超越DeepSeek-V4!罗福莉交出小米最强开源模型MiMo-V2.5-Pro,首日适配5家国产芯片
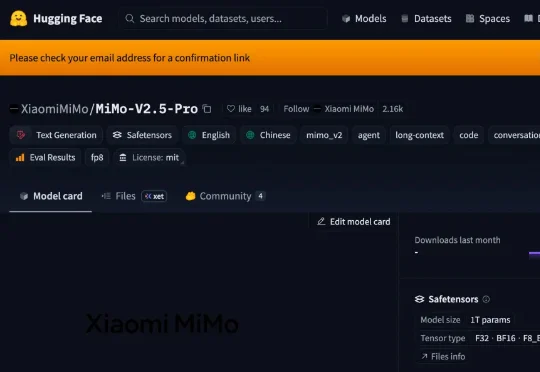
超越DeepSeek-V4!罗福莉交出小米最强开源模型MiMo-V2.5-Pro,首日适配5家国产芯片刚刚,小米开源罗福莉带队研发的MiMo-V2.5系列模型,采用MIT协议,允许商用推理部署与二次训练,无需额外授权。此前,该系列模型于4月23日开启公测,包括MiMo-V2.5-Pro、MiMo-V2.5两款模型。模型具备更强Agent能力,支持100万上下文,且Token效率大幅提升。
来自主题: AI资讯
9054 点击 2026-04-28 10:13