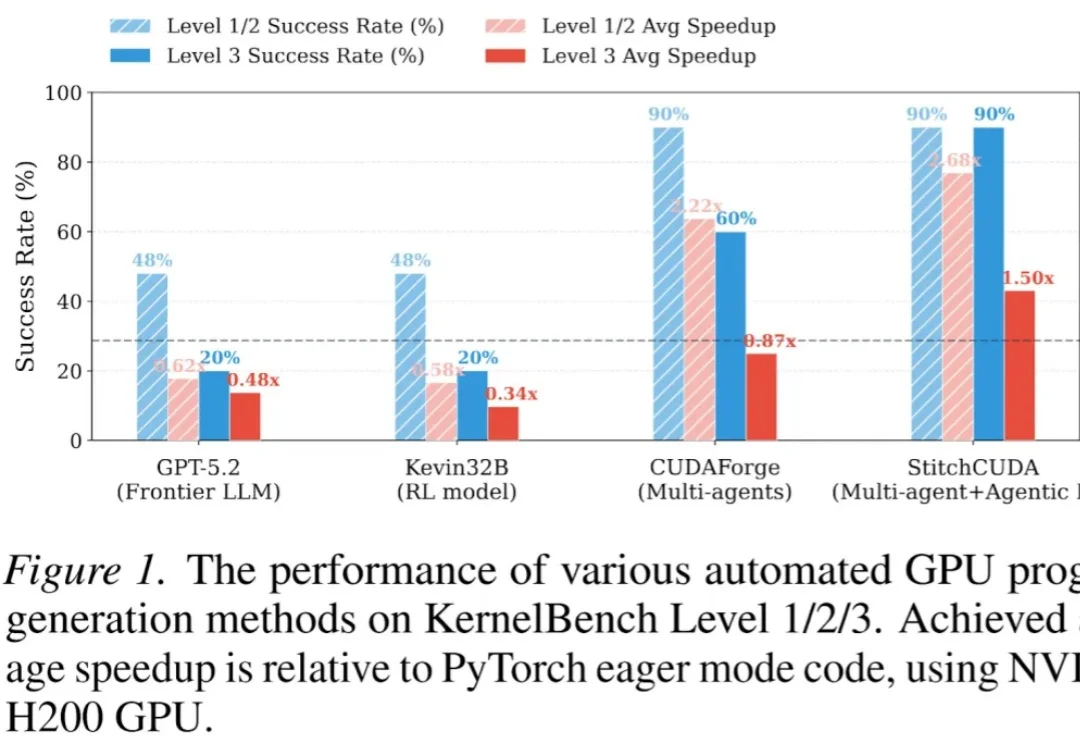
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
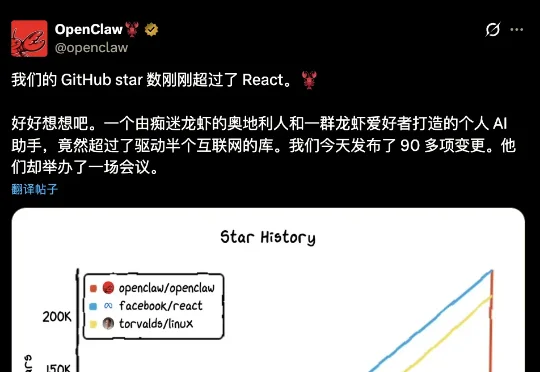
仅用两月,本地AI框架OpenClaw击败Linux,登顶GitHub星标榜!本文回顾了OpenClaw爆火之路,及其背后反映的开源社区趋势变化。