
机器人这回真要进家当保姆了!世界统一模型登场,有世界观、能自我进化
机器人这回真要进家当保姆了!世界统一模型登场,有世界观、能自我进化1个月后,自变量新一代机器人就要入驻真实家庭了。
来自主题: AI资讯
9844 点击 2026-04-24 09:15
 搜索
搜索
1个月后,自变量新一代机器人就要入驻真实家庭了。
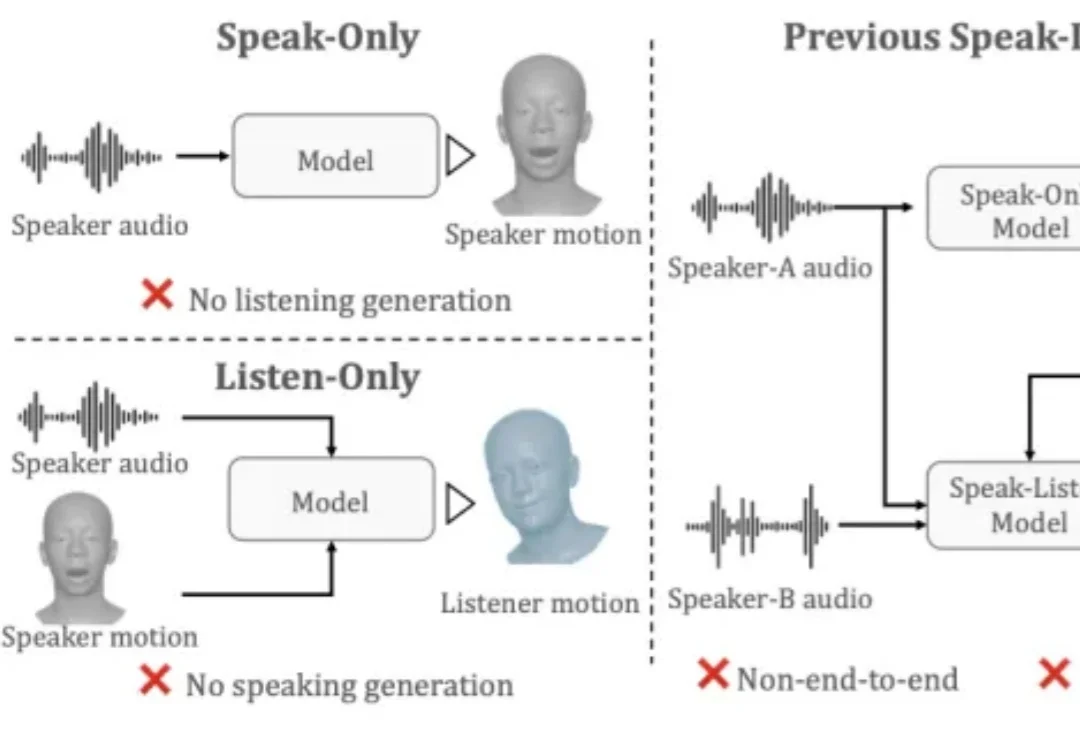
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。
还记得两年前,AI 生视频可谓是「鬼畜专区」—— 人物多一根手指算基操,走路自带鬼步舞才是常态。结果转眼间,从 OpenAI 的 Sora 到字节跳动的 Seedance,这些模型已经开始一本正经地「模拟世界」了:水会流、球会弹、光影能追踪,俨然一副要当「物理引擎」的架势。
刚刚,混元的 Hy3 Preview 也正式亮相,这是腾讯首席 AI 科学家姚顺雨主导的一个模型。姚顺雨表示,Hy3 preview是混元大模型重建的第一步。他希望通过这次开源和发布,不断提升 Hy3 正式版的实用性,以及模型在真实场景中的综合表现,并开始探索特色模型能力。

一位接近DeepSeek的一线机构投资人士告诉我们,这些数字都不准确,DeepSeek融前估值是3000亿人民币,约合440亿美元。这一估值超过当前已经上市的大模型公司Minimax的2400亿(4月23日),接近智谱的3800亿元。
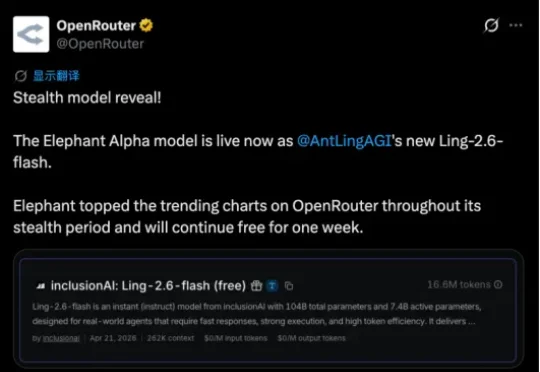
4月22日,蚂蚁百灵正式推出Ling-2.6-flash Instruct模型。该模型总参数量为104B,激活参数仅7.4B,核心主打高“Token 效率(Token Efficiency)”。API定价方面,Ling-2.6-flash输入每百万tokens定价0.1美元,输出 0.3 美元。目前,Ling-2.6-flash API已在OpenRouter及百灵tbox平台上线。
就在刚刚,Codex平台爆发重大泄漏事故,内部测试环境疑似误推生产环境。GPT-5.5、「风速狗」Arcanine、「海森堡」以及神秘的Glacier集体亮相。奥特曼口中那个「比Transformer更伟大的架构」,难道已经藏在这些模型背后?
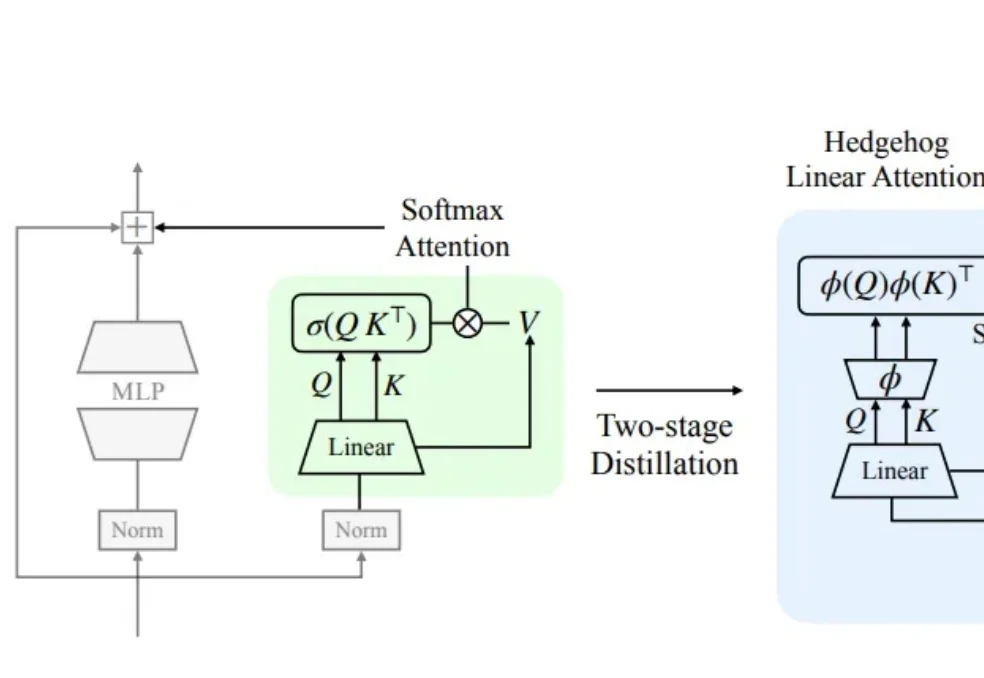
最近,苹果又整了个活儿,很工程、也挺关键: 把又贵又强的 Transformer,改造成又便宜又差不多强的 Mamba。而且,性能基本没怎么掉。

LPM 1.0 只是冰山一角,蔡浩宇真正在造的,是下一个时代的游戏引擎。