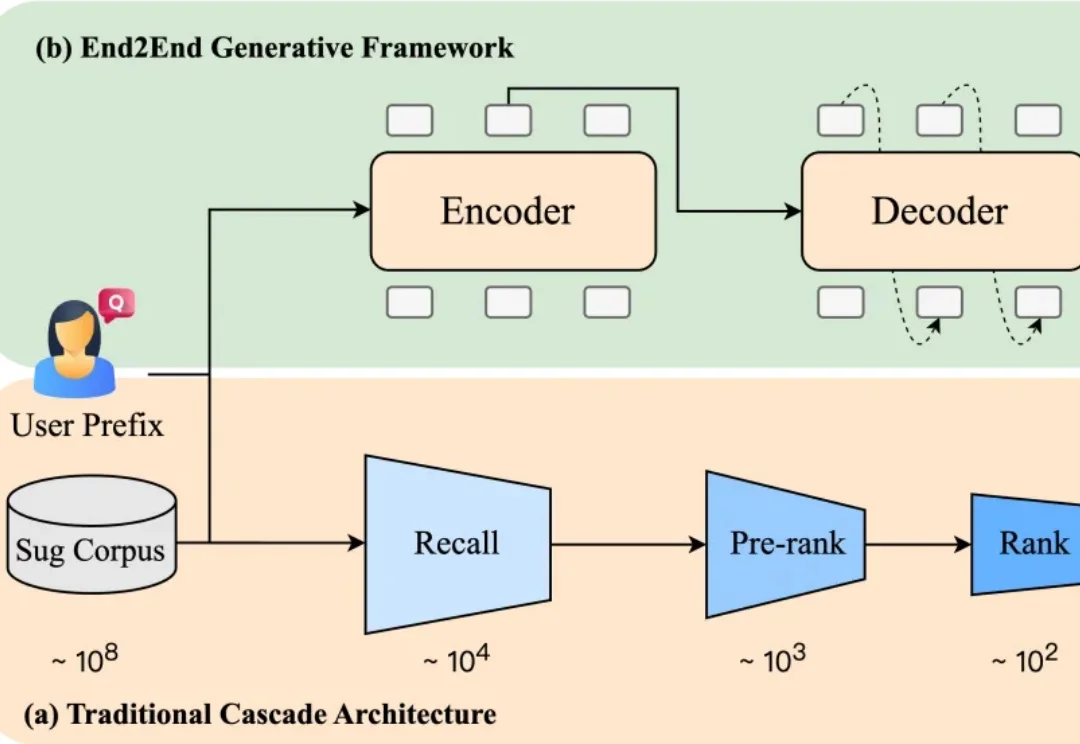
效果、性能双突破,快手OneSug端到端生成式框架入选AAAI 2026
效果、性能双突破,快手OneSug端到端生成式框架入选AAAI 2026当你在电商平台搜索“苹果”,系统会推荐“水果”还是“手机”?或者直接跳到某个品牌旗舰店?短短一个词,背后承载了完全不同的购买意图。而推荐是否精准,直接影响用户的搜索体验,也影响平台的转化效率。
来自主题: AI技术研报
10982 点击 2026-01-19 15:15
 搜索
搜索
当你在电商平台搜索“苹果”,系统会推荐“水果”还是“手机”?或者直接跳到某个品牌旗舰店?短短一个词,背后承载了完全不同的购买意图。而推荐是否精准,直接影响用户的搜索体验,也影响平台的转化效率。
随着 AI 技术的蓬勃发展, AI 模型的参数规模和推理频次呈指数级增长。据高盛研究部预测,到 2030 年,全球数据中心的电力需求将增长 160%。
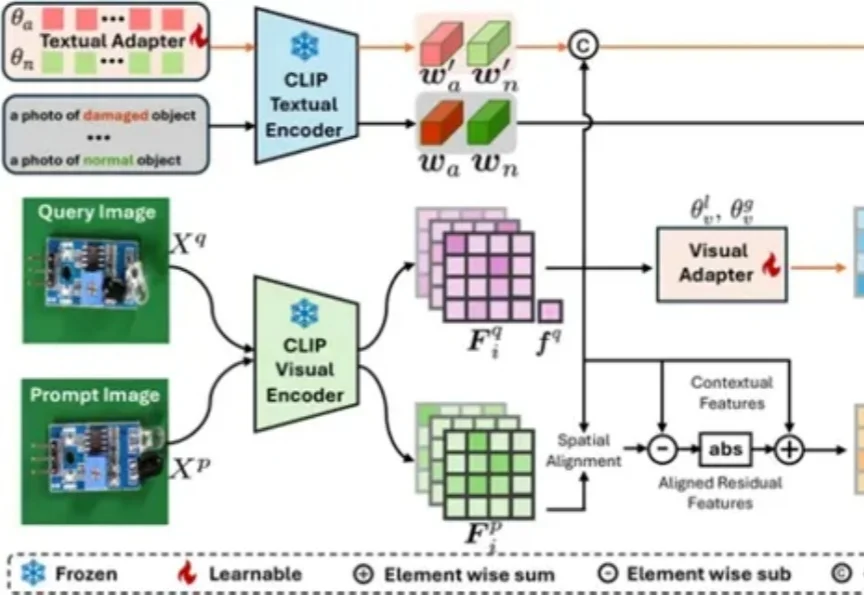
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。

真正的突破在于让模型学会"举一反三",在3-4个突变位点的平衡木上演绎生命的无限可能。
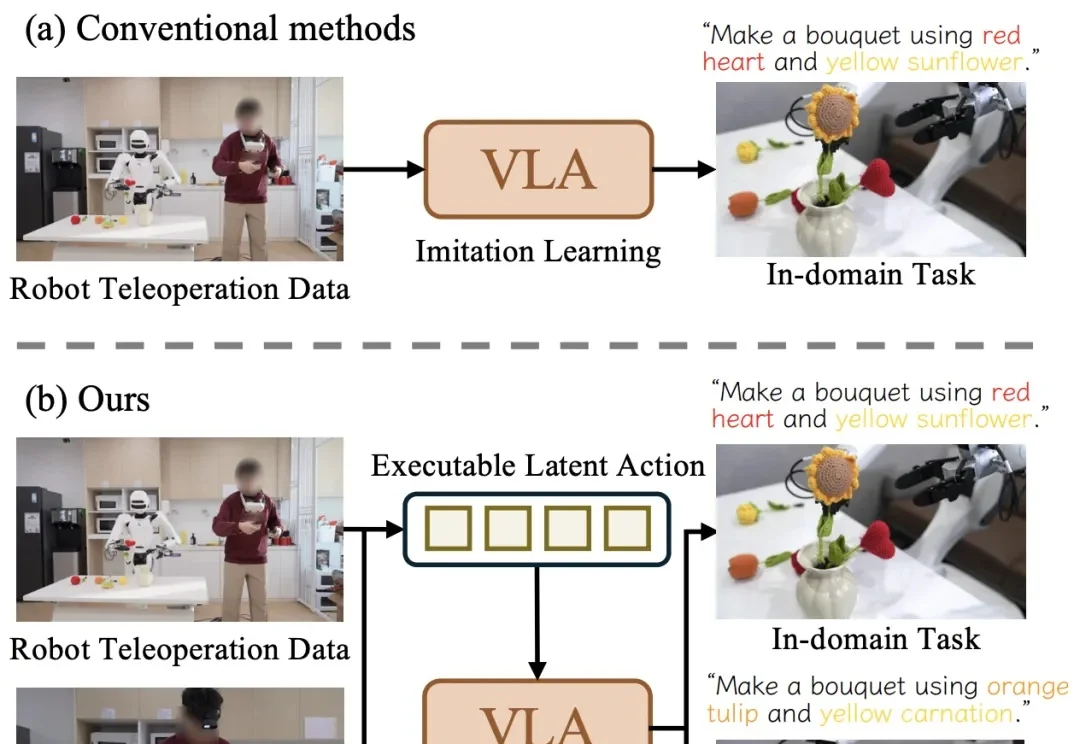
近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!

当国内的AI大模型战场正陷入“百模大战”的焦灼,巨头们还在比拼参数规模、长文本处理能力和代码生成率时,一家曾经被打上“在线教育”和“题库工具”深深烙印的公司——作业帮,却在海外市场“悄悄”通过一条意想不到的赛道杀出了重围。
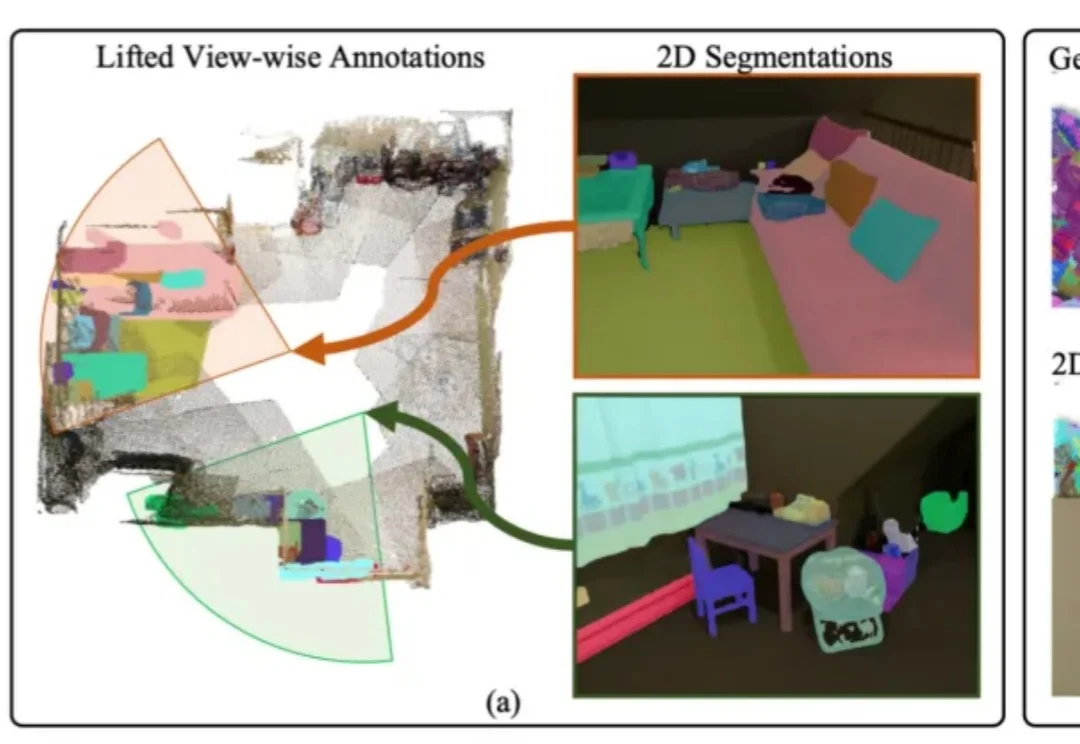
3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。

视频世界模型领域又迎来了新的突破!

北邮最新综述探讨了文生图扩散模型的可控生成技术,总结了在文本条件之外引入新条件信号的方法,从任务和方法两个层面梳理了可控生成技术。
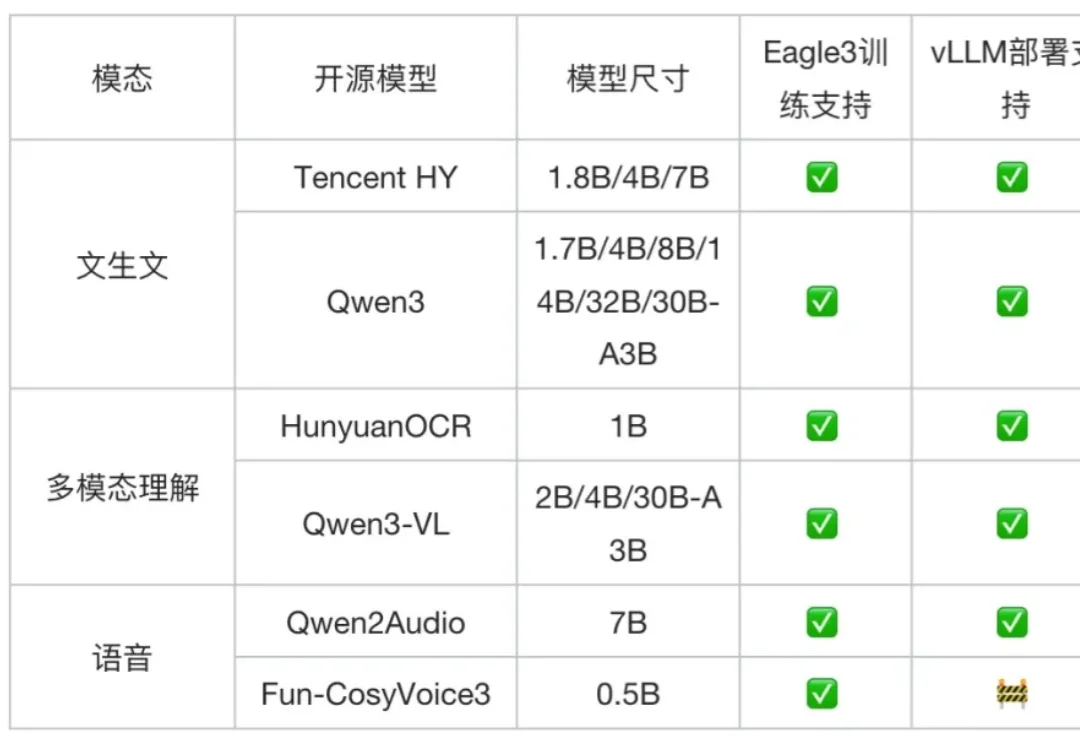
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。