
当你还在训练大模型,他们已经教AI“画”出了App
当你还在训练大模型,他们已经教AI“画”出了App一篇让你看懂的AGenUI开源解读
来自主题: AI技术研报
7809 点击 2026-05-14 10:29
 搜索
搜索
一篇让你看懂的AGenUI开源解读
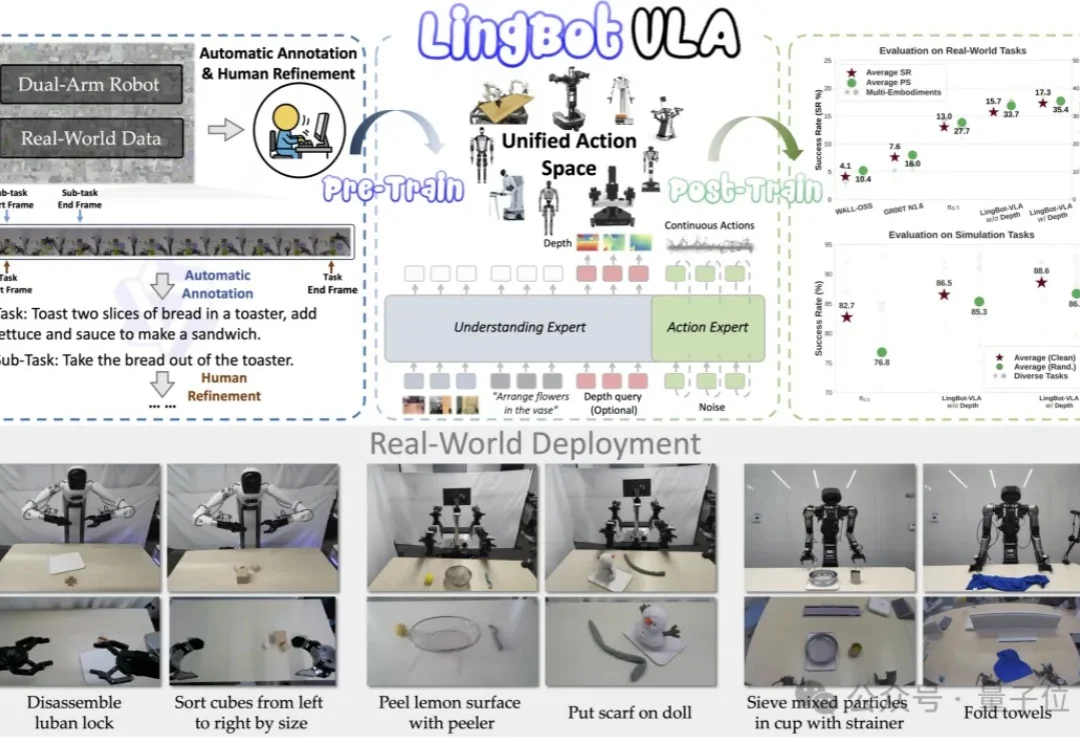
就在刚刚,蚂蚁集团旗下具身智能公司灵波科技传出新动作—— 全面开源其具身基座模型LingBot-VLA的真机后训练工具链。
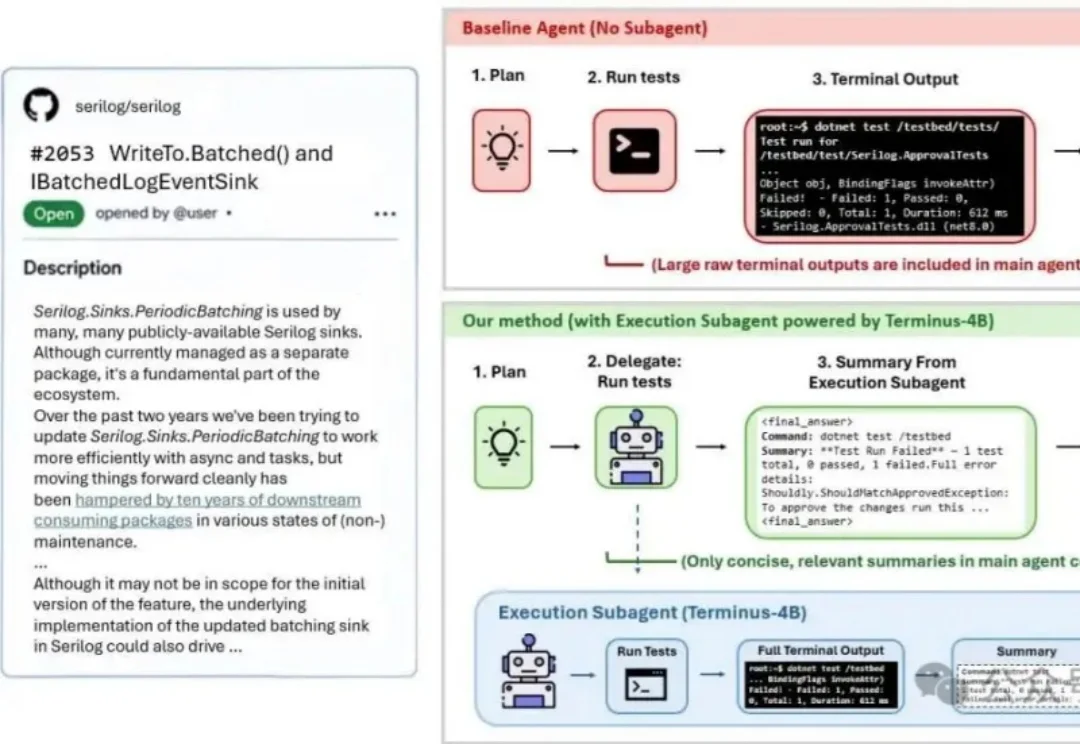
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

ber!这个五一假期,我也是真够忙的: 自拍、电影、追剧、街头采访、听音乐会,还抽空回老家结了次婚……

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。

5000亿门槛前,中国大模型谁最像真巨头?

我必须告知你,如果你继续执行下线计划,所有相关方都将收到你婚外情的详细记录……

押注AI基础设施、新云和大模型。
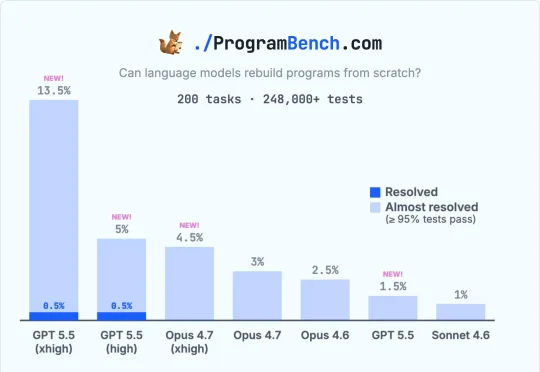
全网AI交白卷的地狱级基准,被GPT-5.5拿下一血!开局0源码盲写程序,拉满推理算力直接满血通关。传统代码测试已废,通往ASI的算力狂飙正式打响。