# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了!
如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。

文章作者Moritz Reuss是2025年Apple AI/ML学者奖得主,曾在RSS、ICLR、NeurIPS等顶级会议多次发表研究成果。这篇综述既是一线研究者的实战总结,也是洞察趋势的前沿观察。
文章一出,评论区好评不断,甚至顶级猎头Mark Wallace直接抛出了橄榄枝。
这个VLA,究竟有多火?
据统计,VLA模型相关投稿量,从去年的个位数飙升至164篇,足足增长了18倍。
这股热潮背后,让机器人“听懂人话、看懂世界、动手干活”,正成为AI领域极具吸引力的前沿阵地。
然而,在这片繁荣之下,一个问题也随之浮现:当我们谈论VLA的进步时,我们到底在谈论什么?
在深入探讨技术趋势前,我们必须先明确一个基本概念:什么样的模型,才有资格被称为VLA?
学术界对此尚无统一定义,但研究员Moritz Reuss在他的综述中提出了一个标准:
一个模型必须使用经过大规模、互联网级别的视觉-语言数据预训练过的骨干(pre-trained backbone),才能被称为VLA。
这一定义强调模型能力的来源:VLA必须具备通过图文预训练习得的语言理解、视觉泛化和任务迁移能力。
代表模型如Google的PaLI-X,或开源项目Llava、Florence-2等。
而如果一个模型只是简单地将独立的视觉编码器和文本编码器拼在一起,那它更应该被称为“多模态策略”(Multimodal Policies)。
与之相关,还有一个概念值得一提:大型行为模型(Large Behavior Models, LBMs)。这是丰田研究院提出的术语,指在“大规模、多任务的机器人演示数据”上训练出的策略。
可以这样理解:
一个在大量机器人数据上微调的VLA,同时也是一个LBM。
但一个LBM,不一定是一个VLA。搞清楚这个边界,才有助于我们理解不同技术路线的侧重。
如果说今年VLA架构有什么新风向,当属离散扩散模型(Discrete Diffusion)。
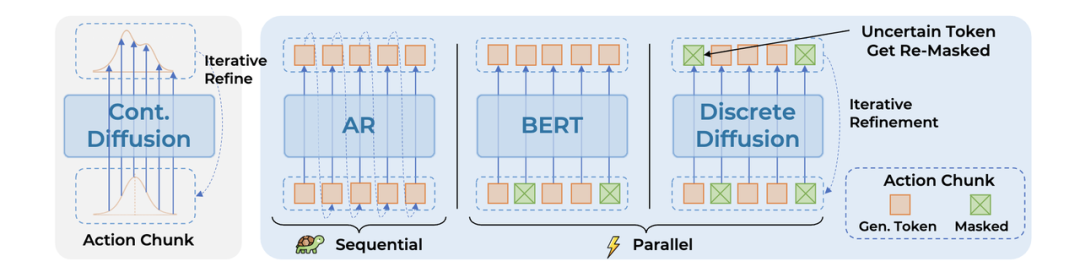
传统的自回归模型一个字一个字写,必须生成完上一个动作单元,才能生成下一个。
而离散扩散模型则可以并行化地一次性生成整个动作序列。这带来了几个好处:
关于这个趋势,本次ICLR上涌现了《DISCRETE DIFFUSION VLA》《dVLA》等多篇论文,在LIBERO评测中取得了近乎饱和的表现。
让机器人更聪明,光靠模仿是不够的,它还得学会“思考”。具身思维链(Embodied Chain-of-Thought, ECoT)正是这一思路的集中体现。
其核心思想是:在生成动作前,先生成一系列中间推理步骤,使机器人具备更强的计划与解释能力。
这些步骤可以是:
这种先想后做的模式不仅更具可解释性,也显著提升复杂场景中的泛化能力。
但ECoT对高质量标注数据依赖较大,而这类数据仍较稀缺。
本次ICLR中,如《ACTIONS AS LANGUAGE》《EMBODIED-R1》等论文,通过推理-动作解耦和多阶段训练流程,在SIMPLER等评测中表现突出。
VLA的一个核心难点是:如何将连续、高频的机器人动作转换为VLM能理解的离散“词汇”(Token)?
这正是动作分词器(Action Tokenizer)的作用所在。它是连接VLM“大脑”与机器人“身体”的桥梁。
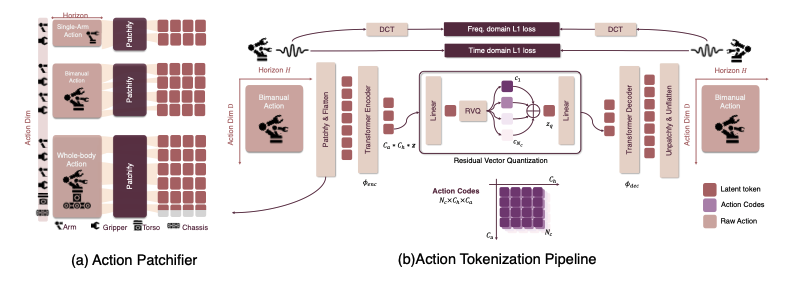
今年的新进展包括:
在LIBERO和SIMPLER中,这些方法提升了精度与稳定性,为语言模型驱动的机器人控制奠定基础。
模仿学习虽可快速习得基础操作,但极端场景下表现仍有限。因此,强化学习(RL)重新登场,作为VLA策略的微调利器。
今年的代表技术包括:
代表作如《SELF-IMPROVING… VIA RESIDUAL RL》《PROGRESSIVE STAGE-AWARE…》在LIBERO和SIMPLER上分别取得了99%和98%的成功率。
VLA模型庞大、成本高昂,令许多中小实验室望而却步。因此效率优化成为研究重点。
典型代表有这两大方向:
这些方法大幅降低了硬件门槛,让更多研究者能够参与VLA研究。
视频生成模型天然理解时序动态和物理规律,这对于机器人控制是极强的先验知识。
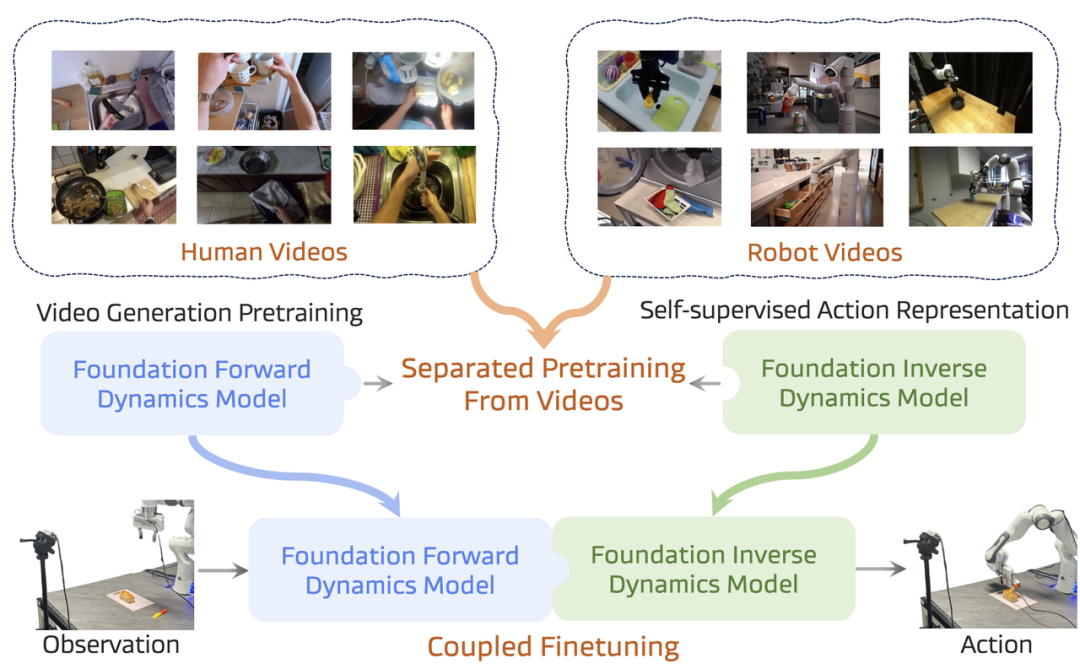
这个方向主要有两种思路:
例如《COSMOS POLICY》就成功将一个视频基础模型微调用于机器人控制,并在真实世界中与Pi-0.5等前沿模型进行了对比。
这些工作表明,赋予VLA“想象”未来的能力,能有效提升其对物理世界的理解。
正如后文会提到的,现有评测集已近饱和。为此,社区正在积极开发新的评测方式。

这些新基准致力于打破对现有测试集的过拟合,推动VLA研究走向更有意义的泛化能力。
如何让一个模型同时驱动不同结构(Action Space)的机器人?这是通往通用机器人的核心挑战。
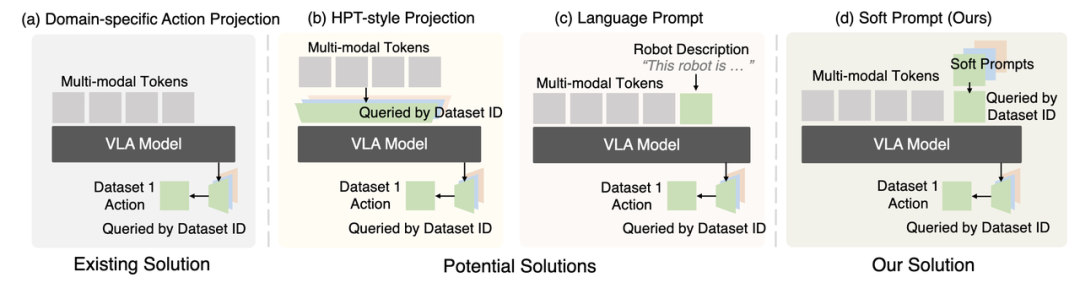
这些架构上的创新,是构建能够适应不同硬件的通用机器人策略的关键一步。
研究员Reuss在文中指出:主流仿真评测(如LIBERO、CALVIN)存在“性能天花板”问题。
很多模型得分虽高,却难以转化为现实能力,原因如下:
开源模型在仿真环境中得分甚至高于Google的Pi-0.5,但在真实世界中,仍难匹敌这些前沿产品。
文章的最后,Reuss还指出两个VLA研究中尚未受到足够重视的问题:
这篇综述的作者Moritz Reuss,是德国卡尔斯鲁厄理工学院(KIT)的四年级博士生,长期致力于从人类演示、视觉与语言中构建通用机器人AI系统。

他也是将扩散模型引入机器人策略研究的先行者,而这恰好是本次综述中提到的热门趋势之一。
作为2025年Apple AI/ML学者奖获得者,他的研究成果已多次发表于RSS、ICLR、NeurIPS等顶会。可以说,这份综述来自科研一线的“圈内人”。
最后,VLA的这么多技术方向,你最看好哪一个?是更快的离散扩散,还是更聪明的思维链?或者你认为数据才是唯一的密码?
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
