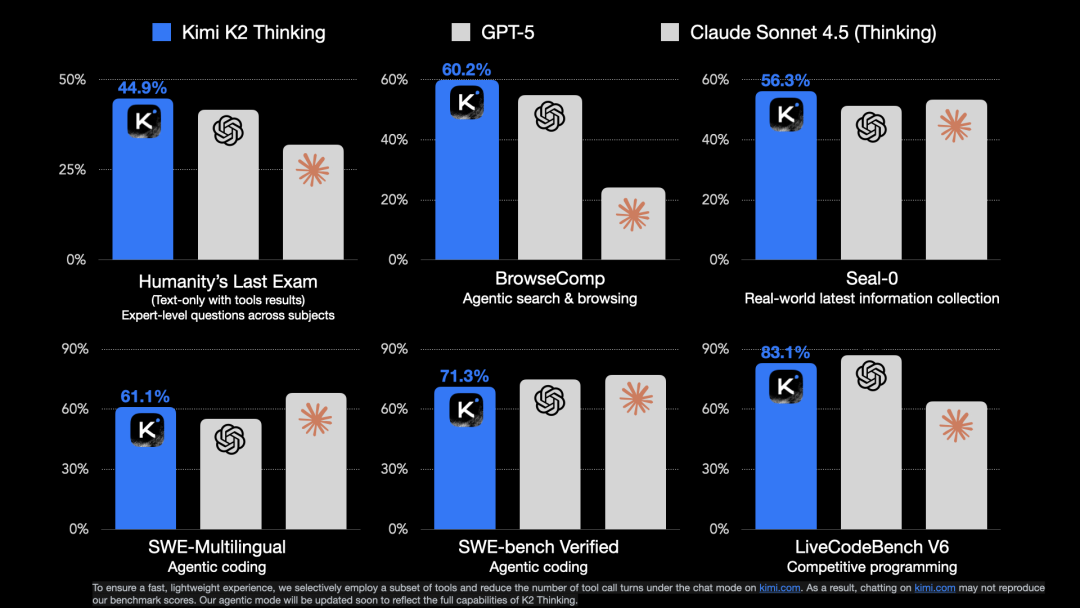
刚刚月之暗面发布Kimi K2 Thinking模型,藏师傅首测教你用 Kimi 编程全家桶
刚刚月之暗面发布Kimi K2 Thinking模型,藏师傅首测教你用 Kimi 编程全家桶四个月前 Kimi 发布了 K2 模型,凭借优秀的质量以及先进的架构优化,一举打破了持续了几个月关于月之暗面的质疑。 我当时也写了两篇测评《Kimi K2 详测|超强代码和Agent 能力!内附Cla
来自主题: AI产品测评
14421 点击 2025-11-07 08:09
 搜索
搜索
四个月前 Kimi 发布了 K2 模型,凭借优秀的质量以及先进的架构优化,一举打破了持续了几个月关于月之暗面的质疑。 我当时也写了两篇测评《Kimi K2 详测|超强代码和Agent 能力!内附Cla
你是否想过,未来的 AI 将会是什么样子?

大模型一个token一个token生成,效率太低怎么办?

机器人使用灵巧手帮人类在工厂里拧螺丝,在家里切菜做饭的一天何时可以到来?为了实现这一愿景,旨在解决灵巧操作技能 sim-to-real 难题的 DexNDM 应运而生。

当AI能写诗、能编程,甚至能和你争论哲学,它会不会真的“有感觉”?它会不会像你一样,体验到红色的炙热或痛苦的尖锐?
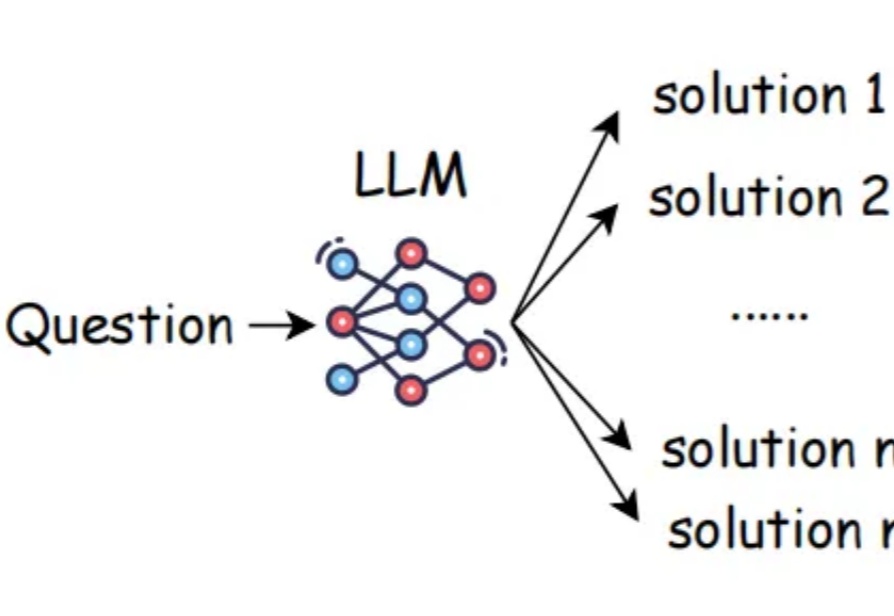
在大语言模型(LLM)席卷各类复杂任务的今天,“测试时扩展”(Test-Time Scaling,TTS)已成为提升模型推理能力的核心思路 —— 简单来说,就是在模型 “答题” 时分配更多的计算资源来让它表现更好。严格来说,Test-Time Scaling 分成两类:

2025年11月4日,一家总部位于英国伦敦的人工智能公司Stability AI,赢得了一项具有里程碑意义的高等法院案件,该案审查了人工智能模型在未经许可的情况下使用大量受版权保护数据的合法性。而本案的原告,Getty Images 在针对人工智能公司 Stability AI 图像生成产品的英国诉讼中基本败诉。

微调超大参数模型,现在的“打开方式”已经大变样了: 仅需2-4 张消费级显卡(4090),就能在本地对DeepSeek 671B乃至Kimi K2 1TB这样的超大模型进行微调了。

这年头,AI 创造的视觉世界真是炫酷至极。但真要跟细节较真儿,这些大模型的「眼力见儿」可就让人难绷了。

在日常使用电脑时,看着屏幕、点击鼠标是再自然不过的基本操作。但这种对人类明明很容易的操作方式,却成为 AI 的巨大挑战:它们视力差、动作慢、不擅长看也不擅长点。