腾讯混元最新开源:440M翻译模型手机离线就能用,翻译质量超谷歌
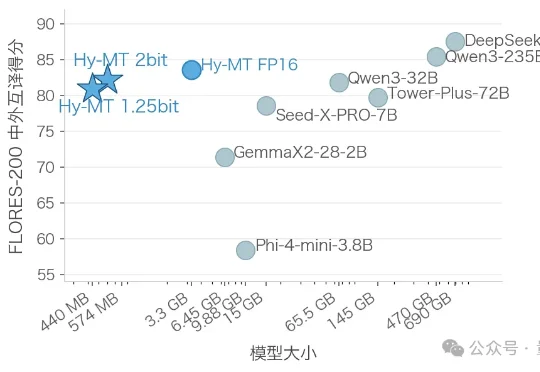
腾讯混元最新开源:440M翻译模型手机离线就能用,翻译质量超谷歌腾讯混元团队刚刚开源了一份硬核解决方案:推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。
来自主题: AI资讯
7048 点击 2026-05-02 13:34
 搜索
搜索
腾讯混元团队刚刚开源了一份硬核解决方案:推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。
在移动计算时代,将高效的自然语言处理模型部署到资源受限的边缘设备上面临巨大挑战。这些场景通常要求严格的隐私合规、实时响应能力和多任务处理功能。

在金融科技智能化转型进程中,大语言模型以及多模态大模型(LVLM)正成为核心技术驱动力。尽管 LVLM 展现出卓越的跨模态认知能力
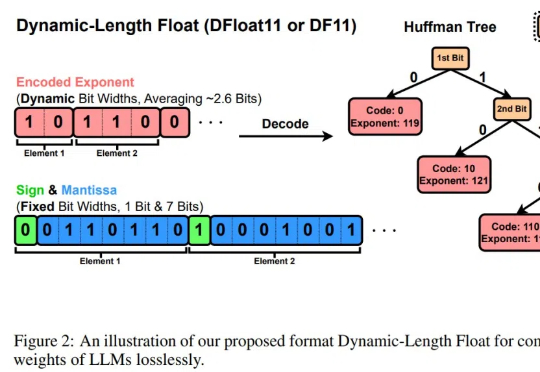
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。

LLM的规模爆炸式增长,传统量化技术虽能压缩模型,却以牺牲精度为代价。莱斯大学团队的最新研究DFloat11打破这一僵局:它将模型压缩30%且输出与原始模型逐位一致!更惊艳的是,通过针对GPU的定制化解压缩内核,DFloat11使推理吞吐量提升最高38.8倍。
欧洲初创公司 Pruna AI 一直在研究 AI 模型的压缩算法,该公司的优化框架将于周四开源。Pruna AI 在几个月前完成了 650 万美元的种子轮融资。参与此次初创公司投资的包括 EQT Ventures、Daphni、Motier Ventures 以及 Kima Ventures。

改进KV缓存压缩,大模型推理显存瓶颈迎来新突破—— 中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。

大语言模型(LLM)正在推动通信行业向智能化转型,在自动生成网络配置、优化网络管理和预测网络流量等方面展现出巨大潜力。未来,LLM在电信领域的应用将需要克服数据集构建、模型部署和提示工程等挑战,并探索多模态集成、增强机器学习算法和经济高效的模型压缩技术。

单卡搞定Llama 3.1(405B),最新大模型压缩工具来了!

基于 Transformer架构的大型语言模型在各种基准测试中展现出优异性能,但数百亿、千亿乃至万亿量级的参数规模会带来高昂的服务成本。例如GPT-3有1750亿参数,采用FP16存储,模型大小约为350GB,而即使是英伟达最新的B200 GPU 内存也只有192GB ,更不用说其他GPU和边缘设备。