
独家|浙大00后世界模型创业,魔芯科技完成新一轮亿元融资,已在多个产业领域实现交付
独家|浙大00后世界模型创业,魔芯科技完成新一轮亿元融资,已在多个产业领域实现交付2021 年,陈天润还在浙江大学读本科。那一年 ChatGPT 不存在,大语言模型远没有破圈。“世界模型”这个概念刚刚冒头,但陈天润做了一个当时看起来相当激进的决定:成立一家公司,做 3D 和 AI。
来自主题: AI资讯
10401 点击 2026-05-13 19:57
 搜索
搜索
2021 年,陈天润还在浙江大学读本科。那一年 ChatGPT 不存在,大语言模型远没有破圈。“世界模型”这个概念刚刚冒头,但陈天润做了一个当时看起来相当激进的决定:成立一家公司,做 3D 和 AI。

独家获悉,前阿里千问大模型技术负责人林俊旸近期已经开启创业,考虑方向包括世界模型和具身大脑。目前,林俊旸已经招募数名字节、腾讯和海外背景的成员,并以约20亿美金的估值开启融资,接触基金包括红杉中国、高榕创投等。

端侧多模态,卷出新天花板。仅1.3B,性能反超,效率翻倍,一张4090就能「爆改」。刚刚,清华系团队面壁智能开源了新一代「小钢炮」MiniCPM-V 4.6,再次证明了在端侧AI领域,中国团队已然站在世界前沿。

AI版权大战,再度升级了。
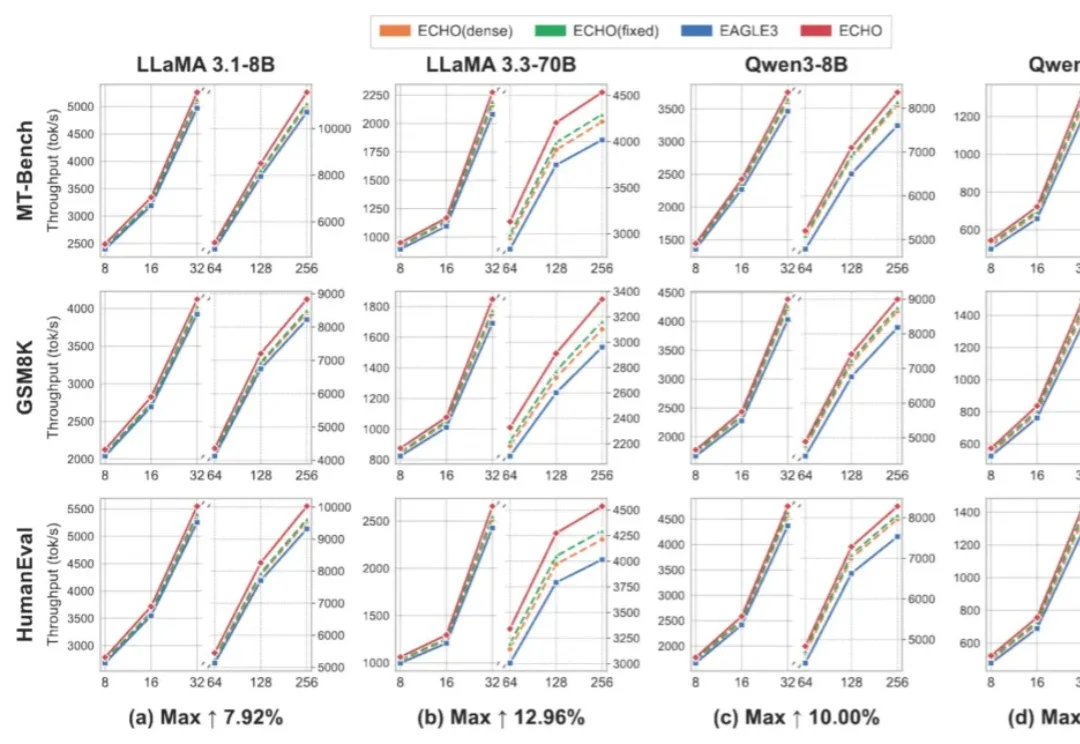
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

家用电器是家庭服务机器人最难啃的一类任务对象。与桌面物体操作相比,家电操作不仅涉及按钮、旋钮、门体等多种异构部件,还受到模式切换、状态约束和程序逻辑的共同支配。真正完成一次家电任务,机器人往往既要「看得见」,也要「读得懂」,还要「按说明书做对」。
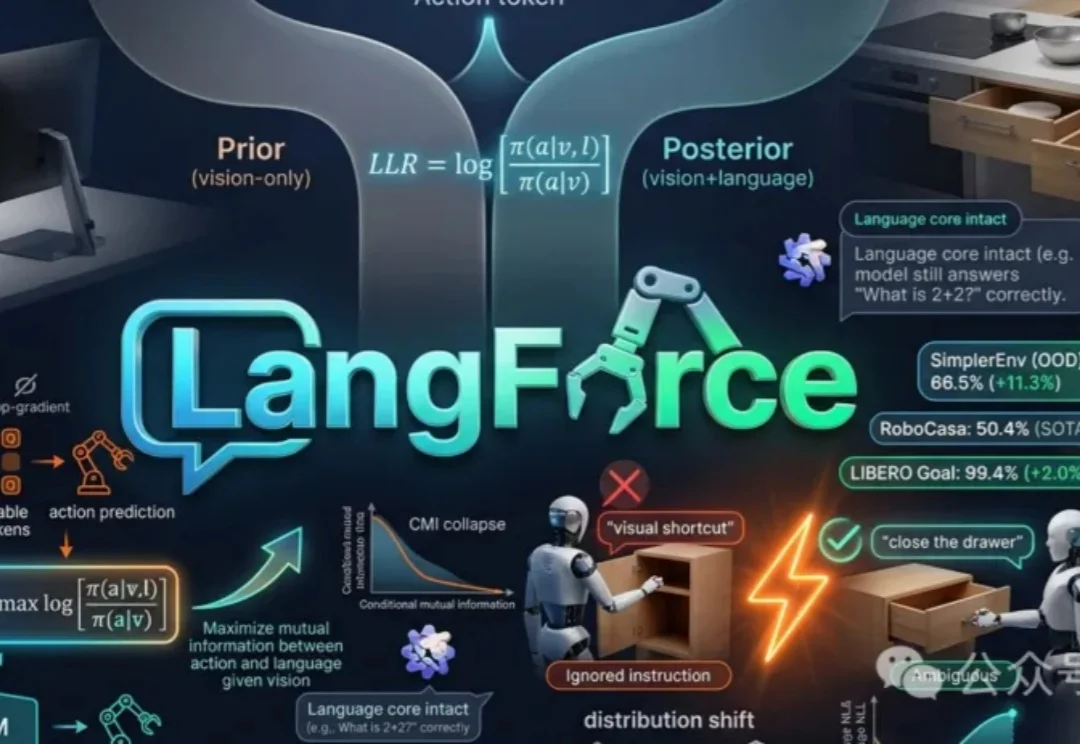
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
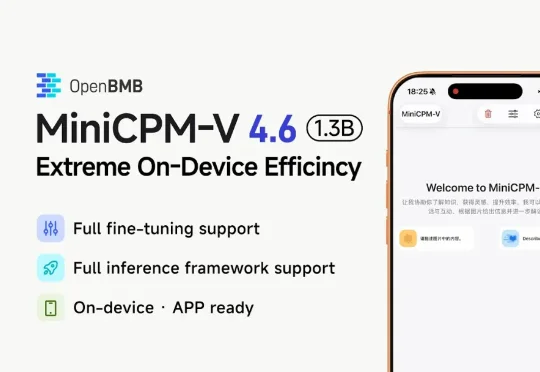
面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。
一家估值超5000亿美元的币圈富豪公司,秀出了性能碾压谷歌的AI医疗大模型。

何恺明,也下场做语言模型了。