这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?
这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
来自主题: AI技术研报
9138 点击 2026-05-02 15:00
 搜索
搜索
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。

GPT-5.5发布没几天,后台日志里就冒出了GPT-5.6;Anthropic的一个从未见过的代号——Jupiter也炸出了!两天之内,两家巨头的下一代模型同时浮出水面。新一轮模型军备竞赛,比我们想的都要快!

昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。

当AI生图真的开始被普通人使用,它会先被用在哪里?所以这次我没有继续测模型或者写Prompt分享。而是去找了10个身边的普通人,问他们怎么开始用AI生图,又为什么会在这些具体的小事上用到它。
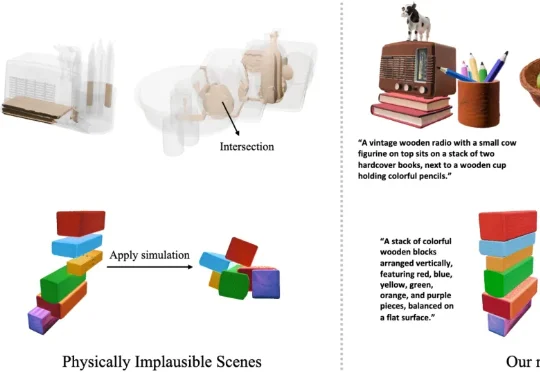
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。
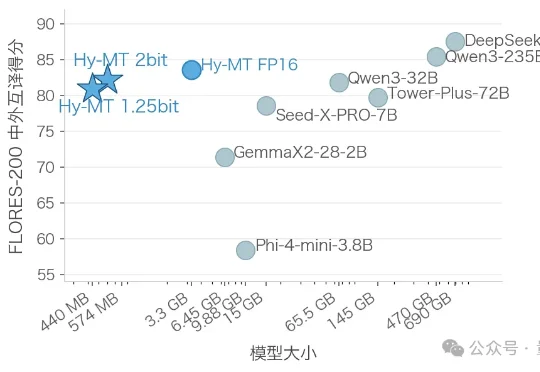
腾讯混元团队刚刚开源了一份硬核解决方案:推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。
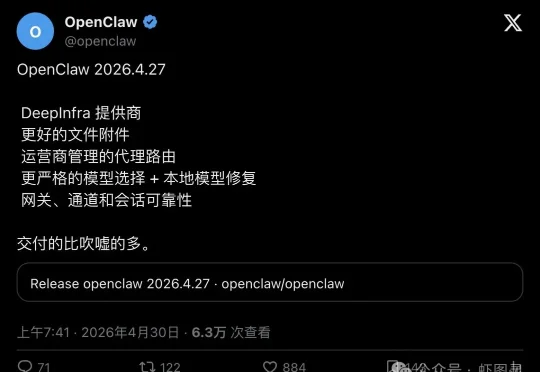
OpenClaw 刚刚发布 2026.4.27 版本,一次性把 DeepInfra 多模态 provider、非图片附件链路、企业级代理路由、模型选择确定性、网关/通道/会话稳定性五件事全部补齐。近 900 人点赞,6.3 万人围观,社区却吵成两派——一边夸"终于补了生产级地基",一边追问"上几版的 gateway 坑到底填了没"。
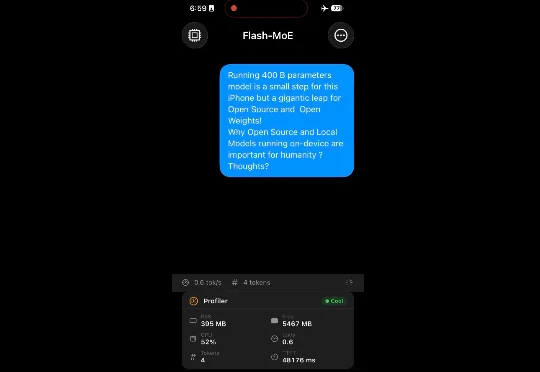
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。
一边是 DeepSeek。2026 年 4 月 24 日,正式发布新一代模型DeepSeek-V4 系列预览版,并同步开源。另一边,美团闷声干了件大事——用全国产算力集群,训练出了万亿参数大模型 LongCat-2.0 系列预览版( LongCat-2.0-Preview )。