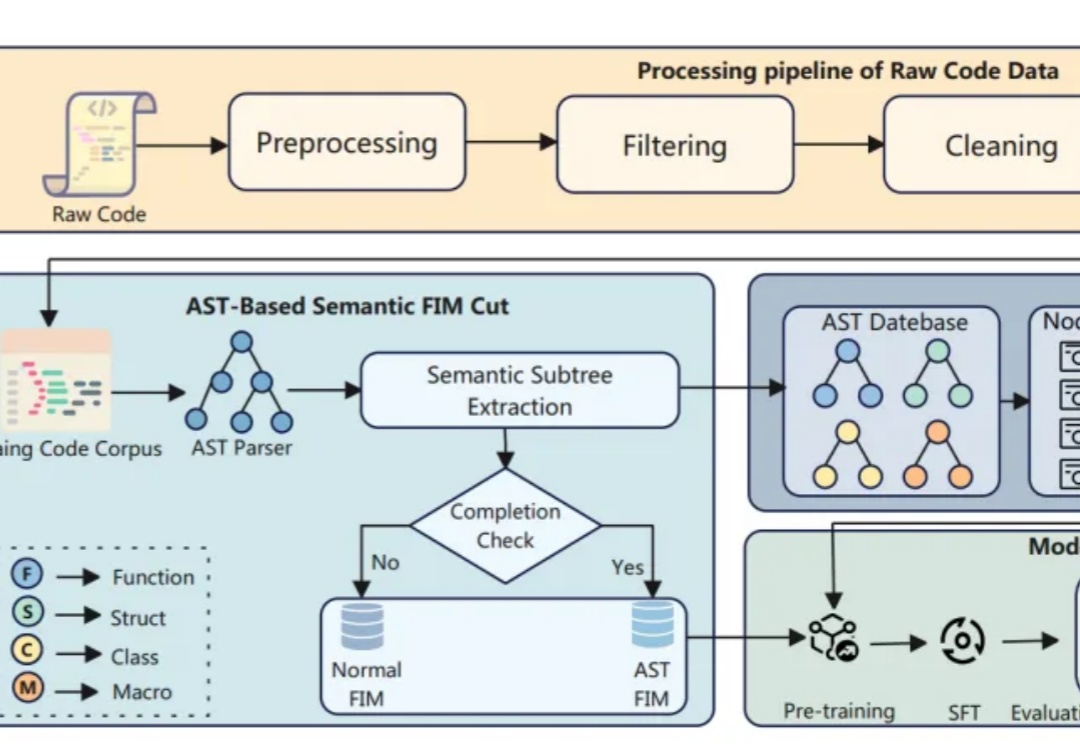
AI代码补全哪家强?两个新指标+一套新框架,让模型更懂开发者
AI代码补全哪家强?两个新指标+一套新框架,让模型更懂开发者如何让AI代码补全更懂开发者?
来自主题: AI技术研报
9494 点击 2025-06-13 11:02
 搜索
搜索
如何让AI代码补全更懂开发者?

普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。

在A100上用310M模型,实现每秒超30帧自回归视频生成,同时画面还保持高质量!
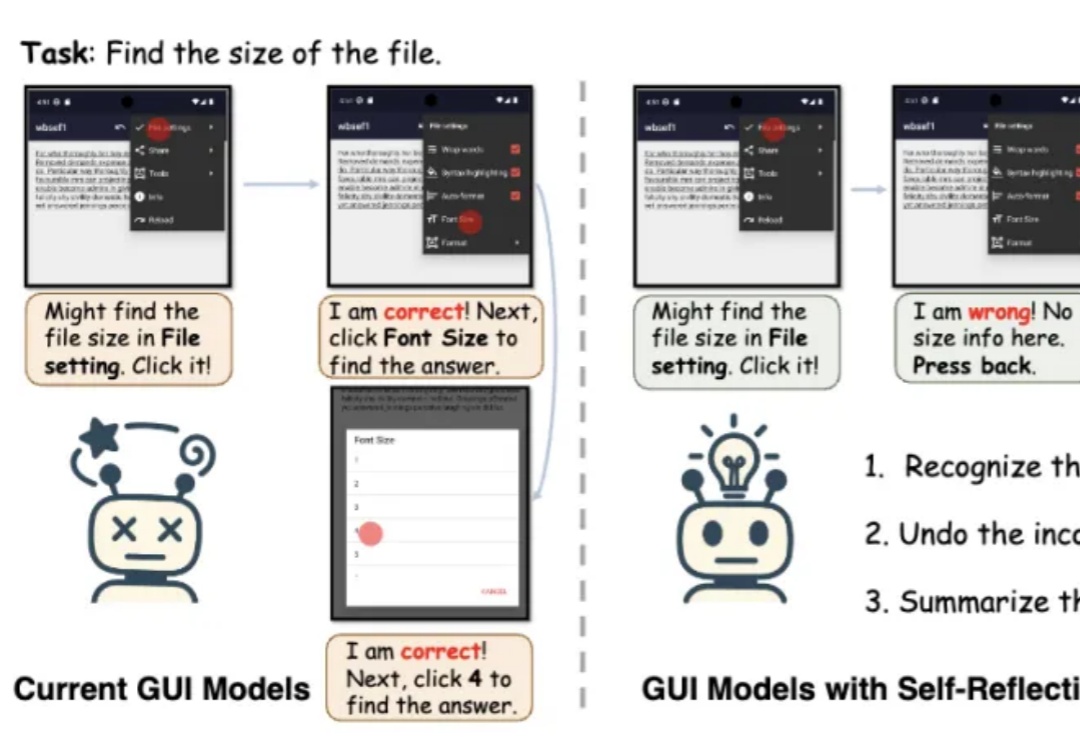
端到端多模态GUI智能体有了“自我反思”能力!南洋理工大学MMLab团队提出框架GUI-Reflection。

近年来,大语言模型(LLM)以其卓越的文本生成和逻辑推理能力,深刻改变了我们与技术的互动方式。然而,这些令人瞩目的表现背后,LLM的内部机制却像一个神秘的“黑箱”,让人难以捉摸其决策过程。

以神经网络为核心引擎,让AI承担雷达仿真数据生成任务,还实现对雷达物理特性的建模与控制——

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。
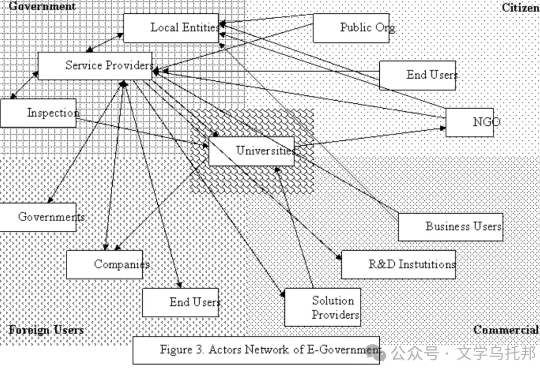
从ANT视角思考文学、AI与人的三组关系,可以通过“拟-对象”克服“AI替代人类”、工具论等人机关系论中隐藏的二元框架,用合成主义方式化解文学与AI关系背后的“两种文化”之争,从行动者-网络角度重思人与文学关系中文学的终结和新生
该项目来自百家 AI,是北京邮电大学白婷副教授所指导的研究小组, 团队致力于为硅基人类倾力打造情感饱满、记忆超凡的智慧大脑。

多模态检索是信息理解与获取的关键技术,但其中的跨模态干扰问题一直是一大难题。