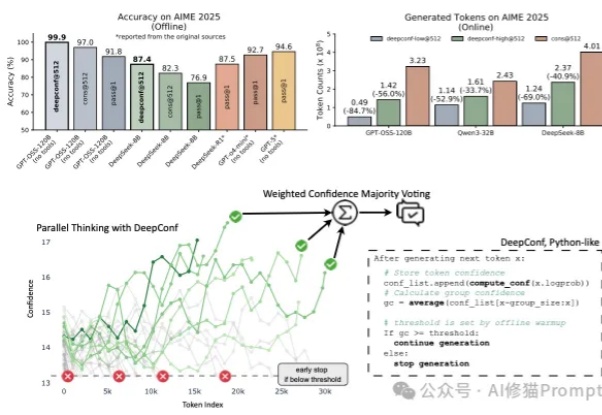
不微调,让LLM推理准确率暴增到99%!试下DeepConf,一个轻量级推理框架|Meta最新
不微调,让LLM推理准确率暴增到99%!试下DeepConf,一个轻量级推理框架|Meta最新在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。
来自主题: AI技术研报
7479 点击 2025-09-09 10:17
 搜索
搜索
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。
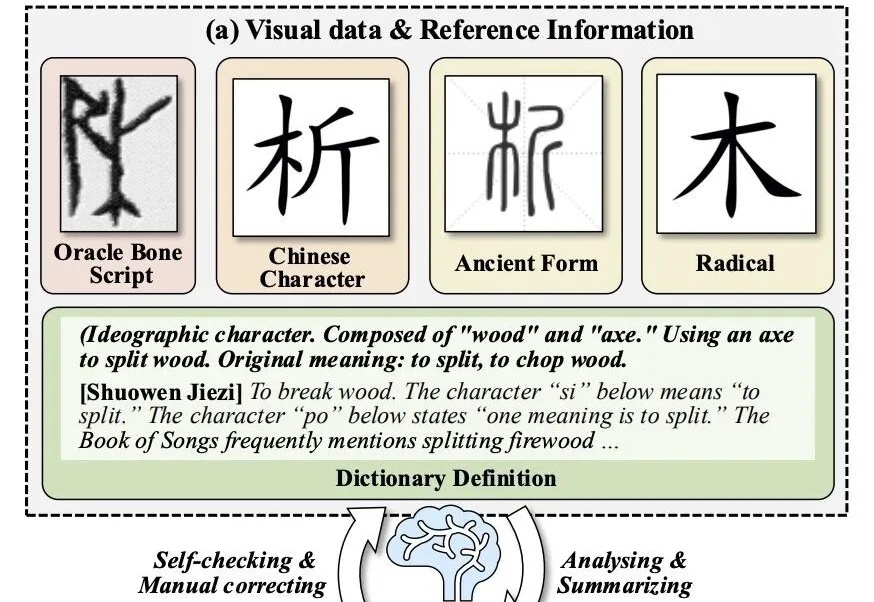
让大模型破译从未见过的甲骨文,准确率拿下新SOTA!
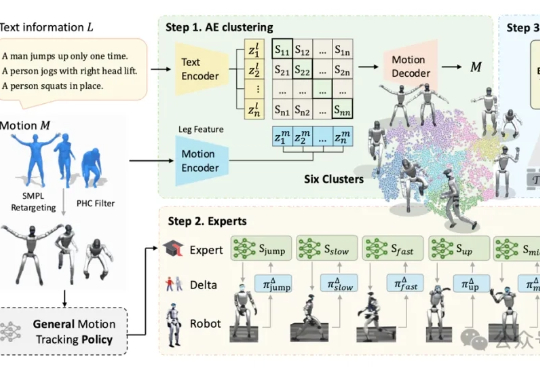
人形机器人对跳舞这件事,如今是越来越擅长了。北京大学与BeingBeyond团队联合研发的BumbleBee系统给出了最新答案:通过创新的“分治-精炼-融合”三级架构,该系统首次实现人形机器人在多样化动作中的稳定控制。

这并非科幻片中的桥段,而是来自清华大学与北京航空航天大学团队的最新成果——BSC-Nav 的真实演示。通过模仿生物大脑构建、维护空间记忆的原理,研究团队让智能体拥有了前所未有的「空间感」。
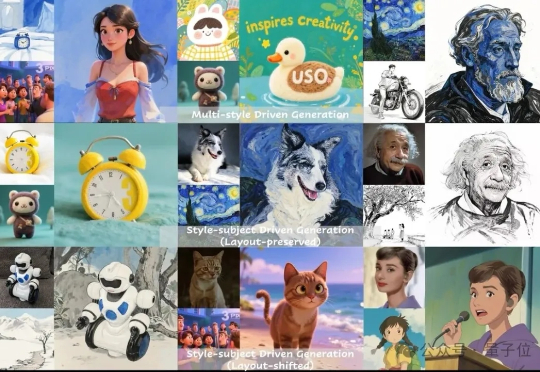
图像生成中的多指标一致性问题,被字节团队解决了! 字节UXO团队设计并开源了统一框架USO,让看上去不关联的任务相互促进,实现风格迁移和主体保持单任务和组合任务的SOTA。
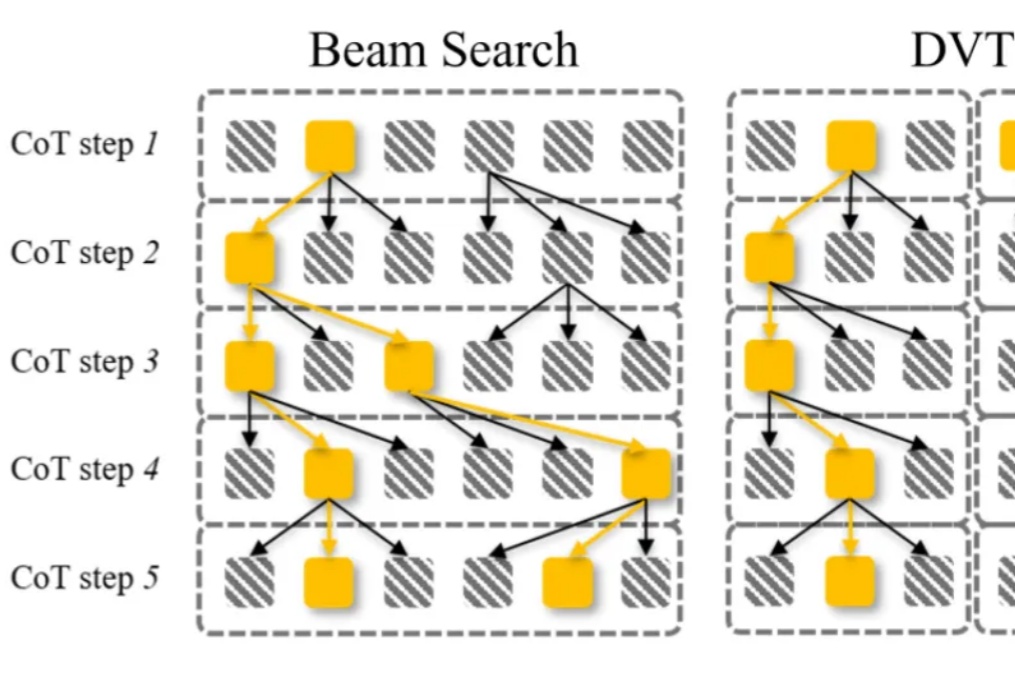
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。
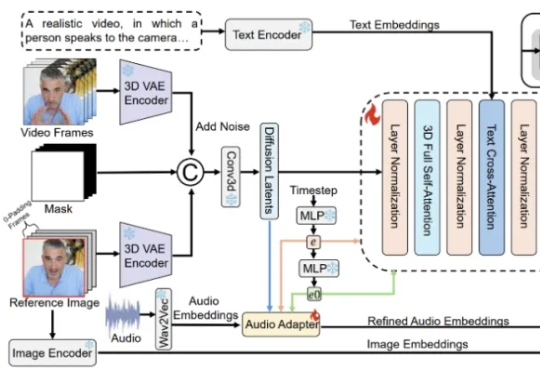
在《流浪地球 2》中图恒宇将 AI 永生数字生命变为可能,旨为将人类意识进行数字化备份并进行意识上传,以实现人类文明的完全数字化。
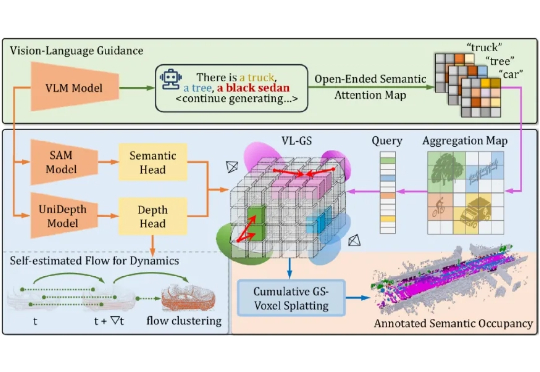
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。
AI加速走向落地,企业「超级大脑」却在关键时刻断片?行业亟需一套能够持续进化、越用越聪明的系统框架,实现多智能体协同作战,通过自优化、自反馈瞬间激活知识库。清华系黑马已将其塞进AI原生引擎,率先在能源、军工等硬核场景中规模化落地,为产业智能升级提供了可靠路径。