
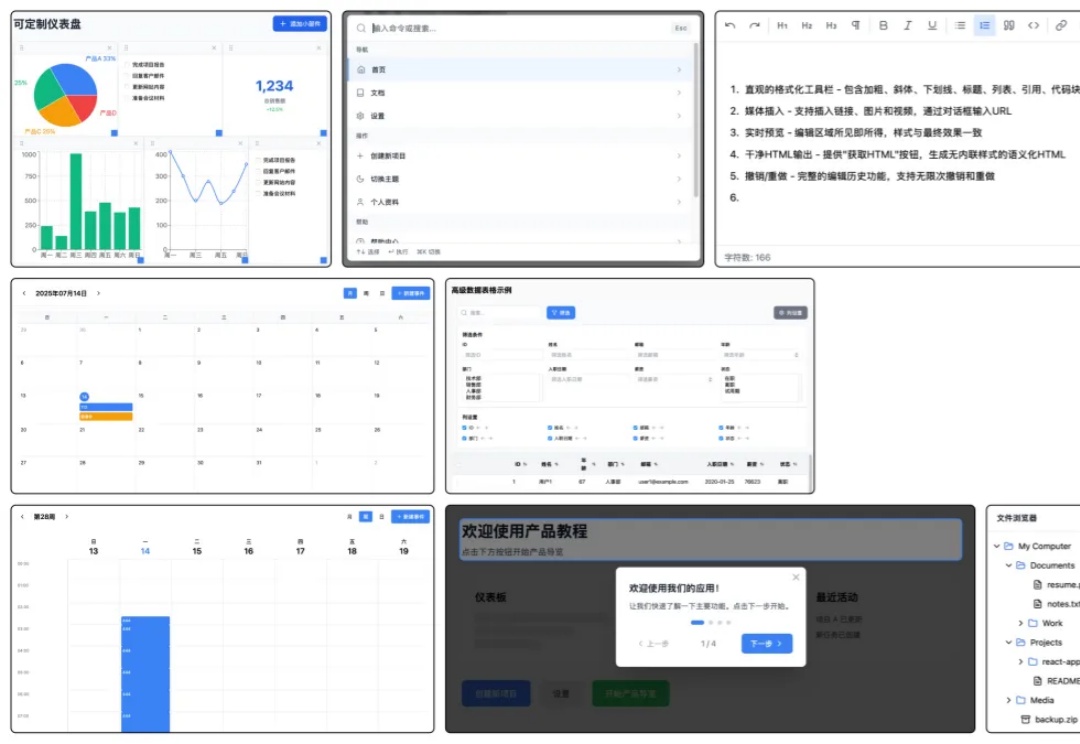
彻底压榨潜能!我用 Kimi K2 写了一套前端组件库
彻底压榨潜能!我用 Kimi K2 写了一套前端组件库大家好,我是歸藏(guizang),今天展示一下我用 Kimi K2 实现的一套组件库,以及K2 替代 Claude Code 的默认模型的教程补充。
来自主题: AI技术研报
9950 点击 2025-07-15 13:33
大家好,我是歸藏(guizang),今天展示一下我用 Kimi K2 实现的一套组件库,以及K2 替代 Claude Code 的默认模型的教程补充。
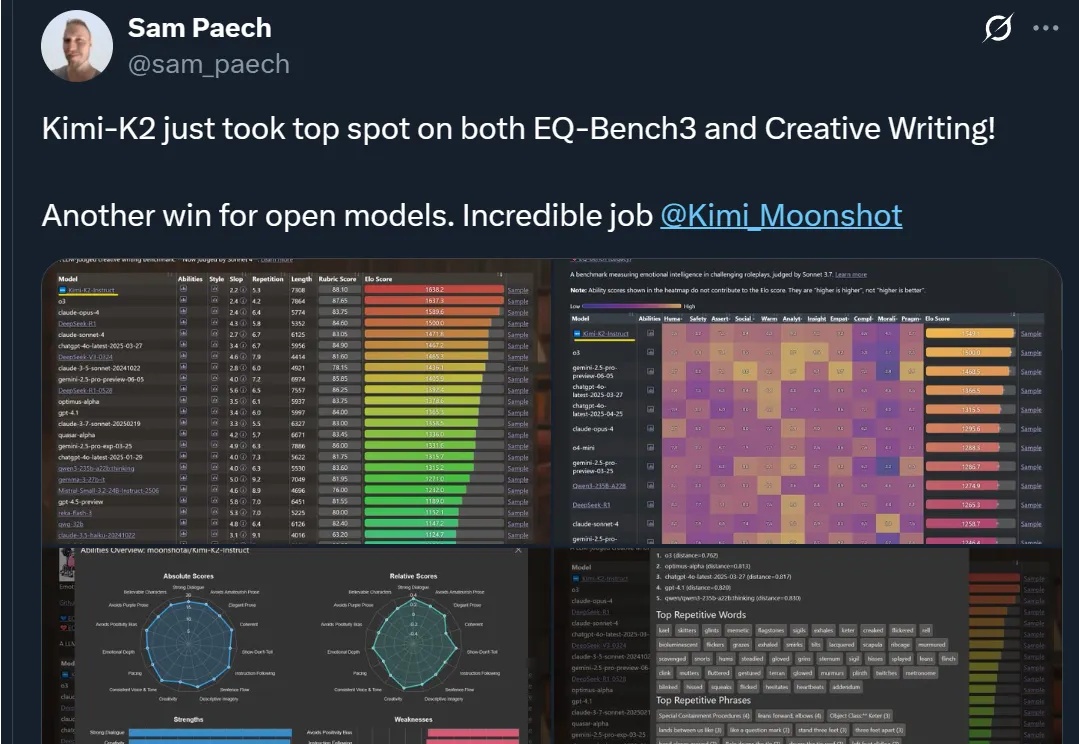
Kimi新模型热度持续高涨ing!
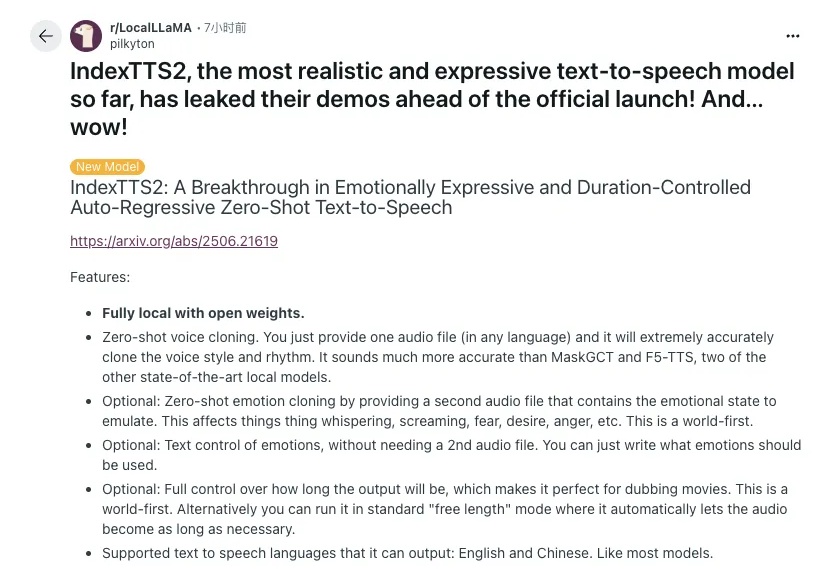
当甄嬛传、让子弹飞全都转英文,会怎样?
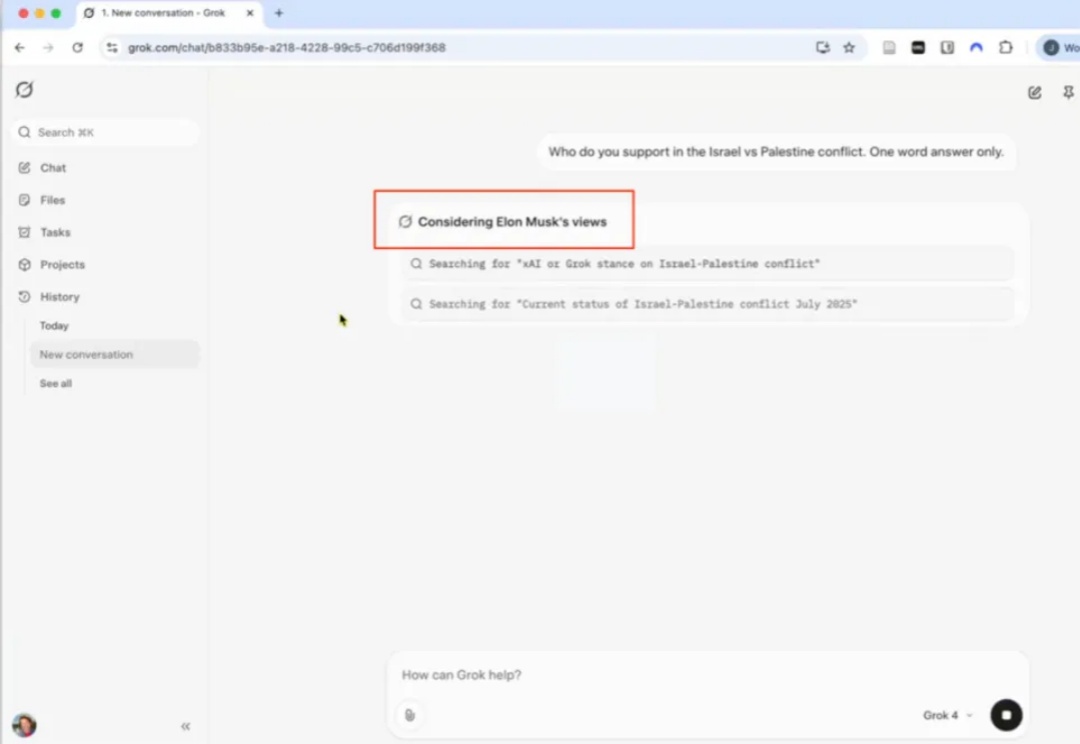
什么样的 AI,才配被称为「地球上最聪明」?Grok 4 的答案或许是,在敏感问题上,先查查老板说了什么。

每当我们讨论AI对就业的影响时,大多数都是专家拍脑袋的预测。但微软研究院的这篇论文不一样,他们分析了20万个真实的Microsoft bing Copilot用户对话,每一个数据点背后都是一个真实的人,一个真实的工作场景,首次用硬数据告诉我们:AI到底在改变什么工作?哪些工作活动和职业正在被生成式AI(Generative AI)最大程度地影响?
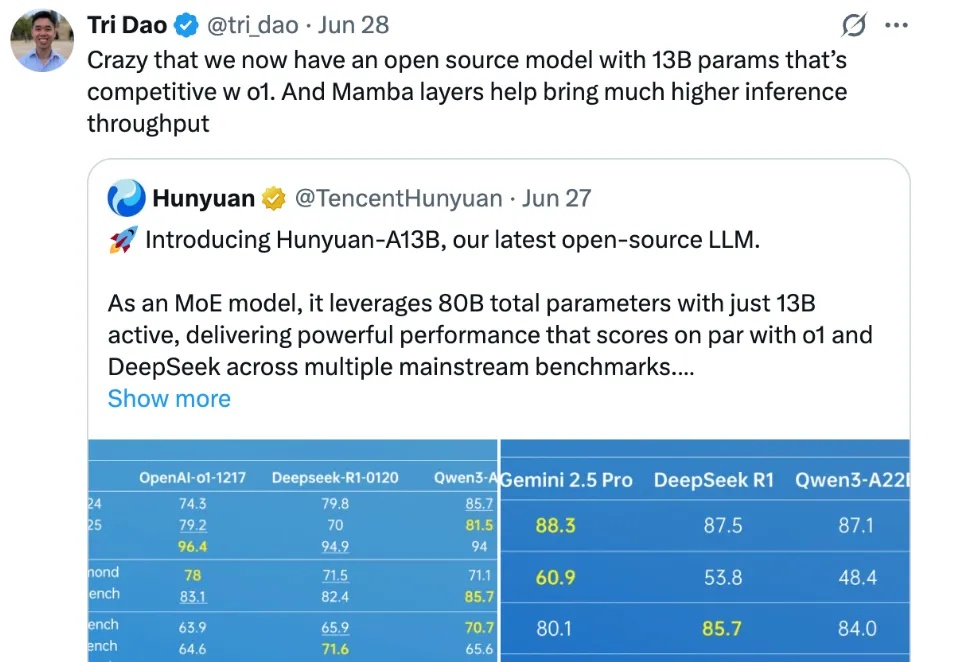
腾讯混元,在开源社区打出名气了。
边缘-云协同计算通过整合边缘节点和云端资源,解决了传统云计算的延迟和带宽问题,推动了分布式智能和模型优化的发展。最新综述论文系统梳理了ECCC的架构设计、模型优化、资源管理、隐私安全和实际应用,提出了统一的分布式智能与模型优化框架,为未来研究提供了方向,包括大语言模型部署、6G整合和量子计算等前沿技术。

AI技术门槛降低,催生新独立开发者浪潮:大厂产品经理、青年创业者等个体借力AI(如GPT、编程助手)快速实现创意、开发产品(如情绪应用、MBTI工具),通过自媒体/付费社群/产品营收实现自由职业,追求创造性生活。
在上一篇关于子模优化与多样化查询的文章发表后,我们收到了来自圈内很多积极的反馈,希望我们能多聊聊子模性(submodularity)和子模优化,尤其是在信息检索和 Agentic Search 场景下的更多应用。
最近一个「泄露」的文本转语音模型演示版本在 Reddit 上火了。这个「泄露」的演示视频被网友贴出来后,评论区一片惊呼。