
面壁智能推出AI写的预训练框架ForgeTrain,从此AI开始造自己
面壁智能推出AI写的预训练框架ForgeTrain,从此AI开始造自己造AI这件事,现在的主角变成了AI。
来自主题: AI技术研报
7508 点击 2026-05-26 16:03
 搜索
搜索
造AI这件事,现在的主角变成了AI。
谁懂啊家人们??

机器人看得见,但不一定看得准。
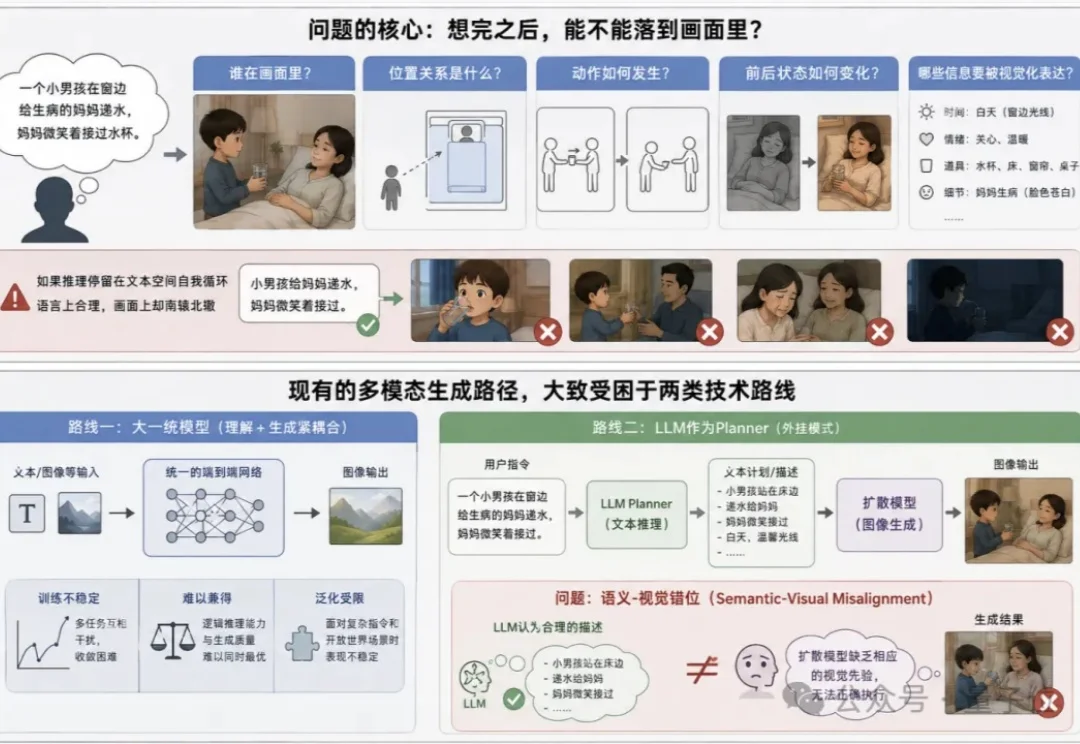
当下视觉生成正陷入一个能力错位困境—— 扩散模型的像素画质已接近完美,但一遇到需要逻辑推理的生成任务就频频翻车。
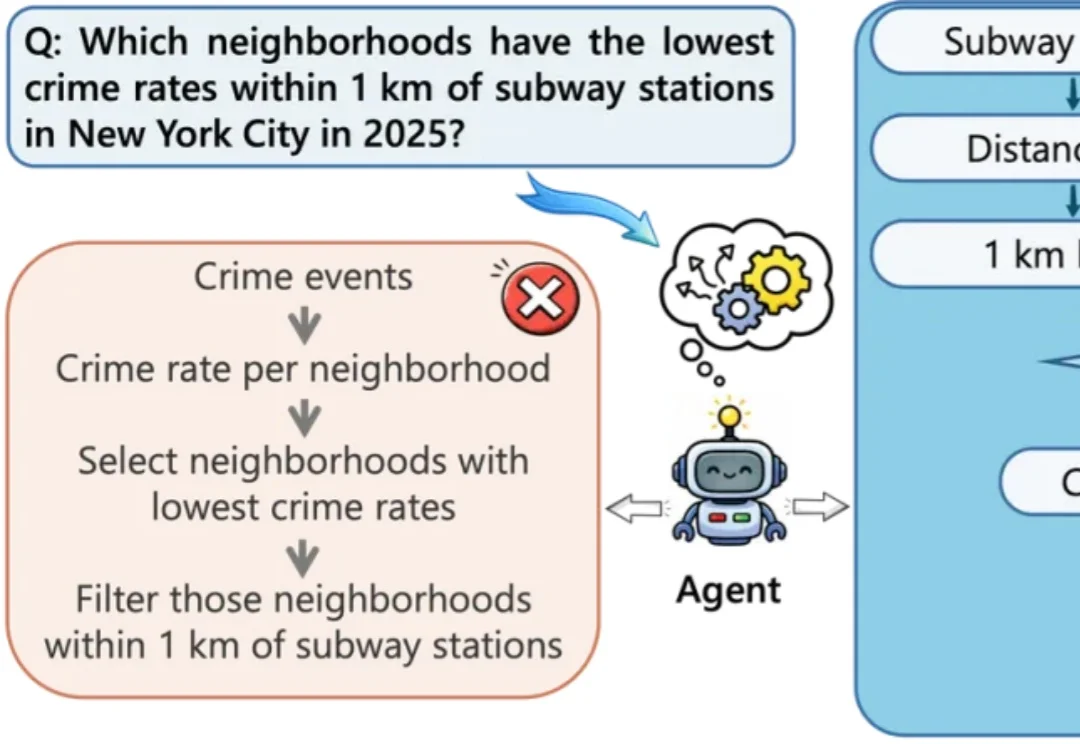
大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。

4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。
DeepSeek这半年生态铺得很快。现在好几个渠道可以免费或极低成本用上DeepSeek模型,从V4 Flash到V4 Pro都有。整理一下最实用的三条路。
马斯克在X上发帖透露,xAI自家的Grok基础模型V9-Medium(1.5T)已经完成训练。预计再过2到3周,差不多就能正式对外发布啦:马斯克特意提到,V9-Medium的补充训练中加入了大量Cursor数据,后续还会继续添加。

当年互联网创业公司最熟悉的“羊毛”,是云厂商送的服务器额度;现在,AI 创业圈的“新硬通货”,已经变成了大模型 Token。

DeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。