突破一亿Token极限:EverMind提出MSA架构,实现大模型高效端到端长时记忆
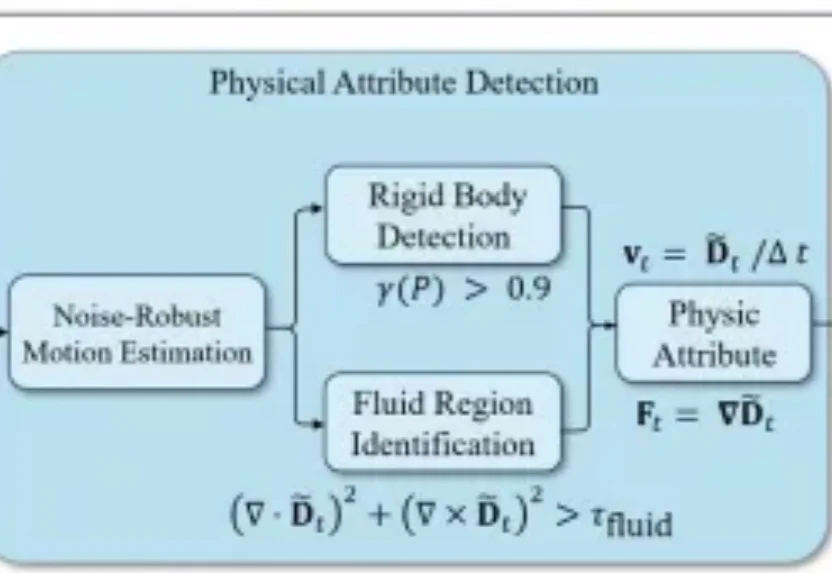
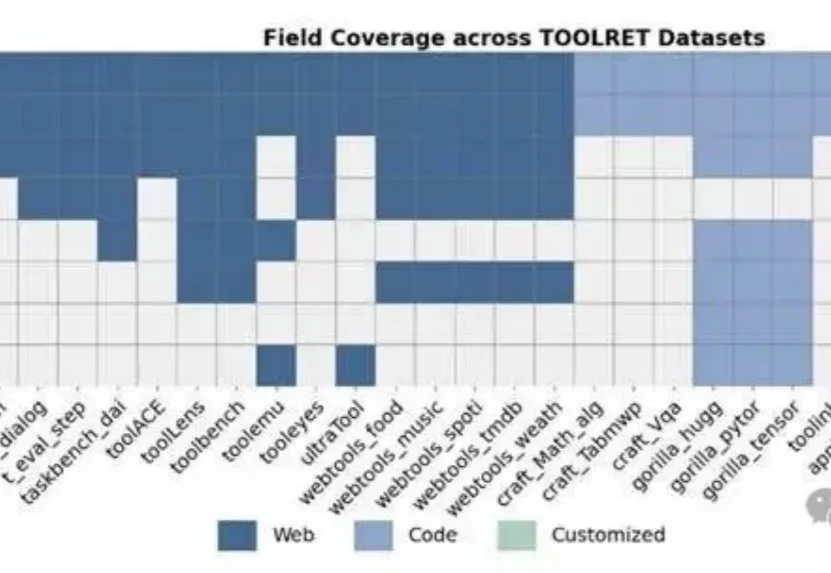
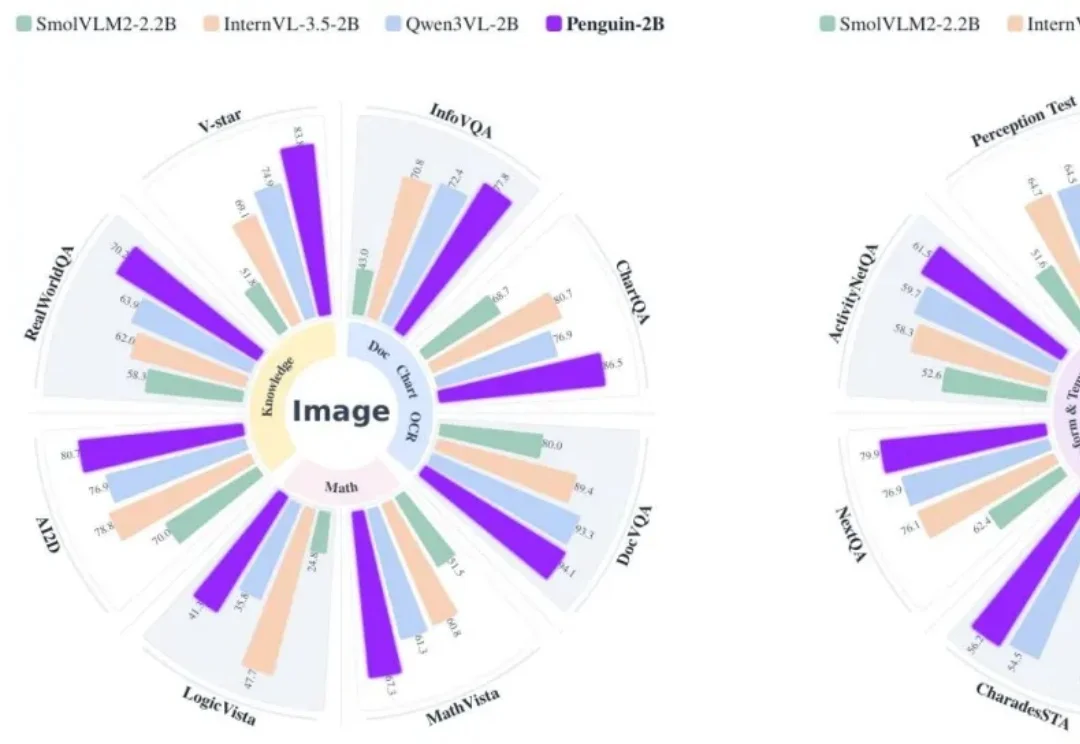
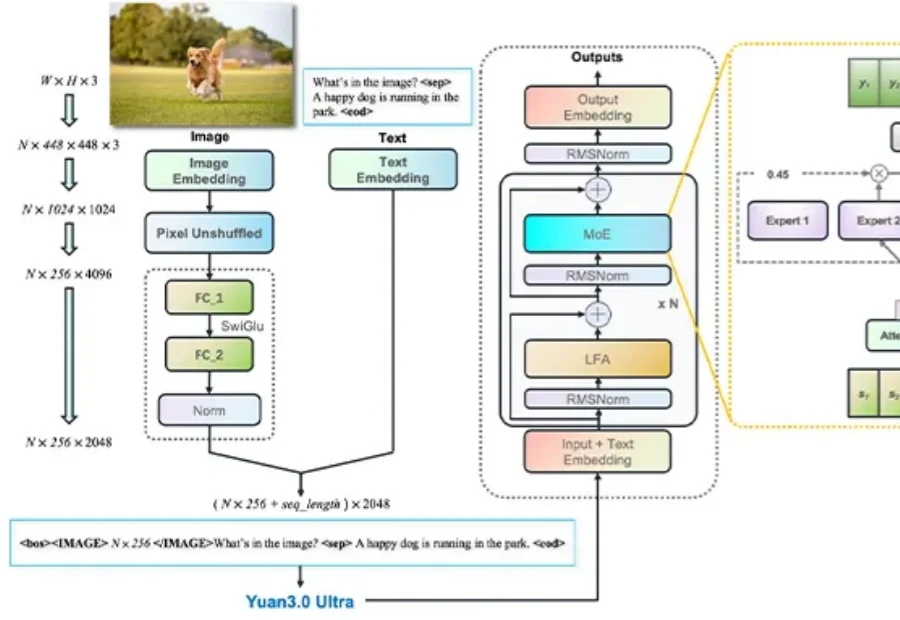
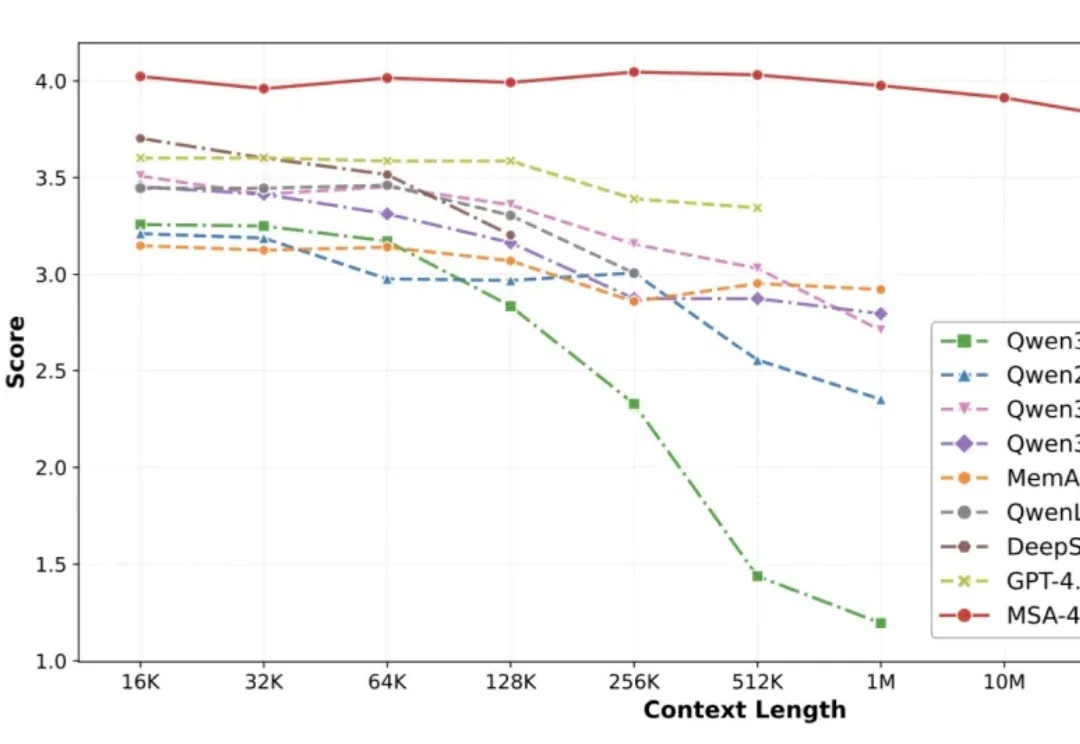
突破一亿Token极限:EverMind提出MSA架构,实现大模型高效端到端长时记忆人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。
来自主题: AI技术研报
9625 点击 2026-03-19 17:02