今天,Claude改变了PS和Blender的玩法!
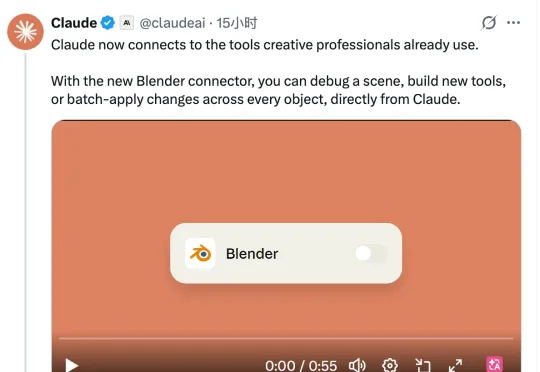
今天,Claude改变了PS和Blender的玩法!今天,Anthropic一口气甩出9个设计师专属连接器,以后可以直接在Blender、Photoshop、Premiere这些专业设计软件中使用Claude了。与先前推出的Claude Design不同,这次Anthropic不是要在自家软件里大包大揽,而是把Claude塞进了各大设计软件,用户可以用自然语言在Claude中使用这些专业设计软件,实现对3D模型、平面设计以及音乐等文件的创造和修改。
来自主题: AI资讯
8799 点击 2026-04-29 22:11