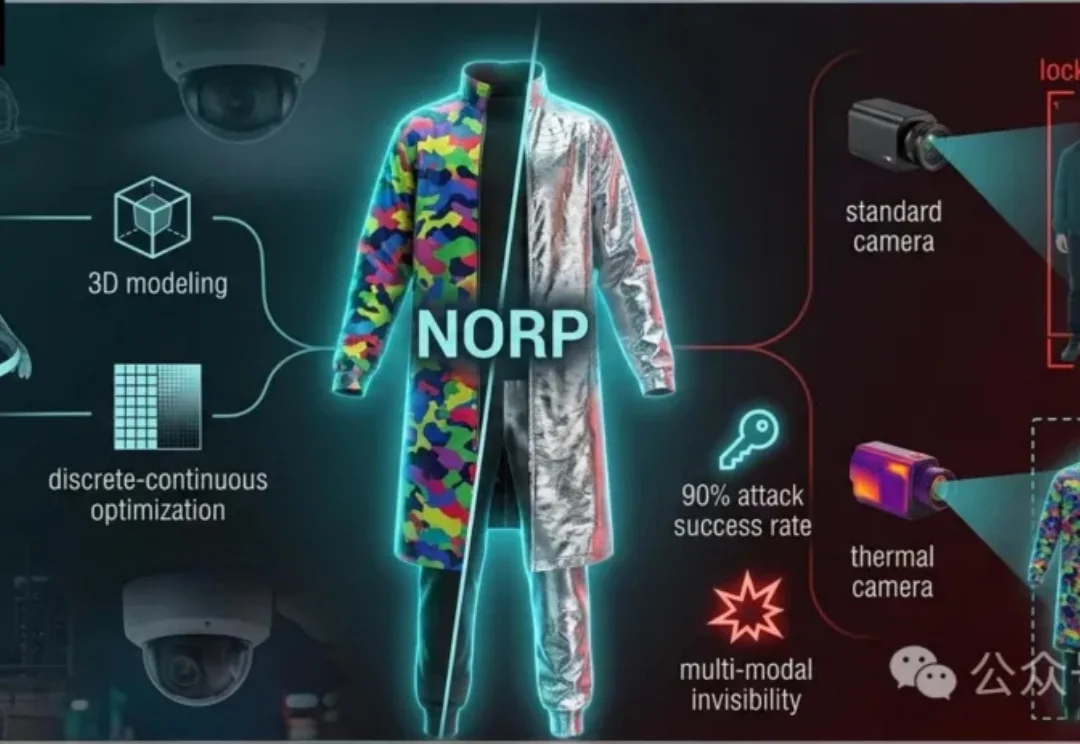
一件衣服「隐身」可见光-热成像检测器,清华多模态对抗新方法
一件衣服「隐身」可见光-热成像检测器,清华多模态对抗新方法清华大学提出一种新型物理对抗方法,利用特殊服装同时干扰可见光和热成像检测。这种服装通过非重叠设计和三维建模优化,可有效躲避RGB-T检测器,促进系统安全性研究。
来自主题: AI技术研报
7787 点击 2026-06-09 09:37
 搜索
搜索
清华大学提出一种新型物理对抗方法,利用特殊服装同时干扰可见光和热成像检测。这种服装通过非重叠设计和三维建模优化,可有效躲避RGB-T检测器,促进系统安全性研究。
最近Max Leiter写了一篇文章《它们是权重做的》:https://maxleiter.com/blog/weights 专门用来调侃大模型,我看了以后,觉得虽然有趣,但是不太符合国人的阅读习惯,就重新写了一遍,希望大家喜欢。
就在刚刚,Siri借谷歌的1.2万亿参数Gemini「重生」了!在今夜的苹果WWDC 2026上,Siri彻底迎来新生。结合设备端小模型,苹果打造了混合智能架构,让Siri在各个APP之间无缝穿梭。

今天,“港股AGI第一股”云知声发布其最新通用大语言模型U2,该模型是由云知声自研的、基于快慢思考融合的MoE(混合专家)范式构建的通用大语言模型。U2跳出了传统大模型盲目堆参数、堆Token的内卷路径,实现了“小参数强能力、少Token高产出、低算力低成本”的进化。
6月8日,高德重磅发布了全球首个3D原生城市世界模型——ABot-Earth0.5。ABot-Earth0.5的发布不仅宣告着城市级场景3D原生技术的重要突破,更彻底重塑了传统3D建模的生产逻辑与成本结构。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

过去两年,“AI 游戏”很大程度上还停留在一键生成 Demo 阶段:输入一句提示词,几秒钟生成一个能试玩几分钟的小作品,适合传播和展示模型能力,但很难留下真正的玩家和商业化结果。
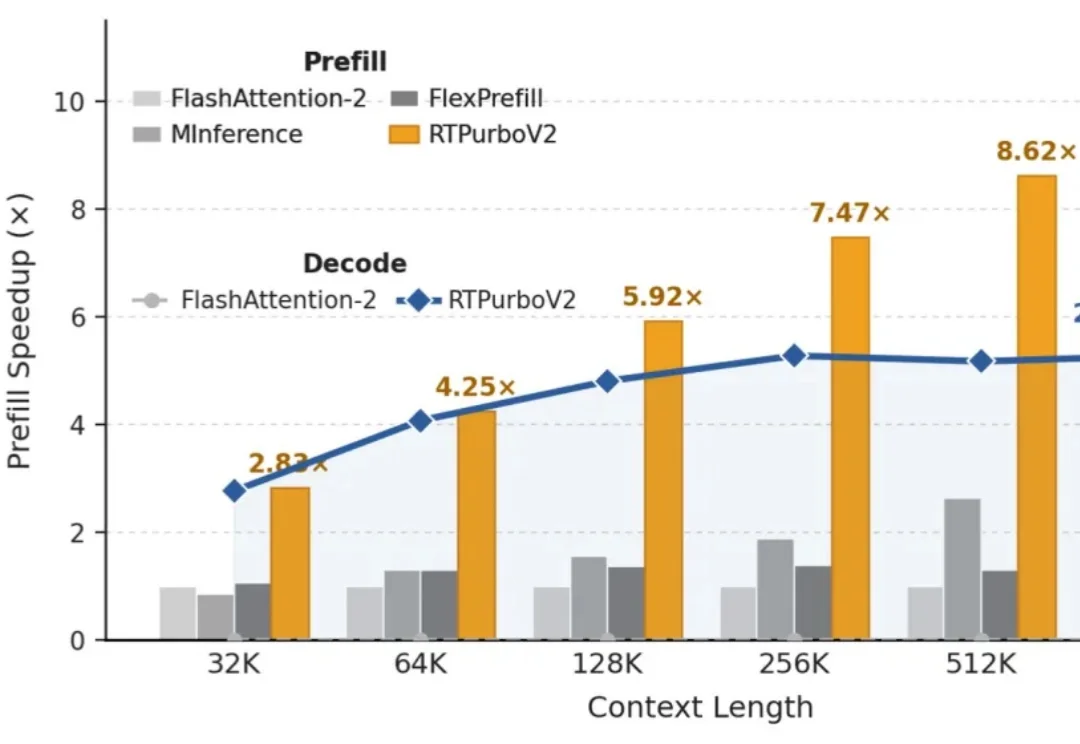
“Full Attention 正在被遗忘”

2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。

当具身智能行业还在密集PoC、卷demo、拼概念时,原力灵机先把答案押向了一个具体动作。