
【AI犯罪案例分析】AI中转站站长被上海警方抓捕,灰色赛道的合规警示
【AI犯罪案例分析】AI中转站站长被上海警方抓捕,灰色赛道的合规警示核心观点:上海首起AI中转站非法经营案,揭示了跨境AI接口转售的法律风险。AI中转站若未取得ICP证、未履行数据出境安全评估、未备案即调用境外模型,将面临最高5年有期徒刑的刑事风险。本文从技术原理、法律定性、跨境合规三个维度,为AI从业者提供系统性风险防范指南。
来自主题: AI监管政策
9545 点击 2026-05-27 14:12
 搜索
搜索
核心观点:上海首起AI中转站非法经营案,揭示了跨境AI接口转售的法律风险。AI中转站若未取得ICP证、未履行数据出境安全评估、未备案即调用境外模型,将面临最高5年有期徒刑的刑事风险。本文从技术原理、法律定性、跨境合规三个维度,为AI从业者提供系统性风险防范指南。
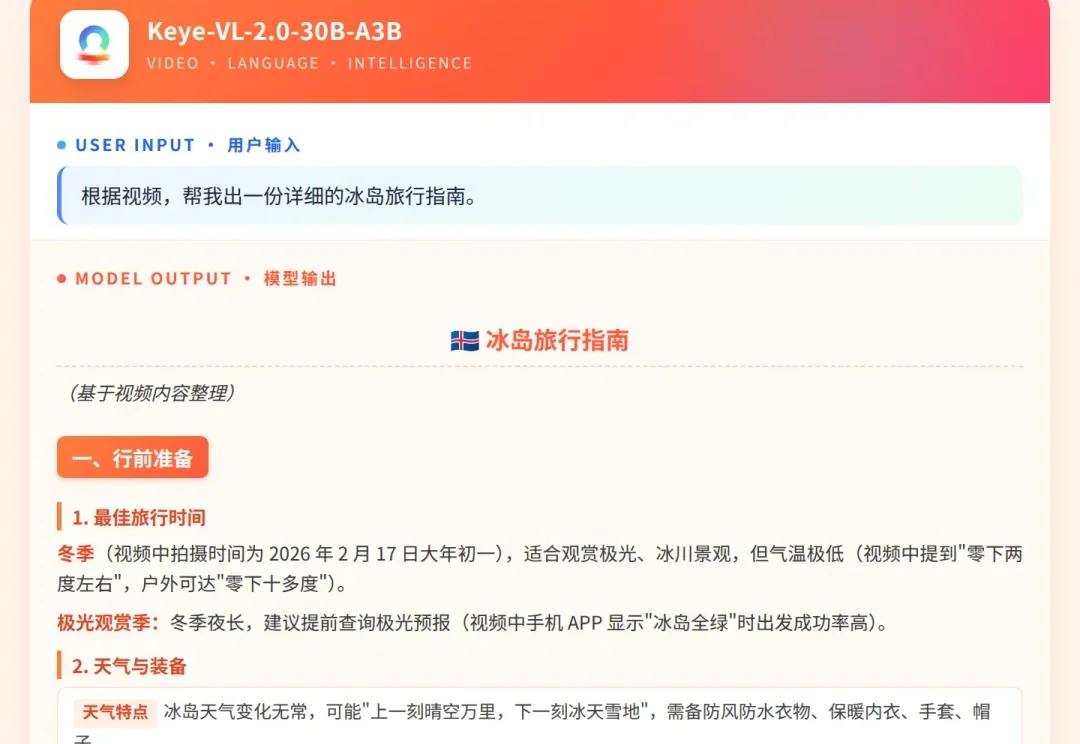
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。

最近到了毕业季,好多朋友来找我聊一件事:有什么办法帮他降 AIGC。
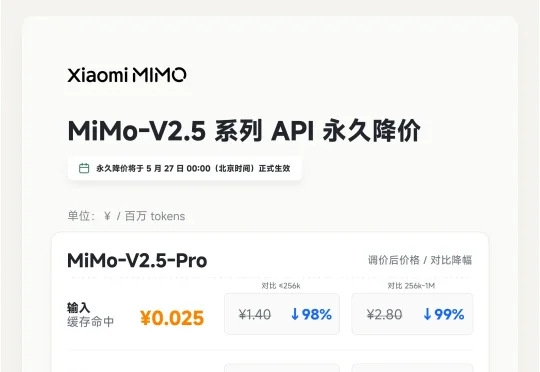
过往几个月,我们通过 MiMo Orbit、百万亿 Token 创造者激励计划等活动,让更多人有机会体验 MiMo ,并解决真实的问题——这是 MiMo 在规模化应用道路上的第一步。 而现在,随着底层

Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。

马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。
你的电脑里,或许很快会住进一只会聊天的「小怪兽」。

英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。