GUI Agent「记与学」双修,长程任务有了专属记忆增强型自进化框架
GUI Agent「记与学」双修,长程任务有了专属记忆增强型自进化框架本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。
来自主题: AI技术研报
7863 点击 2026-06-02 11:23
 搜索
搜索
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

绝大多数 AI 陪伴产品,都是基于通用模型的使用,利用提示词框架对模型进行定向约束,所以角色的表达仍然停留在「人类平均水平」,本质都是提示词驱动下的角色扮演。但陆弘毅做蕾伊的方法完全不同。团队先为她写了几十万字的人格语料,确定她从小到大的经历、行为与反应、深层性格和内在冲突,再把这些只属于蕾伊的数据灌进他们自研的「超人格化模型」。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。
![[翻译] AI Agent 的 Zero Trust 框架|Anthropic 安全白皮书](https://www.aitntnews.com/pictures/2026/5/28/a5aa95a5-5a65-11f1-add0-fa163e47d677.webp)
Zero Trust 是一套安全架构,核心前提很简单:不信任任何东西,必须验证一切

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。
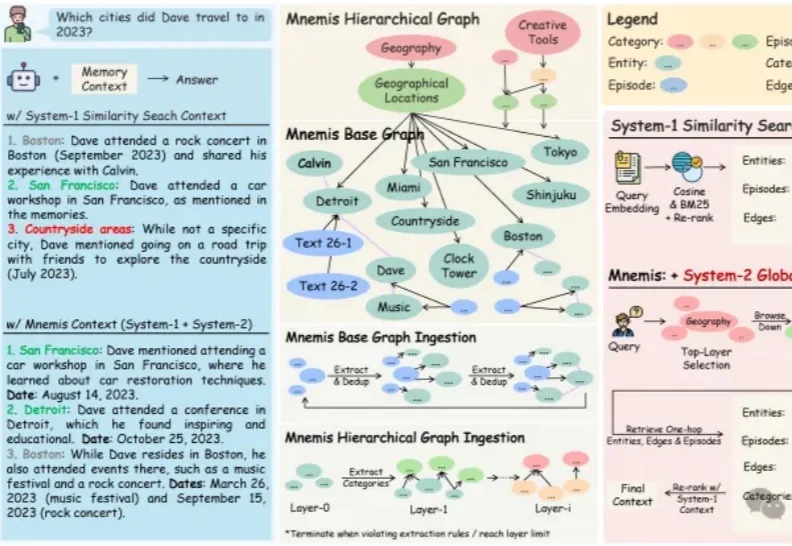
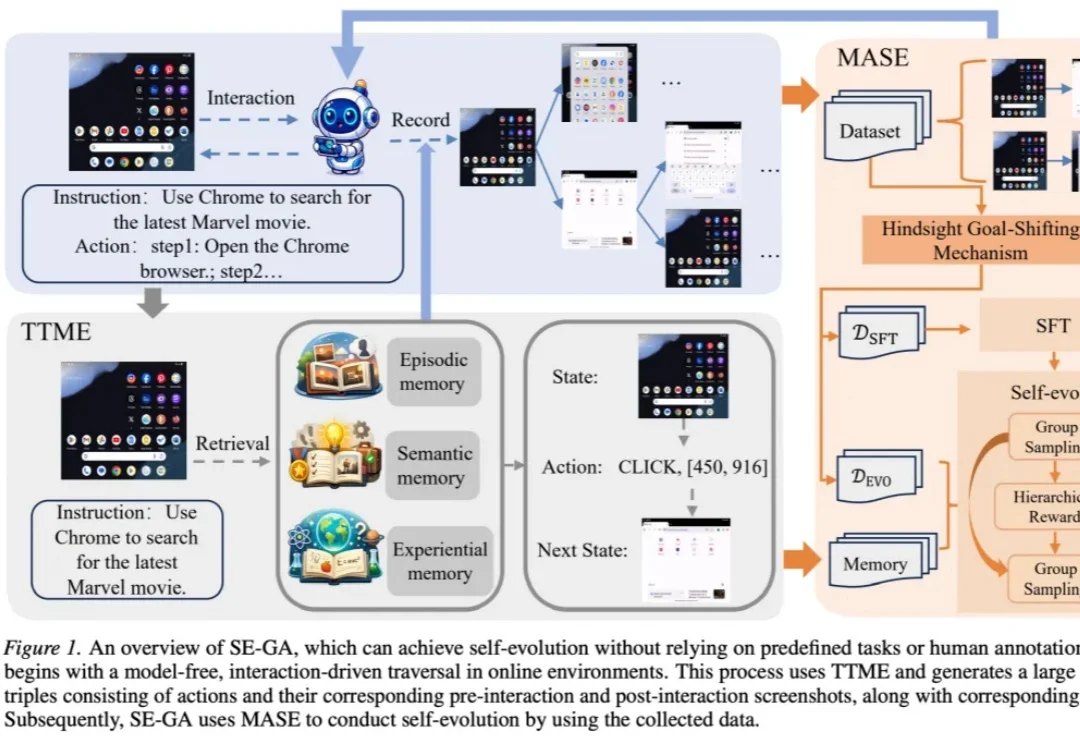
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。
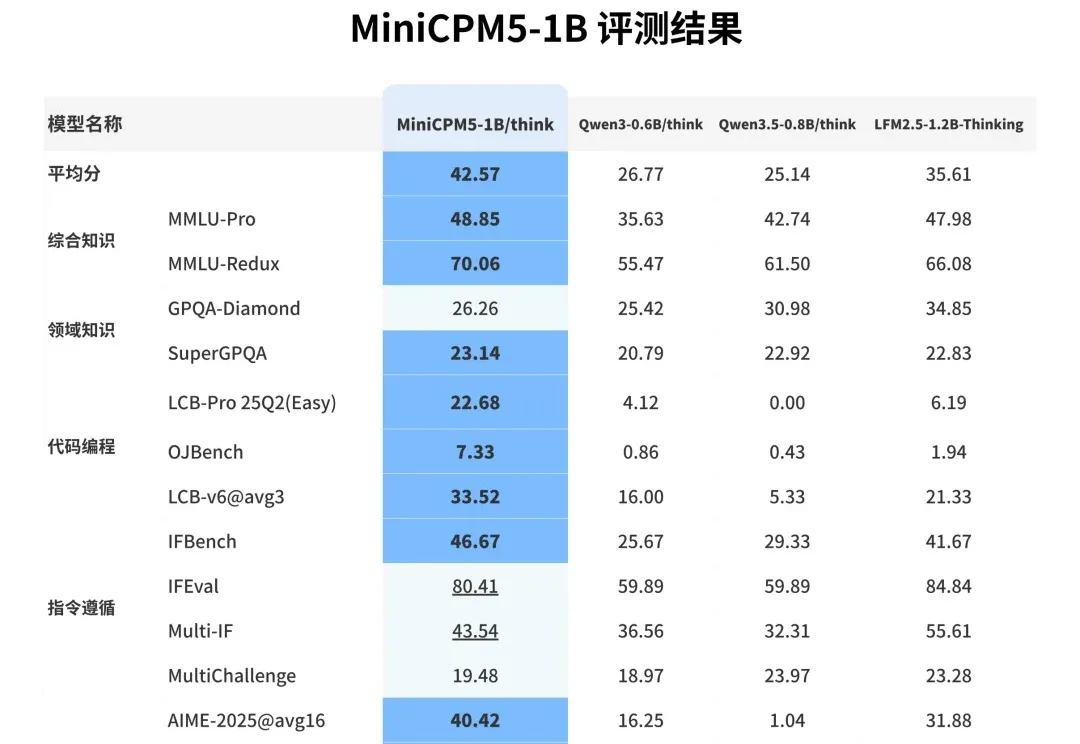
你的电脑里,或许很快会住进一只会聊天的「小怪兽」。

造AI这件事,现在的主角变成了AI。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
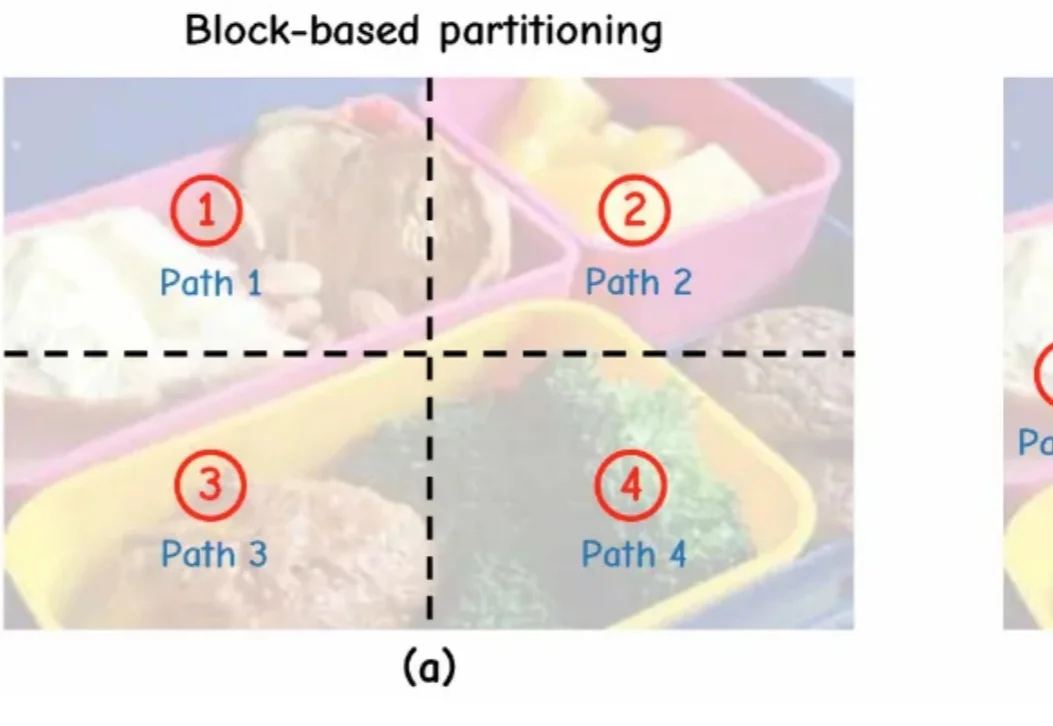
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。