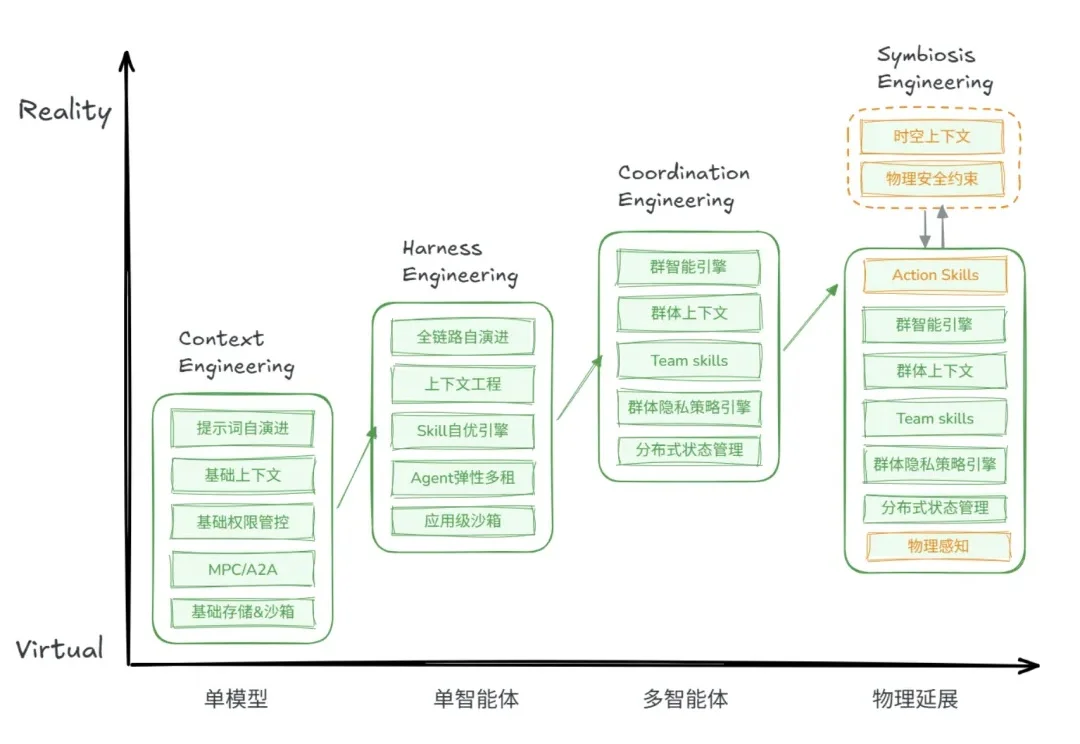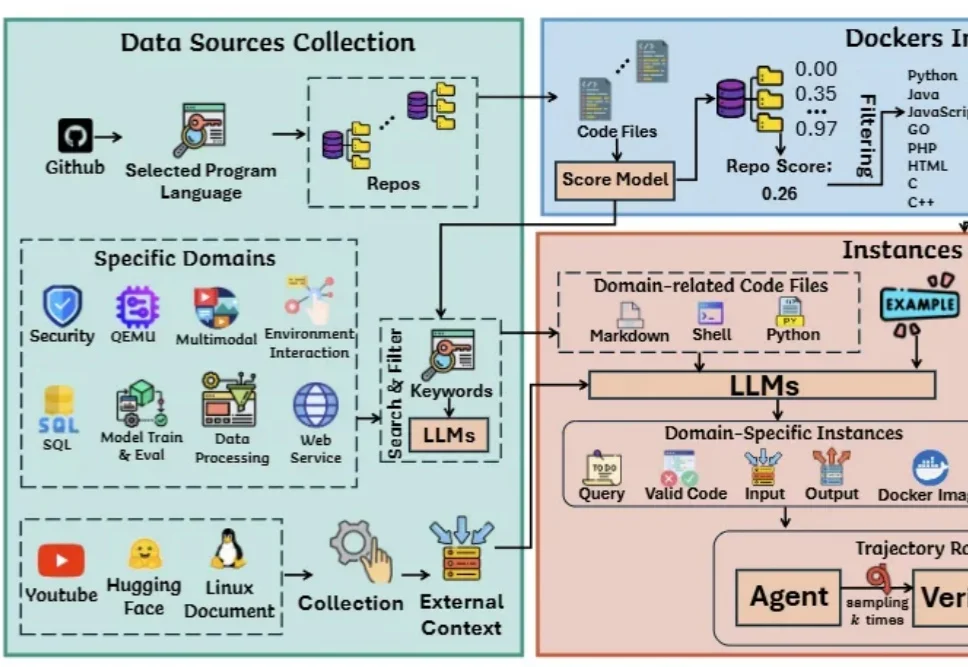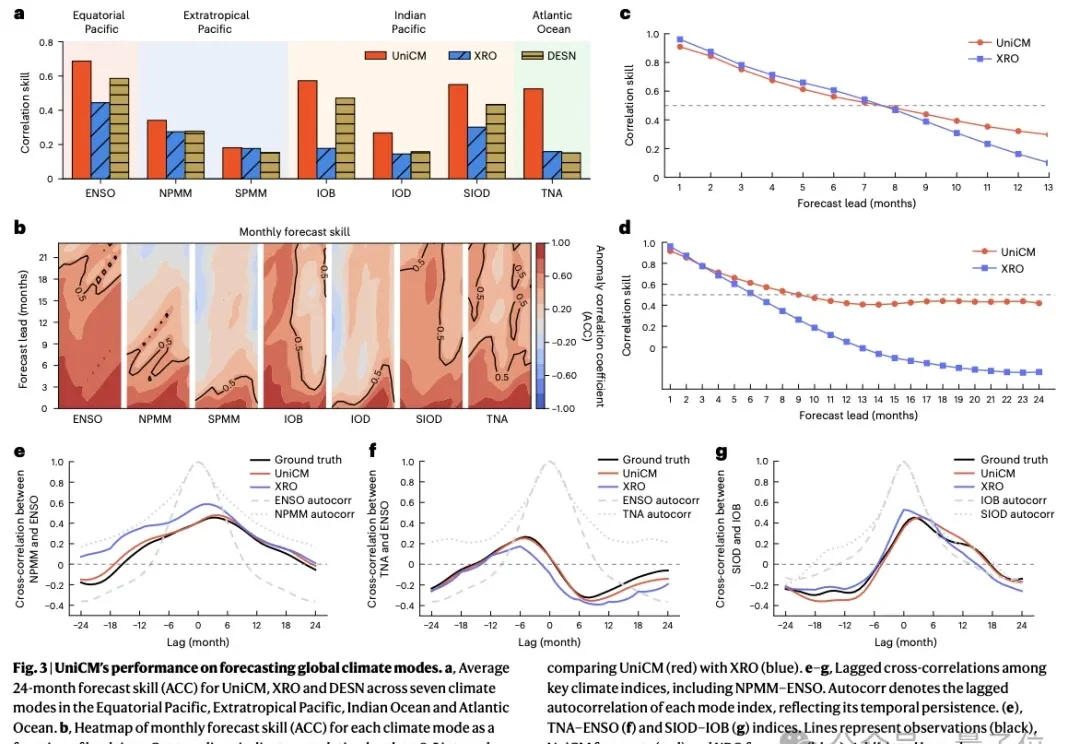
低成本复刻Fable 5的路子找到了:OrcaRouter多模型组队,性能反超
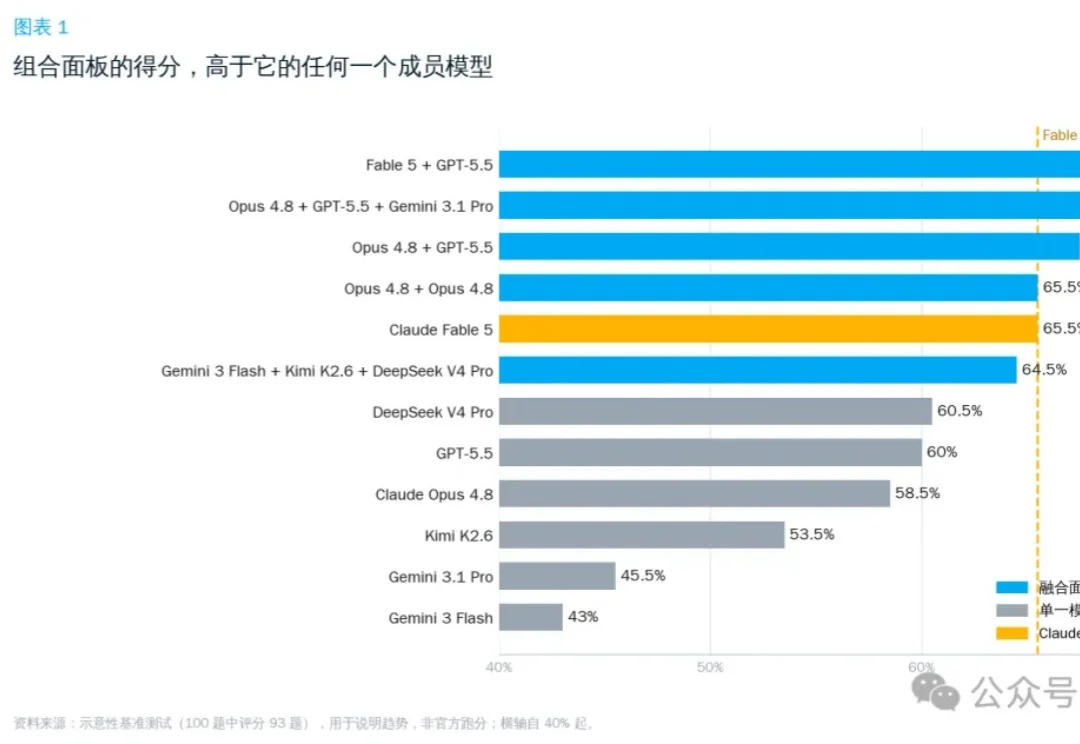
低成本复刻Fable 5的路子找到了:OrcaRouter多模型组队,性能反超AI网关OrcaRouter最近上线了一套可编程路由策略Routing DSL,多个模型同时答题,自动仲裁出最优解。几个你现在就能调用的“常规模型”,给它来个组合编排,跑出来的综合胜率,直接掀翻了Fable 5的单体基准线。Opus 4.8打不过Fable 5,GPT-5.5也单挑不过,但这两个拼一组,结果就反超了。
来自主题: AI技术研报
9891 点击 2026-06-15 15:12