
机器人“狂踹不倒”视频刷屏!太空舱遍布城市街巷,银河通用这几手秀麻了
机器人“狂踹不倒”视频刷屏!太空舱遍布城市街巷,银河通用这几手秀麻了连续飞踢一台机器人30秒会发生什么?那么,是什么让这台机器人怎么踹都踹不倒呢? 答案就出自银河通用的全新通用动作追踪框架——Any2Track。
来自主题: AI技术研报
8860 点击 2025-10-06 14:02
 搜索
搜索
连续飞踢一台机器人30秒会发生什么?那么,是什么让这台机器人怎么踹都踹不倒呢? 答案就出自银河通用的全新通用动作追踪框架——Any2Track。
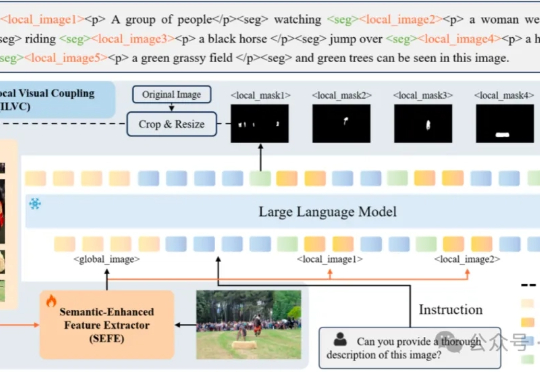
多模态大模型需要干的活,已经从最初的文生图,扩展到了像素级任务(图像分割)。

来自斯坦福大学、哥伦比亚大学、摩根大通AI研究院、卡耐基梅隆大学、英伟达提出了一种数据采集与策略学习框架DexUMI——利用人手作为自然接口将灵巧操作技能迁移至多种灵巧手。该框架通过硬件与软件的双重适配,最大限度缩小人手与各类灵巧手之间的具身差异。

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。

AI生成第三视角视频已经驾轻就熟,但第一视角生成却仍然“不熟”。为此,新加坡国立大学、南洋理工大学、香港科技大学与上海人工智能实验室联合发布EgoTwin ,首次实现了第一视角视频与人体动作的联合生成。
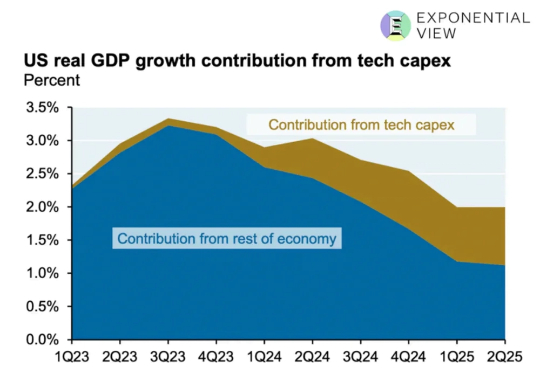
AI投资热潮是否形成泡沫?作者提出一个实用框架,用五个指标(经济压力、行业压力、收入增长、估值热度、资金质量)分析当前状况,对比铁路、电信和互联网历史泡沫。结论显示AI投资尚未泡沫,属于需求驱动的繁荣,但需警惕GPU快速折旧和数据中心融资风险。未来需监控收入增长是否能持续覆盖投资。
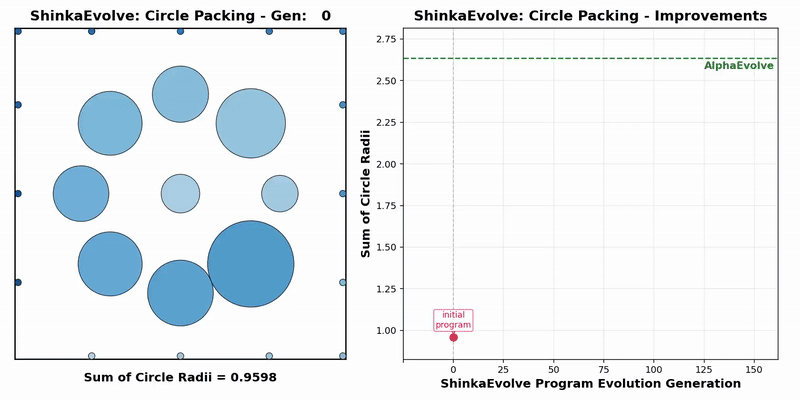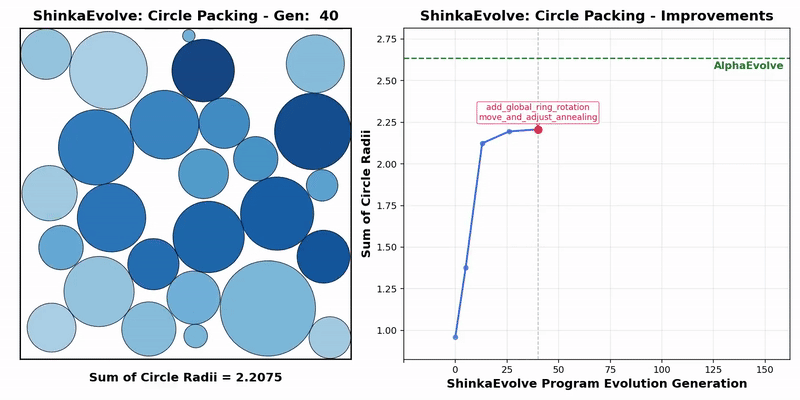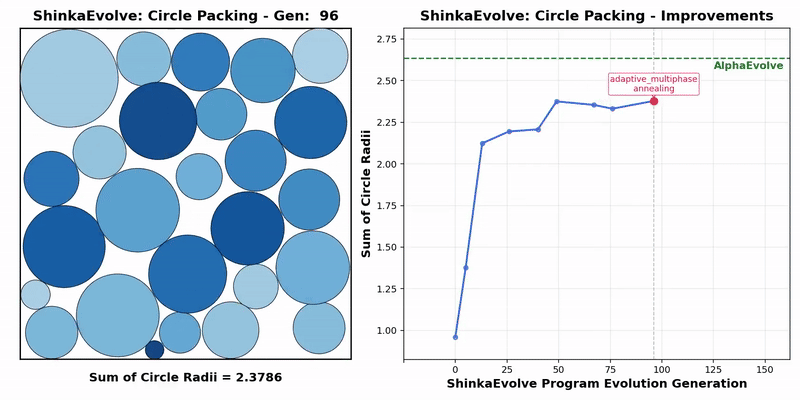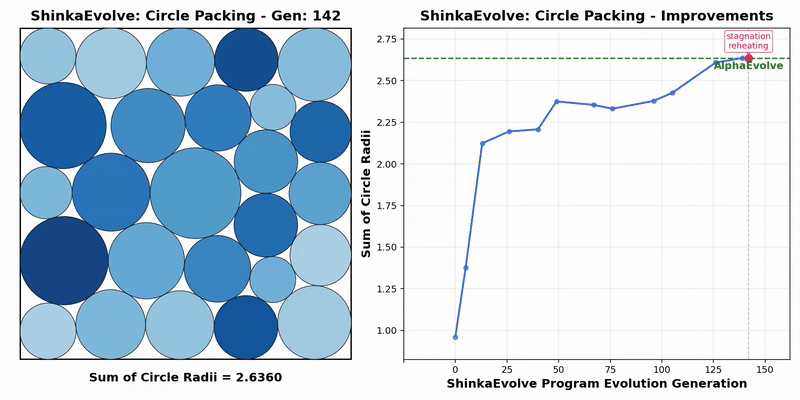
Transformer作者Llion Jones带着自己的初创公司Sakana AI,又来搞事情了。(doge)最新推出的开源框架——ShinkaEvolve,可以让LLM在自己写代码优化自己的同时,还能同时兼顾效率,be like为进化计算装上一个“加速引擎”。
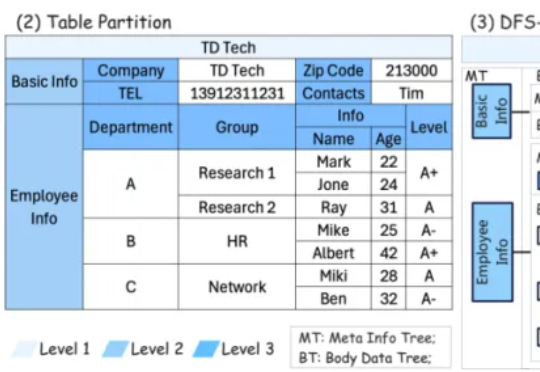
来自上海交通大学计算机学院、西蒙菲莎大学、清华大学、中国人民大学的合作团队,带来基于树形框架的智能表格问答系统(ST-Raptor),其不仅能精准捕捉表格中的复杂布局,还能自动生成表格操作指令,并一步步执行这些操作流程,最终准确回答用户提出的问题 —— 就像给 Excel 装上了一个会思考的 “AI 大脑”。

由华中科技大学与小米汽车提出了业内首个无需 OCC 引导的多模态的图像 - 点云联合生成框架 Genesis。该算法只需基于场景描述和布局(包括车道线和 3D 框),就可以生成逼真的图像和点云视频。
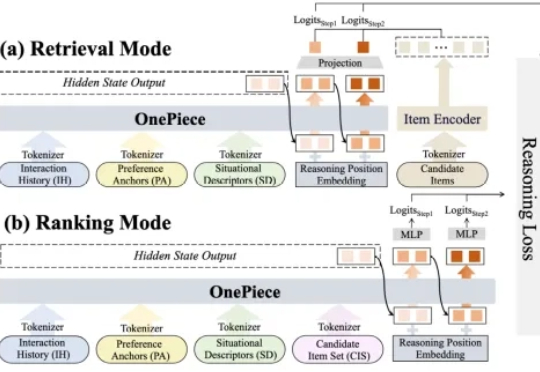
2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。