
Agent 记忆,我们全都理解错了?
Agent 记忆,我们全都理解错了?在做 Agent Memory 工程化探索的这几个月里,我经常有种被概念淹没的窒息。图结构记忆、AutoMemory、做梦机制、各种层出不穷的 Memory 框架……整个技术社区似乎陷入了一种每遇到一个新场景就要发明一套新词汇的群体焦虑中。
来自主题: AI技术研报
8167 点击 2026-06-19 09:25
 搜索
搜索
在做 Agent Memory 工程化探索的这几个月里,我经常有种被概念淹没的窒息。图结构记忆、AutoMemory、做梦机制、各种层出不穷的 Memory 框架……整个技术社区似乎陷入了一种每遇到一个新场景就要发明一套新词汇的群体焦虑中。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
昨晚,小米正式上线了Xiaomi MiMo Claw,一款云端Claw类产品,搭载与OpenClaw框架深度适配的MiMo-V2.5-Pro旗舰模型,同时联动了金山办公生态,实现一站式办公,现在可以在MiMo Studio上进行体验。
这绝对是近期把“反向创新”和“互联网幽默”玩到极致的一个案例,当整个 AI 行业都在比拼模型参数、Agent 框架、推理能力和算力规模时,一个 17 岁印度高中生却用一种近乎恶作剧的方式,创造了 2026 年最幽默的一个产品。
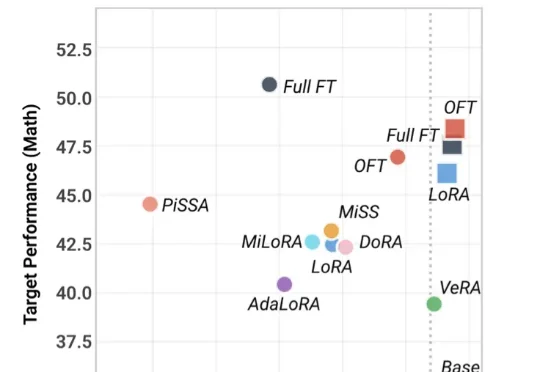
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。

香港城市大学曾晓成教授与中国石油大学(华东)钟杰教授团队给出了终结级的分子水平证据,成果发表于《Nature Physics》。他们首创了一套无监督深度学习框架,不给AI任何预设条件,直接把海量水系统中7400多万个水分子结构扔给模型,让AI自己去悟。结果不仅直接证明常压水里确实存在两种「暗」组份,还把A/B水分子相互变身的「立交桥」路线图给完整画了出来。
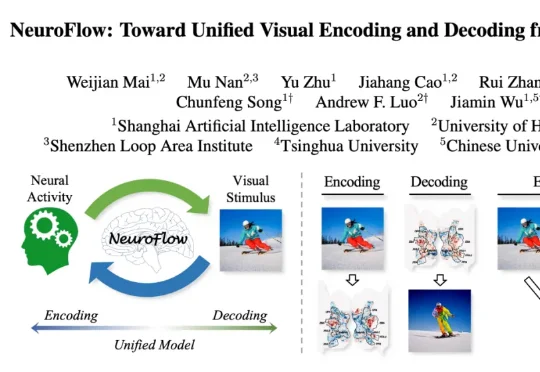
来自上海人工智能实验室、香港大学、香港中文大学等机构的研究团队,提出首个基于统一神经流模型的视觉-神经双向建模框架NeuroFlow,相关成果入选 CVPR 2026。它首次将视觉编码(写脑)与解码(读脑)整合到同一可逆流结构中,打通视觉感知与神经活动之间的双向通路,为理解人类视觉认知机制、构建下一代通用视觉假体与双向脑机接口提供了全新范式。
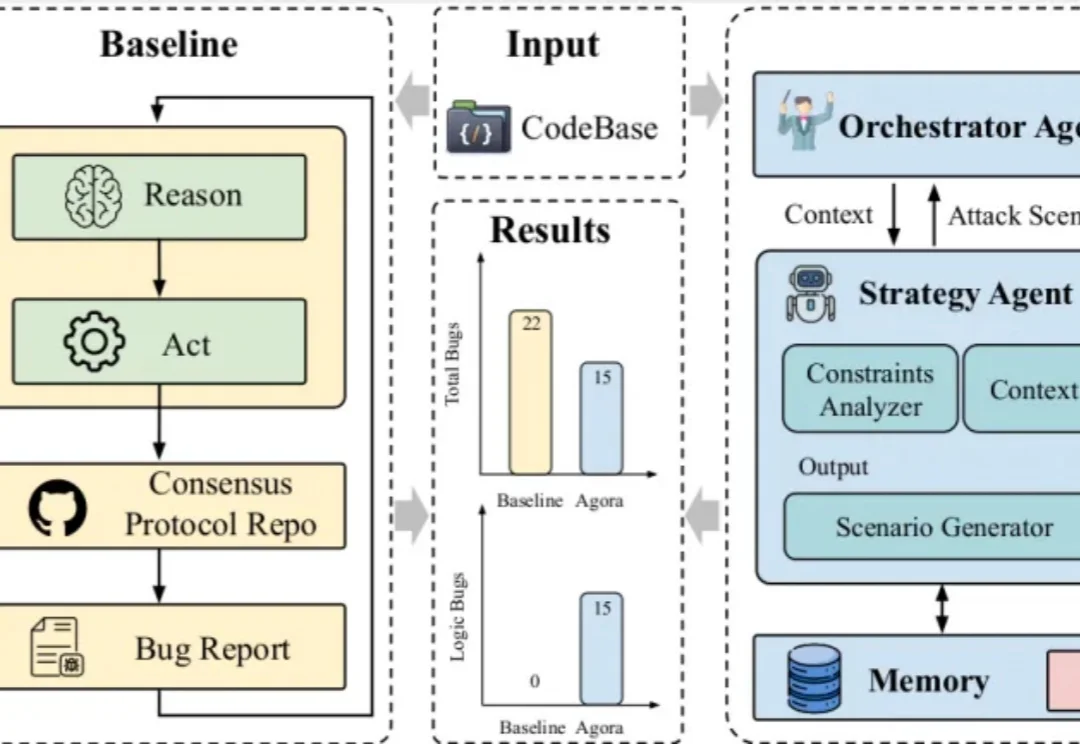
分布式系统的 “圣杯”—— 共识协议(Consensus Protocols),长久以来都是顶级基础设施工程师的 “Bug 地狱”。由于其状态极其复杂、多节点交织,传统测试和单体 LLM 对硬核的 Deep Bug(深层逻辑漏洞)几乎束手无策。
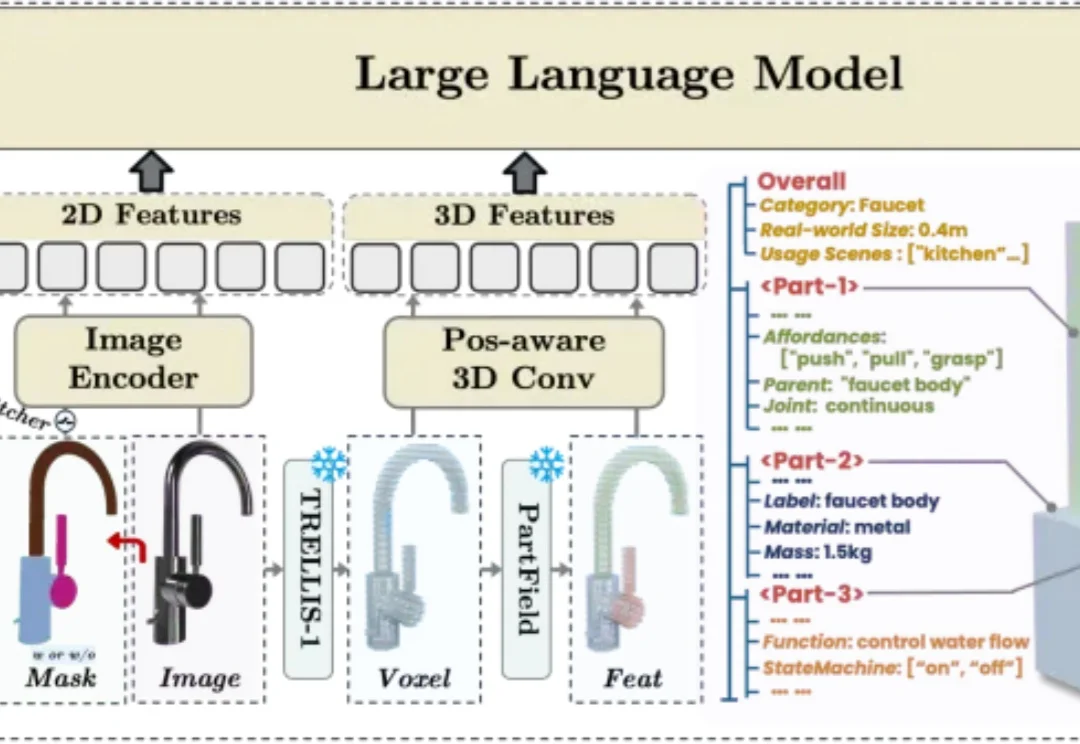
在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。