
Thinking Machines 刚发的「边听边说」,让我想到了几个月前的面壁智能
Thinking Machines 刚发的「边听边说」,让我想到了几个月前的面壁智能OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究
来自主题: AI技术研报
8716 点击 2026-05-13 10:47
 搜索
搜索
OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究

近日,字节跳动智能创作部门(Intelligent Creation Lab)提出新作 DreamLite,一个主干网络仅有 0.39B 参数的轻量级统一扩散模型,在单一网络内同时支持文生图(Text-to-Image) 和图像编辑(Text-guided Image Editing)两个任务,是目前已知首个实现这一能力的端侧模型。

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。

谷歌周一发布报告,首次确认犯罪黑客使用AI大模型发现了一个此前未知的零日漏洞,并差点发动大规模攻击。这件事之所以炸裂,是因为安全界担心了好几年的「AI自动挖洞」,终于从理论变成了现实。而在Anthropic的Mythos模型已经找到数千个零日漏洞的背景下,这可能只是冰山一角。
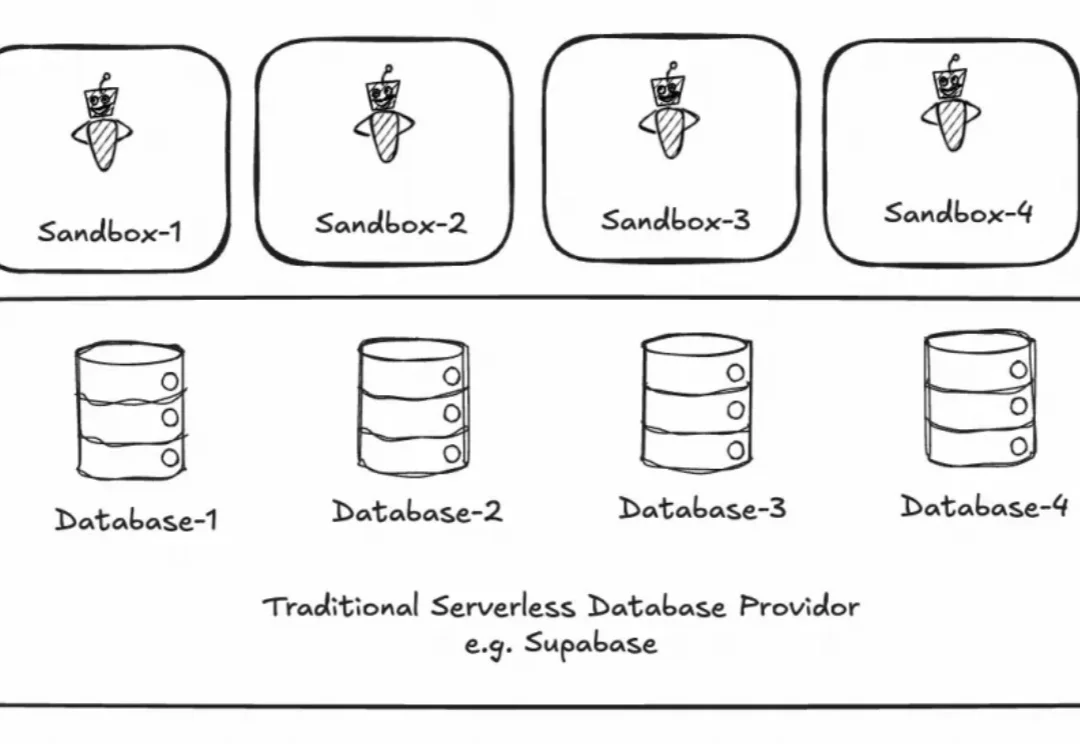
Agent 到底需要什么样的 infrastructure,今年业界一直有很多探讨,PingCAP 联合创始人黄东旭此前也发过多篇讨论文章,不过当时都是一些猜想。随着 agent 今年的爆发,大规模落地的案例出现了。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

AI再也不是“回合制”了。Thinking Machines Lab(以下简称TML)发布首个模型,让实时交互能力成为模型原生能力。联合创始人翁荔出镜演示。
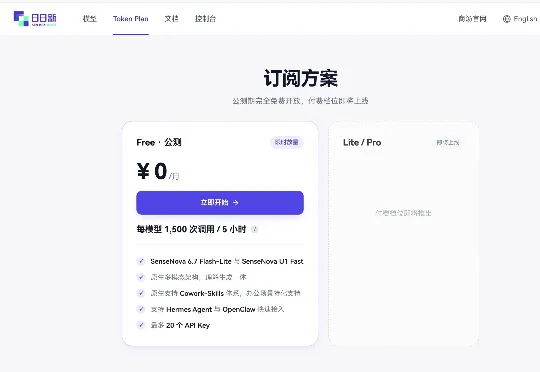
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。

今天,谷歌原生视频模型Gemini Omni意外曝光!各种惊艳demo刷爆,教授黑板推导数学公式、一句话编辑视频,丝滑程度让全网破防。

科研,能被 AI 全程加速吗?