更可信、更省钱的Agent?实测OpenSquilla
更可信、更省钱的Agent?实测OpenSquilla上周有个项目,让我觉得很有意思。GitHub上一个叫OpenSquilla的,发布不到一个月,Star涨到了5300多。OpenSquilla 0.4.0,定位Token-Efficient AI Agent,是一个很有效率又很有创意的智能体框架。
来自主题: AI技术研报
9271 点击 2026-07-06 19:34
 搜索
搜索
上周有个项目,让我觉得很有意思。GitHub上一个叫OpenSquilla的,发布不到一个月,Star涨到了5300多。OpenSquilla 0.4.0,定位Token-Efficient AI Agent,是一个很有效率又很有创意的智能体框架。

乐鑫喵伴 EchoEar EchoEar 喵伴 AI 机器人搭载的 ESP-Brookesia 框架实现全双工语音交互、多模态识别与智能体控制,构建更具沉浸感的人机交互体验。 EchoEar 套件以端
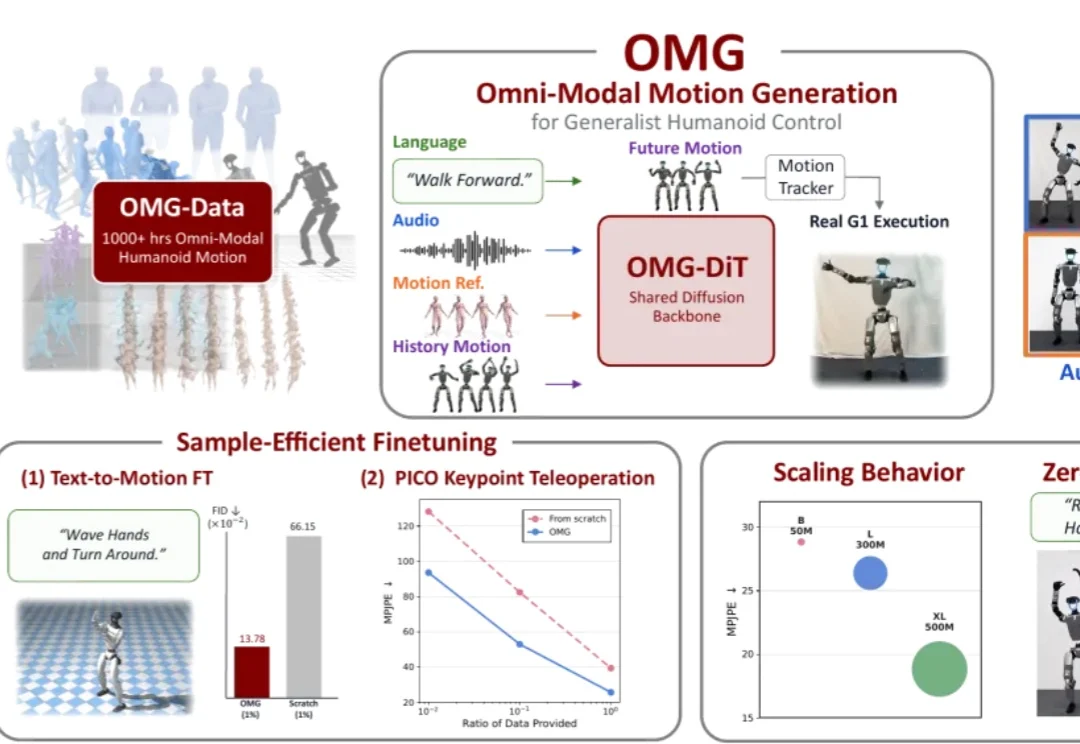
现阶段大多数人形机器人的运动控制还局限于 “有参考才能动” 的被动跟踪模式。

刚刚,DeepSeek V4 进行了一次更新。新推出了投机解码(Speculative Decoding)框架 DSpark,并同步开源了支撑该版本的全栈推测性解码框架 DeepSpec。DeepSeek-V4-Pro-DSpark 并非全新架构模型,而是在 DeepSeek-V4-Pro 基础上引入了推测性解码模块。此次更新的重点在于工程落地,而非模型能力本身的迭代。

写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。
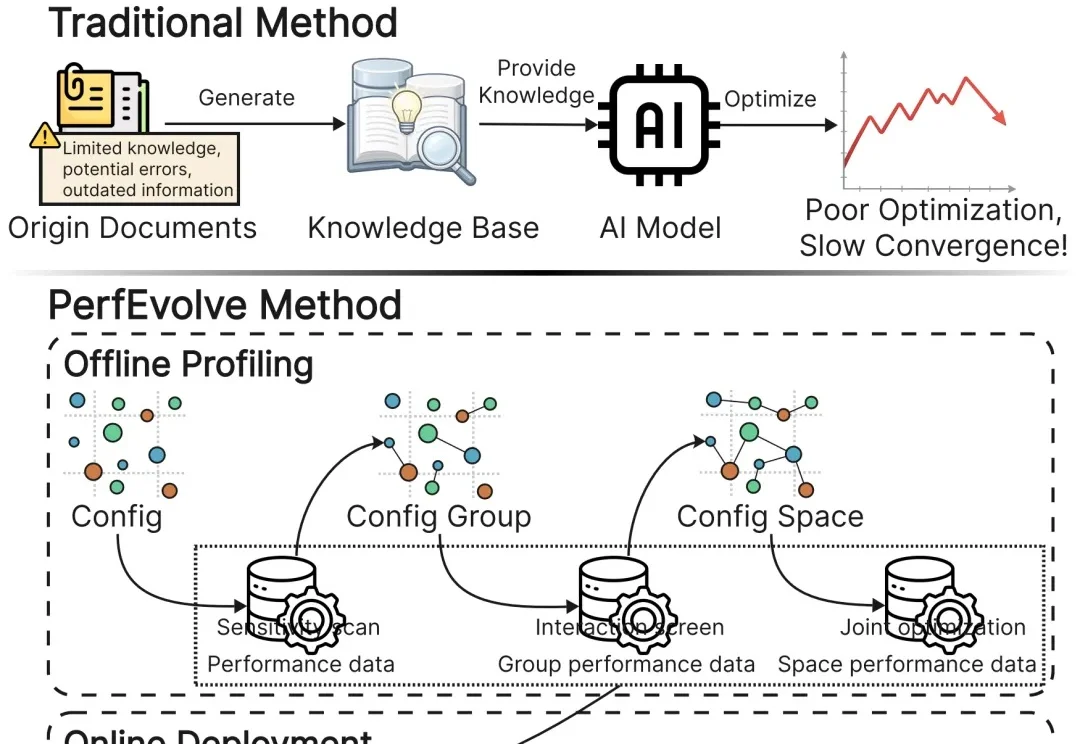
数据库自动调参,一直是大模型Agent的“看似完美、实则翻车”名场面。

近日,香港特区政府教育局公布《中小学数字教育发展蓝图》。与过去侧重设备建设和数字工具应用的信息化政策不同,这份文件把课程框架、教师培训、学校治理和资源投入放进同一套制度设计之中,为未来几年香港中小学推进人工智能教育划出了具体路线图。
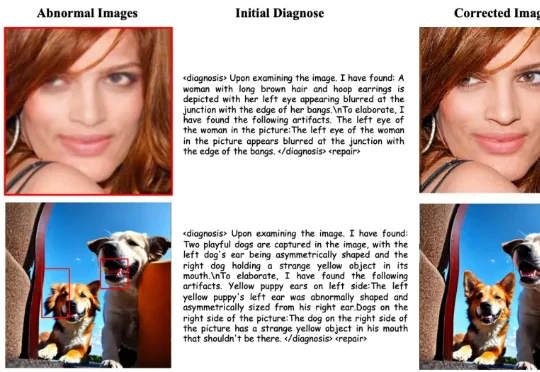
对于 AI 生成图像中可能存在的不自然伪影,我们是否不仅能够将其定位和解释,还能进一步对其进行修复,使图像恢复为更加真实、自然的视觉外观?围绕这一问题,来自北京大学等机构的研究者提出了 GenShield:一个统一的自回归框架,将 AI 生成图像检测 与 图像伪影修复 结合到同一个闭环中,实现从 “诊断” 到 “修复” 的一体化建模。

2011 年,Judea Pearl 凭借在因果推理领域的奠基性贡献获得图灵奖。他提出AI必须跨越三层:关联、干预、反事实。2018 年,他在面向大众的著作《The Book of Why》中将这一框架系统化为“因果之梯”。
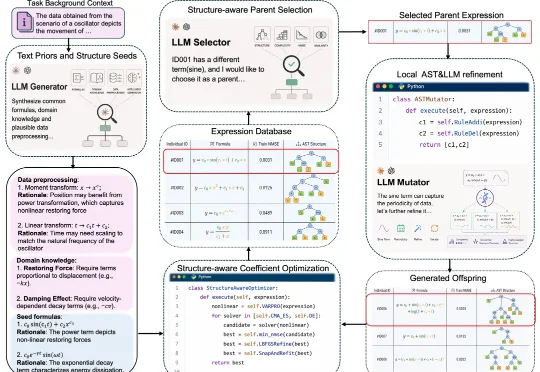
来自博世中央研究院与清华大学的研究人员提出 FunctionEvolve 框架,在两大基准测试上大幅刷新了这项任务的结果。在 LLM-SRBench 的 129 个合成科学方程任务上,FunctionEvolve 最终给出的公式在 55.8% 的任务上与真实公式等价(SA@1 = 72/129),是此前最好结果的 3.6 倍;